Beispiel 1: Ermitteln Sie die Position des Musters aus der Zeichenfolge mithilfe der Funktion Grep() in R
Um die Position des angegebenen Musters aus der Zeichenfolge zu extrahieren, wird die Funktion grep() von R verwendet.
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)Hier verwenden wir die Funktion grep(), bei der das „+i“-Muster als Argument angegeben wird, das innerhalb des String-Vektors abgeglichen werden soll. Wir legen die Zeichenvektoren fest, die vier Zeichenfolgen enthalten. Danach setzen wir das Argument „perl“ mit dem Wert TRUE, der angibt, dass R eine Perl-kompatible Bibliothek regulärer Ausdrücke verwendet, und der Parameter „value“ wird mit dem Wert „FALSE“ angegeben, der zum Abrufen der Indizes der Elemente verwendet wird im Vektor, die dem Muster entsprechen.
Die „+i“-Musterposition aus jeder Zeichenfolge von Vektorzeichen wird in der folgenden Ausgabe angezeigt:

Beispiel 2: Passen Sie das Muster mit der Funktion Gregexpr() in R an
Als nächstes rufen wir mit der Funktion gregexpr() die Indexposition zusammen mit der Länge der jeweiligen Zeichenfolge in R ab.
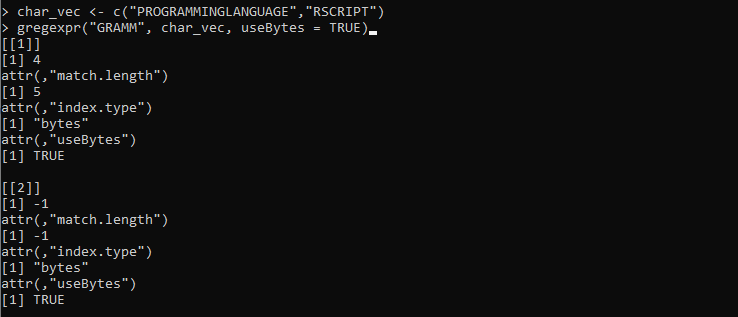
char_vec <- c('PROGRAMMINGLANGUAGE','RSCRIPT')
gregexpr('GRAMM', char_vec, useBytes = TRUE)
Hier setzen wir die Variable „char_vect“, in der die Strings mit unterschiedlichen Zeichen versehen werden. Danach definieren wir die Funktion gregexpr(), die das Zeichenfolgenmuster „GRAMM“ mit den Zeichenfolgen abgleicht, die in „char_vec“ gespeichert sind. Anschließend setzen wir den Parameter useBytes auf den Wert „TRUE“. Dieser Parameter gibt an, dass der Abgleich byteweise und nicht zeichenweise erfolgen soll.
Die folgende Ausgabe, die von der Funktion gregexpr() abgerufen wird, stellt die Indizes und die Länge beider Vektorzeichenfolgen dar:
Beispiel 3: Zählen Sie die Gesamtzahl der Zeichen in einer Zeichenfolge mithilfe der Nchar()-Funktion in R
Mit der Methode nchar(), die wir im Folgenden implementieren, können wir auch ermitteln, wie viele Zeichen in der Zeichenfolge enthalten sind:
Res <- nchar('Jedes Zeichen zählen')drucken(Res)
Hier rufen wir die Methode nchar() auf, die in der Variablen „Res“ festgelegt wird. Der Methode nchar() wird die lange Zeichenfolge bereitgestellt, die von der Methode nchar() gezählt wird und die Anzahl der Zählerzeichen in der angegebenen Zeichenfolge liefert. Anschließend übergeben wir die Variable „Res“ an die print()-Methode, um die Ergebnisse der nchar()-Methode anzuzeigen.
Das Ergebnis wird in der folgenden Ausgabe empfangen, die zeigt, dass die angegebene Zeichenfolge 20 Zeichen enthält:

Beispiel 4: Extrahieren Sie den Teilstring aus dem String mit der Funktion Substring() in R
Wir verwenden die Methode substring() mit den Argumenten „start“ und „stop“, um den spezifischen Teilstring aus dem String zu extrahieren.
str <- substring('MORGEN', 2, 4)print(str)
Hier haben wir eine „str“-Variable, in der die Methode substring() aufgerufen wird. Die Methode substring() verwendet die Zeichenfolge „MORNING“ als erstes Argument und den Wert „2“ als zweites Argument, was angibt, dass das zweite Zeichen aus der Zeichenfolge extrahiert werden soll, und der Wert des Arguments „4“ gibt dies an das vierte Zeichen soll extrahiert werden. Die Methode substring() extrahiert die Zeichen aus der Zeichenfolge zwischen der angegebenen Position.
Die folgende Ausgabe zeigt den extrahierten Teilstring an, der zwischen der zweiten und vierten Position im String liegt:

Beispiel 5: Verketten Sie die Zeichenfolge mit der Funktion Paste() in R
Die Funktion paste() in R wird auch zur String-Manipulation verwendet, die die angegebenen Strings durch Trennen der Trennzeichen verkettet.
msg1 <- „Inhalt“msg2 <- „Schreiben“
einfügen(msg1, msg2)
Hier geben wir die Zeichenfolgen für die Variablen „msg1“ bzw. „msg2“ an. Dann verwenden wir die Methode paste() von R, um die bereitgestellte Zeichenfolge zu einer einzelnen Zeichenfolge zu verketten. Die paste()-Methode verwendet die Zeichenfolgenvariable als Argument und gibt die einzelne Zeichenfolge mit dem Standardabstand zwischen den Zeichenfolgen zurück.
Bei der Ausführung der Methode paste() stellt die Ausgabe die einzelne Zeichenfolge mit dem darin enthaltenen Leerzeichen dar.

