In diesem Artikel wird erläutert, wie Sie die Multi-Get-API von Elasticsearch verwenden, um mehrere JSON-Dokumente basierend auf ihren IDs abzurufen. Darüber hinaus können Sie mit Elasticsearch eine einzige Get-Abfrage verwenden, um die Dokumente nur anhand der Dokument-IDs aus Indizes abzurufen.
Lass uns erforschen.
Anforderungssyntax
Im Folgenden ist die Syntax für die Elasticsearch-Multi-Get-API aufgeführt:
GET /_mget
GET /
Die Multi-Get-API unterstützt mehrere Indizes, sodass Sie die Dokumente abrufen können, auch wenn sie sich nicht im selben Index befinden.
Die Anfrage unterstützt die folgenden Pfadparameter:
-
– Der Name des Indexes, aus dem die Dokumente abgerufen werden sollen, wie durch ihre IDs angegeben.
Sie können auch die anderen Abfrageparameter wie gezeigt angeben:
- Präferenz – Definiert den bevorzugten Knoten oder Shard.
- Echtzeit – Wenn auf „true“ gesetzt, wird die Operation in Echtzeit ausgeführt.
- Aktualisierung – Zwingt den Vorgang, die Ziel-Shards zu aktualisieren, bevor die angegebenen Dokumente abgerufen werden.
- Routing – Ein Wert, der verwendet wird, um die Vorgänge an einen bestimmten Shard weiterzuleiten.
- Store_fields – Ruft die in einem Index gespeicherten Dokumentfelder und nicht das Dokument ab.
- _Quelle – Ein boolescher Wert, der definiert, ob die Anfrage das Feld _source zurückgeben soll oder nicht.
Die Abfrage erfordert den Hauptteil, der die folgenden Werte enthält:
- Dokumente – Gibt die Dokumente an, die Sie abholen möchten. Darüber hinaus unterstützt dieser Abschnitt die folgenden Attribute:
- _Ich würde – Eindeutige ID des Zieldokuments.
- _Index – Der Index, der das Zieldokument enthält.
- Routing – Der Schlüssel für den primären Shard des Dokuments.
- _Quelle – Wenn wahr, schließt es alle Quellfelder ein; andernfalls schließt es sie aus.
- _gespeicherte_Felder – Die gespeicherten_Felder, die Sie einschließen möchten.
- IDs – Die IDs der Dokumente, die Sie abrufen möchten.
Beispiel 1: Mehrere Dokumente aus demselben Index abrufen
Das folgende Beispiel zeigt, wie Sie die Elasticsearch-Multi-Get-API verwenden, um die Dokumente mit bestimmten IDs aus dem Netflix-Index abzurufen:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: Reporting' -H 'Content-Type: application/json' -d'{
'Dokumente': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Die angegebene Anfrage sollte die Dokumente mit den angegebenen IDs aus dem Netflix-Index abrufen. Die resultierende Ausgabe sieht wie folgt aus:
{'Dokumente': [
{
'_index': 'Netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_Version 1,
'_seq_no': 0,
'_primary_term': 1,
'gefunden': wahr,
'_Quelle': {
'Dauer': '90 Minuten',
'listed_in': 'Dokumentationen',
'Land: Vereinigte Staaten',
'date_added': '25. September 2021',
'show_id': 's1',
'Direktor': 'Kirsten Johnson',
'release_year': 2020,
'Rating': 'PG-13',
'description': 'Während sich ihr Vater dem Ende seines Lebens nähert, inszeniert die Filmemacherin Kirsten Johnson seinen Tod auf einfallsreiche und komische Weise, um beiden zu helfen, sich dem Unvermeidlichen zu stellen.',
'type': 'Film',
'title': 'Dick Johnson ist tot'
}
},
{
'_index': 'Netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_Version 1,
'_seq_no': 12,
'_primary_term': 1,
'gefunden': wahr,
'_Quelle': {
'country': 'Deutschland, Tschechien',
'show_id': 's13',
'regisseur': 'Christian Schwochow',
'release_year': 2021,
'Rating': 'TV-MA',
'description': 'Nachdem der größte Teil ihrer Familie bei einem terroristischen Bombenanschlag ermordet wurde, wird eine junge Frau unwissentlich dazu verleitet, sich genau der Gruppe anzuschließen, die sie getötet hat.',
'type': 'Film',
'title': 'Ich bin Karl',
'Dauer': '127 Minuten',
'listed_in': 'Dramen, Internationale Filme',
'Besetzung': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23. September 2021'
}
}
]
}
Wir können die Anforderung auch vereinfachen, indem wir die Dokument-IDs in ein einfaches Array einfügen, wie im Folgenden gezeigt:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: Reporting' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Die vorherige Anfrage sollte eine ähnliche Aktion ausführen.
Beispiel 2: Holen Sie die Dokumente aus mehreren Indizes
Im folgenden Beispiel ruft die Anfrage wie gezeigt mehrere Dokumente aus verschiedenen Indizes ab:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: Reporting' -H 'Content-Type: application/json' -d'{
'Dokumente': [
{
'_index': 'Netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'Disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Die resultierende Ausgabe sieht wie folgt aus:

Beispiel 3: Bestimmte Felder ausschließen
Mit den Parametern source_include und source_exclude können wir bestimmte Felder aus einer bestimmten Anfrage ausschließen.
Ein Beispiel ist wie gezeigt:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: Reporting' -H 'Content-Type: application/json' -d'{
'Dokumente': [
{
'_index': 'Netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': false
},
{
'_index': 'Netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_Quelle': {
'enthalten': [ 'gelistet in', 'Veröffentlichungsjahr', 'Titel' ],
'ausschließen': [ 'Beschreibung', 'Typ', 'Hinzugefügtes Datum' ]
}
}
]
}'
Die gegebene Anfrage verwendet die Quelleneinschluss und -ausschluss, um anzugeben, welche Felder Sie in einem gegebenen Dokument abrufen möchten.
Die resultierende Ausgabe sieht wie folgt aus:
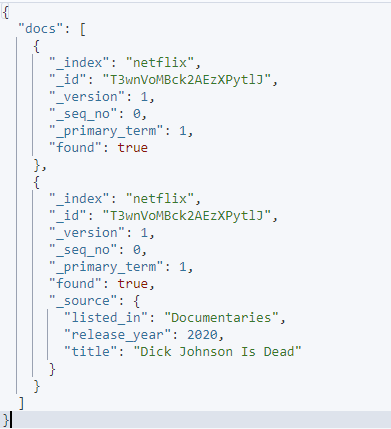
Fazit
In diesem Beitrag haben wir die Grundlagen der Arbeit mit der Elasticsearch Multi-Get-API besprochen, mit der Sie mehrere Dokumente aus verschiedenen Quellen basierend auf ihren IDs abrufen können. Fühlen Sie sich frei, die anderen Dokumente zu durchsuchen, um weitere Informationen zu erhalten.
Viel Spaß beim Codieren!