Pandas gewährt Ihnen Zugriff auf ein breites Spektrum an kritischen Aspekten und Anleitungen, die dazu dienen, Ihre Daten schnell auszuwerten. Wir nutzen den Prozess der Umwandlung der Pandas DataFrames in HTML-Tabellen. Die Entwickler und Benutzer müssen ihre Python-DataFrames in einen HTML-Quellcode integrieren. Sie verwenden diese Pandas-Erweiterung, um ihre Daten zu diesem Zweck mithilfe der Pandas-to-HTML-Technik mühelos in eine HTML-Datei zu verschieben. Um die Methodik zu erklären, verwenden wir das Tool „Spyder“ für die Implementierung, um es Schritt für Schritt mit jeder Implementierung leicht verständlich zu machen.
Wenn wir eine lokale HTML-Datei in Pandas parsen möchten, verwenden wir den Namen und die Textfacetten des Tags. In Verbindung mit dem Code für das Tag-ul aus der Datei können wir den Titel und Inhalt des Tags anpassen. Wenn wir die HTML-Datei aus der URL in Pandas erhalten möchten, sollten wir einige Schritte ausführen, die den Web-URL-Parameter enthalten, um die Scanfunktion aufzurufen. Dann verweisen wir auf die Variablen, die das Durchsuchen von Datenbankobjekten ermöglichen, und lesen das Innere der gesamten URL in die Datenvariable ein, um den Code auszuführen, damit die Daten im HTML-Format gedruckt werden.
Syntax für Pandas zu HTML:

Beispiel: Zeigen Sie das Rendering eines Pandas DataFrame in HTML-Code und Tabelle an
Auf einer HTML-Webseite kann Pandas in Python einen Pandas DataFrame in eine HTML-Tabelle umwandeln. Ein Pandas DataFrame wird mit der Methode „pandas.DataFrame.to html()“ ausgeführt. Schauen wir uns unser Beispiel an und besprechen das Verfahren zum Umwandeln unseres Python-Datenrahmens in HTML-Quellcode. Um dies zu erreichen, müssen wir zuerst den DataFrame entwerfen, der letztendlich in HTML gerendert wird. Um die Pandas-Philosophie auf unseren Python-Code anzuwenden, importieren wir konsequent die Pandas-Bibliothek als „pd“.
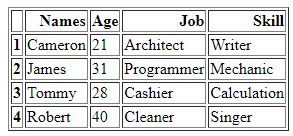
Unser DataFrame „Mitglieder“ enthält die Wörterbücher, die sich auf die Informationen des Mitglieds beziehen, zusammen mit den vier deklarierten Variablen „Name“, „Alter“, „Job“ und „Fähigkeit“. Die erste Zeile speichert die Daten als „Cameron“ für „Namen“, „21“ für „Alter“, „Architekt“ für „Job“ und „Writer“ für „Fähigkeiten“. Auf diese Weise ist die zweite Zeile der initialisierten DataFrame-Werte, die wir zuweisen, „James“, „31“, „Programmierer“ und „Mechaniker“ in ihren jeweiligen Spalten. Auf diese Weise enthält das andere Wörterbuch „Tommy“, „28“, „Kassierer“ und „Kalkulation“ in seinen Daten. Und die letzte Zeile, die wir unserem DataFrame zuweisen, enthält die Daten „Robert“ als Wert für „Names“, „40“ als zugewiesenen Wert für „Alter“, „Cleaner“ als „Job“ und „Singer“ als a 'Können'.
Im Folgenden weisen wir die Daten für unseren DataFrame zu und stellen ihnen auch den „Index“-Bereich von „1“ bis „4“ zur Verfügung, da der DataFrame vier Zeilen haben könnte. Danach verwenden wir die Funktion „pd.dataframe()“, um die Daten zusammen mit den Indexnummern zusammenzuführen. Zuletzt verwenden wir die Funktion „print()“, um unseren DataFrame anzuzeigen.
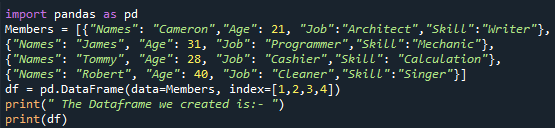
Jetzt können wir die Anzeige unserer DataFrame-„Mitglieder“ sehen, die wir erstellt haben. Hier können wir sehen, dass es sich um die einfache Anzeige unseres DataFrames handelt, den wir in eine HTML-Quelle konvertieren. Es hat einfach vier Spalten – „Namen“, „Alter“, „Job“ und „Skill“ – mit all den ähnlichen Daten, die wir unserem DataFrame im Code zuweisen. Seine Zeilen haben Indexnummern wie „1“, „2“, „3“ und „4“. In diesem Schritt sehen wir, dass wir unsere DataFrame „Mitglieder“ erstellen. Nachdem wir unseren DataFrame erstellt haben, fahren wir mit der weiteren Implementierung fort.
In diesem Schritt sehen wir nun, wie wir unsere DataFrame-„Mitglieder“ in einen HTML-Code umwandeln können. Es ist an der Zeit, die Trickserei der DataFrame to html()-Methode von Python zu verstehen, die den DataFrame in HTML umwandelt. Die html()-Funktion ändert den gesamten DataFrame, was dazu führt, dass jede Zeile im DataFrame eine eindeutige Sequenz in der HTML-Tabelle ist. Dazu deklarieren wir die Variable „html“ und speichern sie mit der Funktion „df.to_html()“, um unseren gesamten DataFrame in einen Html-Code umzuwandeln. Nach der Implementierung der Funktion „df.to_html()“ wenden wir die Funktion „print()“ auf das Verzeichnis „html“ an.

