In diesem Leitfaden werden die Kreuzvalidierung und ihre Funktionsweise mit AWS Service erläutert.
Was ist Kreuzvalidierung?
Durch die Kreuzvalidierung können Entwickler verschiedene Modelle für maschinelles Lernen vergleichen und einen Eindruck davon bekommen, wie sie im wirklichen Leben funktionieren. Es hilft dem Benutzer herauszufinden, welches Modell für maschinelles Lernen (ML) oder Deep Learning (DL) für bestimmte Daten oder Szenarios besser funktioniert. Es gibt Situationen, in denen mehrere Modelle für einen Datensatz verwendet werden können. Hier verwenden Entwickler eine Kreuzvalidierung, um ein passendes Modell zu erhalten und optimierte Ergebnisse zu erhalten:
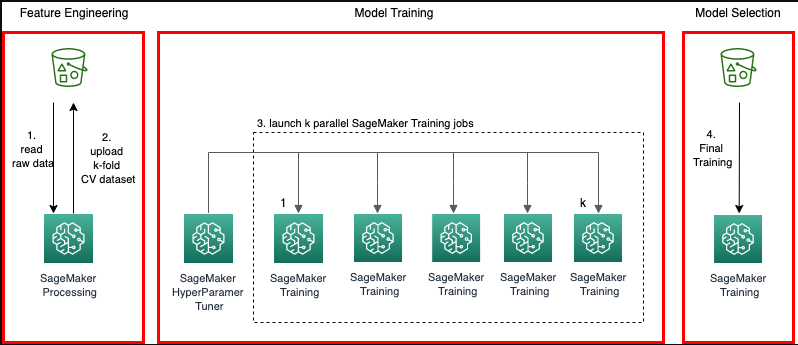
Wie funktioniert die Kreuzvalidierung?
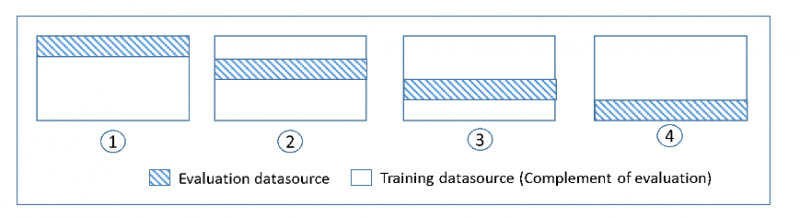
Um die ML-Modelle in einem Datensatz zu überprüfen, muss der Benutzer die Merkmale des Modells schätzen, was als Training des Algorithmus bezeichnet wird. Eine weitere zu überprüfende Sache ist die Bewertung des Modells, um herauszufinden, wie gut es funktioniert. Dies wird als Testen des Modells bezeichnet. Es ist keine gute Idee, das Modell anhand aller Daten zu testen. Wir verwenden jedoch 75 % der Daten für das Training und 25 % für Tests, um bessere Ergebnisse zu erzielen. Bei der Kreuzvalidierung werden alle 25 % der Daten Tests durchgeführt, um zu überprüfen, welcher Block die beste Leistung erbringt:
Was ist Amazon SageMaker?
Die Kreuzvalidierung in AWS kann mit dem Amazon SageMaker-Service durchgeführt werden, da dieser zum Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen konzipiert ist. Es hilft Datenwissenschaftlern und Entwicklern, Daten für die Erstellung effizienter ML- oder DL-Modelle vorzubereiten, indem es speziell entwickelte Funktionen zusammenführt. Diese Funktionen sind nützlich, um optimierte und genaue Modelle zu erstellen, die sich im Laufe der Zeit verbessern können:

Funktionen von Amazon SageMaker
Amazon SageMaker ist ein verwalteter Dienst und erfordert keine Verwaltung von ML-Umgebungen. Zum Trainieren und Erstellen von ML-Modellen sind viele Daten erforderlich, sodass eine gute Verbindung mit den Diensten Amazon S3 oder Amazon Redshift zur Datenerfassung besteht. Es kann schwierig sein, aus Rohdaten Informationen zu gewinnen, daher sind auch Funktionen zum Erstellen von Modellen erforderlich. Verwenden Sie dann die Daten, um Modelle zu trainieren, und führen Sie dann Tests mit jeweils 25 % der Daten durch, um bessere Ergebnisse/Vorhersagen zu erhalten:
Hier dreht sich alles um die Kreuzvalidierung in AWS.
Abschluss
Unter Kreuzvalidierung versteht man den Prozess, bei dem das optimale Modell für maschinelles Lernen oder Deep Learning für die Daten ermittelt wird, um bessere Ergebnisse zu erzielen. Für jeden 25-Prozent-Abschnitt der Daten werden Tests durchgeführt, um herauszufinden, welcher Block die maximale Ausgabe liefert und somit ein geeignetes Modell darstellt. AWS stellt den SageMaker-Service zur Verfügung, um Kreuzvalidierungen durchzuführen und Modelle für maschinelles Lernen in der Cloud zu erstellen. In diesem Leitfaden wurden der Kreuzvalidierungsprozess und seine Funktionsweise in AWS erläutert.