Als Datenbankadministratoren müssen wir uns mit den Tools und Methoden zur Verbesserung der Datenbankleistung beschäftigen.
In PostgreSQL haben wir Zugriff auf den Befehl EXPLAIN ANALYZE, mit dem wir den Ausführungsplan und die Leistung einer bestimmten Datenbankabfrage analysieren können. Der Befehl gibt detaillierte Informationen darüber zurück, wie die Datenbank-Engine die Abfrage verarbeitet. Dazu gehören die Reihenfolge der durchgeführten Vorgänge, die geschätzten Abfragekosten, der Ausführungszeitpunkt und mehr.
Mithilfe dieser Informationen können wir dann die Datenbankabfragen identifizieren sowie potenzielle Leistungsengpässe identifizieren und beheben.
In diesem Tutorial wird erläutert, wie Sie den Befehl EXPLAIN ANALYZE in PostgreSQL verwenden, um die Abfrageleistung anzuzeigen und zu optimieren.
PostgreSQL EXPLAIN ANALYZE
Der Befehl ist ziemlich einfach. Zuerst müssen wir den Befehl EXPLAIN ANALYZE am Anfang der Abfrage voranstellen, die wir analysieren möchten.
Die Befehlssyntax lautet wie folgt:
EXPLAIN ANALYZESobald Sie den Befehl ausführen, gibt PostgreSQL eine detaillierte Ausgabe über die bereitgestellte Abfrage zurück.
Verstehen der EXPLAIN ANALYZE-Abfrageausgabe
Wie bereits erwähnt, generiert PostgreSQL nach der Ausführung des Befehls EXPLAIN ANALYZE einen detaillierten Bericht des Abfrageplans und der Ausführungsstatistiken.
Die Ausgabe besteht aus einer Reihe von Spalten, die nützliche Informationen enthalten. Die resultierenden Spalten lauten wie folgt mit ihrer jeweiligen Bedeutung:
ABFRAGEPLAN – In dieser Spalte wird der Ausführungsplan der angegebenen Abfrage angezeigt. Der Ausführungsplan bezieht sich auf eine Abfolge von Vorgängen, die das Datenbankmodul ausführt, um die Abfrage erfolgreich abzuschließen.
PLANEN – Die zweite Spalte ist die Spalte PLAN. Diese enthält eine Textdarstellung jedes Vorgangs oder Schritts im Ausführungsplan. Auch hier ist jede Operation eingerückt, um die Hierarchie der Operationen anzuzeigen.
GESAMTKOSTEN – Die Spalte „Gesamtkosten“ stellt die geschätzten Gesamtkosten der Abfrage dar. Die Kosten beziehen sich auf ein relatives Maß, das der Datenbankabfrageplaner verwendet, um den optimalen Ausführungsplan zu bestimmen.
TATSÄCHLICHE REIHEN – Diese Spalte zeigt die genaue Anzahl der Zeilen, die bei jedem Schritt der Abfrageausführung verarbeitet werden.
GENAUE UHRZEIT – In dieser Spalte wird die tatsächlich von jedem Vorgang benötigte Zeit angezeigt, die sowohl die Ausführungszeit des Vorgangs als auch die für Ressourcen aufgewendete Zeit umfasst.
PLANUNGSZEIT – In dieser Spalte wird die Zeit angezeigt, die der Abfrageplaner benötigt, um einen Ausführungsplan zu erstellen. Darin enthalten ist die Gesamtzeit der Abfrageoptimierung und der Plangenerierung.
AUSFÜHRUNGSZEIT – In dieser Spalte wird die Gesamtzeit zum Ausführen der Abfrage angezeigt. Dazu gehört auch die Zeit, die für die Planung und die Ausführung der Abfrage aufgewendet wird.
PostgreSQL EXPLAIN ANALYZE-Beispiel
Schauen wir uns einige grundlegende Beispiele für die Verwendung der EXPLAIN ANALYZE-Anweisung an.