Beispiel 6: Ändern Sie den String mit der Funktion Substring() in R
Darüber hinaus können wir die Zeichenfolge auch aktualisieren, indem wir mit der Funktion substring() mithilfe des folgenden Skripts die Teilzeichenfolge oder ein beliebiges Zeichen zur Zeichenfolge hinzufügen:
str1 <- 'Helden'Teilzeichenfolge (str1, 5, 6) <- 'ic'
cat(' Geänderter String:', str1)
Wir legen die Zeichenfolge „Heroes“ innerhalb der Variablen „str1“ fest. Anschließend stellen wir die Methode substring() bereit, bei der „str1“ zusammen mit den Indexwerten „start“ und „stop“ des Teilstrings angegeben wird. Der Methode substring() wird der Teilstring „iz“ zugewiesen, der an der Position platziert wird, die innerhalb der Funktion für den angegebenen String angegeben ist. Danach verwenden wir die Funktion cat() von R, die den aktualisierten Stringwert darstellt.
Die Ausgabe, die den String anzeigt, wird mithilfe der Methode substring() mit dem neuen aktualisiert:

Beispiel 7: Formatieren Sie die Zeichenfolge mit der Funktion Format() in R
Der String-Manipulationsvorgang in R umfasst jedoch auch die entsprechende Formatierung des Strings. Dazu verwenden wir die Funktion format(), mit der die Zeichenfolge ausgerichtet und die Breite der spezifischen Zeichenfolge festgelegt werden kann.
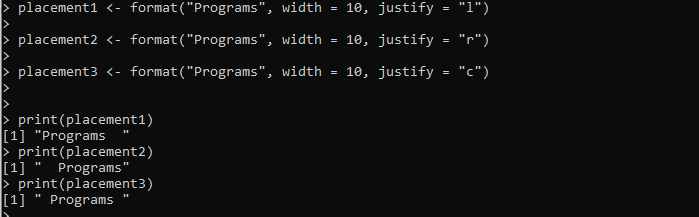
Platzierung1 <- Format('Programme', Breite = 10, Justify = 'l')Platzierung2 <- Format('Programme', Breite = 10, Justify = 'r')
Platzierung3 <- Format('Programme', Breite = 10, Justify = 'c')
drucken(Platzierung1)
drucken(Platzierung2)
drucken(Platzierung3)
Hier legen wir die Variable „placement1“ fest, die mit der format()-Methode bereitgestellt wird. Wir übergeben die zu formatierende Zeichenfolge „Programme“ an die Methode format(). Mit dem Argument „justify“ wird die Breite und die Ausrichtung der Zeichenfolge nach links festgelegt. Auf ähnliche Weise erstellen wir zwei weitere Variablen, „placement2“ und „placement2“, und wenden die format()-Methode an, um die bereitgestellte Zeichenfolge entsprechend zu formatieren.
Die Ausgabe zeigt drei Formatierungsstile für dieselbe Zeichenfolge im folgenden Bild an, einschließlich der linken, rechten und mittleren Ausrichtung:
Beispiel 8: Transformieren Sie die Zeichenfolge in R in Klein- und Großbuchstaben
Darüber hinaus können wir die Zeichenfolge mit den Funktionen tolower() und toupper() wie folgt in Klein- und Großbuchstaben umwandeln:
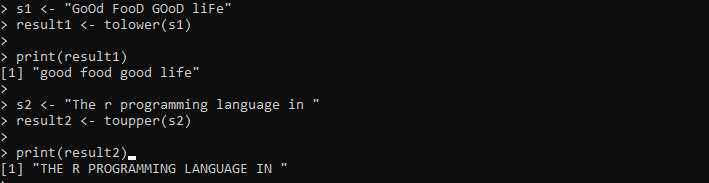
s1 <- „Gutes Essen, gutes Leben“result1 <- tolower(s1)
drucken(Ergebnis1)
s2 <- „Die r-Programmiersprache in“
result2 <- topper(s2)
drucken(Ergebnis2)
Hier stellen wir die Zeichenfolge bereit, die die Groß- und Kleinbuchstaben enthält. Danach wird die Zeichenfolge in der Variablen „s1“ gespeichert. Dann rufen wir die Methode tolower() auf und übergeben die darin enthaltene Zeichenfolge „s1“, um alle Zeichen in der Zeichenfolge in Kleinbuchstaben umzuwandeln. Dann drucken wir die Ergebnisse der tolower()-Methode aus, die in der Variablen „result1“ gespeichert ist. Als nächstes legen wir einen weiteren String in der Variablen „s2“ fest, der alle Zeichen in Kleinbuchstaben enthält. Wir wenden die toupper()-Methode auf diesen „s2“-String an, um den vorhandenen String in Großbuchstaben umzuwandeln.
Die Ausgabe zeigt beide Zeichenfolgen in der angegebenen Groß-/Kleinschreibung im folgenden Bild an:
Abschluss
Wir haben die verschiedenen Möglichkeiten kennengelernt, die Strings zu verwalten und zu analysieren, was als String-Manipulation bezeichnet wird. Wir haben die Position des Zeichens aus der Zeichenfolge extrahiert, die verschiedenen Zeichenfolgen verkettet und die Zeichenfolge in die angegebene Groß- und Kleinschreibung umgewandelt. Außerdem haben wir die Zeichenfolge formatiert, geändert und verschiedene andere Vorgänge ausgeführt, um die Zeichenfolge zu bearbeiten.