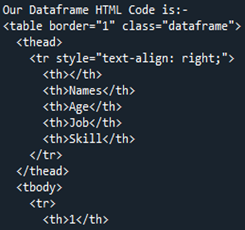
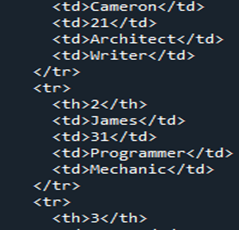
Nun sehen wir uns den HTML-Code an, der von Pandas DataFrame „Members“ konvertiert wird. Auf diese Weise können Sie jeden unserer DataFrames in einen HTML-Quellcode konvertieren, der den gesamten DataFrame im HTML-Code beschreibt, einschließlich aller Tags mit Tabellenrahmen als „1“. Die Spaltennamen werden unter „“ als Tabellenkopf des HTML-Elements eingekapselt, während der gesamte DataFrame in ein HTML-Element „ Da es in unserem DataFrame vier Zeilen gab, wird „ Jetzt speichern wir unseren HTML-Code im aktuellen laufenden Verzeichnis als „Signal“ zusammen mit der Erweiterung „.html“. Wir verwenden die Funktion „open()“, um den Dateispeicherortnamen als „file=open(“signal.html“, „w“)“ zu ermitteln. Da das Ortsschlüsselwort „w“ es speichert, um die Datei anzuzeigen und in HTML-Form offenzulegen, verwenden wir die Funktion „.write()“ und beenden unseren Pandas-Code zusammen mit der Funktion „close()“ auf der Datei. Wir sprechen über den Großteil des einfacheren Falls, den wir verwenden, um es zusammen mit der Dateierweiterung „.html“ zu speichern, die es in HTML umwandelt und die Schnittstelle des Browsers im selben Verzeichnis bereitstellt. Nach der Konvertierung unseres DataFrame „Members“ in HTML erhalten wir unseren HTML-Code, den wir zuerst im selben Verzeichnis speichern. Wenn wir unseren HTML-Quellcode erhalten, können wir ihn zusammen mit der Weberweiterung öffnen, indem wir die HTML-Quelldatei mit dem Browser öffnen. Wir sehen, dass die Ausgabe als HTML-Tabelle auf der Browserseite angezeigt wird. Wie wir in der Tabellenausgabe sehen können, enthält sie eine Rahmengröße von „1“ und keinen Zellabstand entlang ihnen. Die Tabelle zeigt fünf Spalten. Davon sind vier Spaltennamen „Namen“, „Alter“, „Job“ und „Fertigkeit“. Wenn wir über die Indexnummer „1“ sprechen, hat sie „Cameron“ in Spalte „Namen“, „21“ in „Alter“, „Architekt“ in „Job“ und „Writer“ in „Skill“. Die Indexnummer „2“ in der Tabelle zeigt „James“ in „Namen“, „31“ in „Alter“, „Programmierer“ in „Job“ und „Mechaniker“ in „Fähigkeiten“. Der „3“-Index der Spalte „Namen“ zeigt „Tommy“, „28“ in „Alter“, „Kassierer“ in „Job“ und „Kalkulation“ in Spalte „Skill“ auf der Browserseite. Der „4“-Index der letzten Zeile in der Tabelle zeigt „Robert“ in „Namen“, „40“ in „Alter“, „Reinigungskraft“ in „Beruf“ und „Sänger“ in „Fähigkeiten“. Um unseren DataFrame in den HTML-Quellcode für diesen Artikel umzuwandeln, haben wir ihn zunächst mit dem Namen „Mitglieder“ zusammengestellt. Beim Rendern eines DataFrames in einen HTML-Code verwenden wir die Funktion „html = df.to html()“. Beim Anzeigen einer HTML-Tabelle verwenden wir das Verzeichnis „file = open(“signal.html“, „w“)“ und den Dateispeicherort „signal.html“, die im selben Verzeichnis gespeichert sind. Dadurch konnten wir unseren Pandas DataFrame in eine HTML-Quellcodedatei umwandeln und mit einer Tabelle anzeigen.“ geändert wird. Zusätzlich wird jede Zeile des DataFrames zusammen mit dem Tag „
“ in der HTML-Tabelle in eine Zeile umgewandelt. Das „“ verwendet etwas von „CSS“ zusammen mit dem Tag „ “, das die Tabellenzeile beschreibt.
“ zusammen mit den schließenden Tags ebenfalls viermal verwendet. Wie wir in HTML wissen, muss es sowohl öffnende als auch schließende Tags in ihrem jeweiligen HTML-Code haben. Alle Daten oder DataFrame sind zwischen dem öffnenden „ “ und „
“ und dem schließenden Tag eingeschlossen. Der Rest des gesamten HTML-Codes enthält die gleichen Daten wie im DataFrame, er wird nur in einfachen HTML-Quellcode konvertiert, zusammen mit den erforderlichen Tags, die zum Erstellen einer Tabelle erforderlich sind.

Fazit