Beispiel 1: Select-Anweisung
Lassen Sie uns die EXPLAIN ANALYZE-Anweisung verwenden, um die Ausführung einer einfachen Select-Anweisung in PostgreSQL zu zeigen.
Sobald wir die vorherige Anweisung ausführen, sollten wir eine Ausgabe wie folgt erhalten:
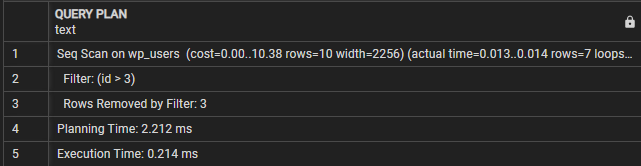
ABFRAGEPLAN-------------------------------------------------- -----------------
Seq Scan auf wp_users (Kosten=0,00..10,38 Zeilen=10, Breite=2256) (tatsächliche Zeit=0,009..0,010 Zeilen=7 Schleifen=1)
Filter: (id > 3)
Durch Filter entfernte Zeilen: 3
Planungszeit: 0,995 ms
Ausführungszeit: 0,021 ms
(5 Reihen)
In diesem Fall können wir sehen, dass der Abschnitt „Abfrageplan“ angibt, dass die Abfrage einen sequentiellen Scan für die Tabelle „wp_users“ durchführt. Die Filterzeile bezeichnet die Bedingung, die zum Filtern der resultierenden Zeilen verwendet wird.
Dann sehen wir „Vom Filter entfernte Zeilen“, die die Anzahl der Zeilen anzeigen, die durch die Filterbedingung eliminiert wurden.
Schließlich zeigt die Ausführungszeit die Gesamtausführungszeit der Abfrage. In diesem Fall dauert die Abfrage 0,021 ms.
Beispiel 2: Analyse eines Joins
Nehmen wir eine komplexere Abfrage, die einen SQL-Join beinhaltet. Hierzu nutzen wir die Beispieldatenbank Pagila. Sie können die Beispieldatenbank zu Demonstrationszwecken herunterladen und auf Ihrem Computer installieren.
Wir können einen einfachen Join ausführen, wie im Folgenden gezeigt:
erklären, analysieren SELECT f.title, c.nameVON film f
JOIN film_category fc ON f.film_id = fc.film_id
JOIN Kategorie c ON fc.category_id = c.category_id;
Sobald wir die angegebene Abfrage ausführen, sollten wir die Ausgabe wie folgt sehen:
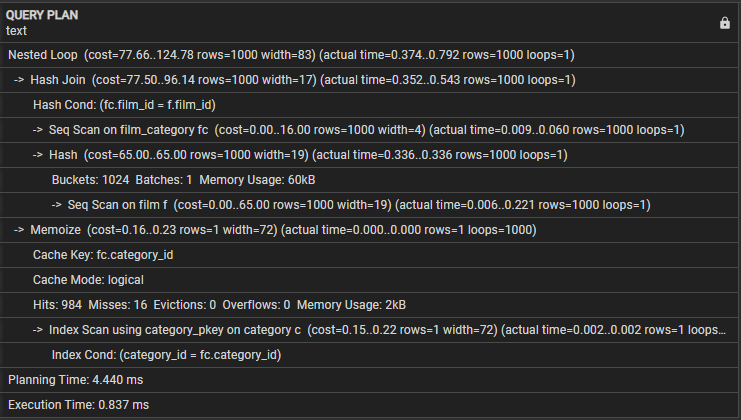
Lassen Sie uns den folgenden Abfrageplan untersuchen:
- Nested Loop – Dies zeigt an, dass der Join eine Nested-Loop-Join-Strategie verwendet.
- Hash-Join – Diese Operation verbindet die film_category- und die Filmtabellen mithilfe eines Hash-Join-Algorithmus. Dieser Vorgang kostet 77,50 und umfasst schätzungsweise 1000 Zeilen. Allerdings dauert dieser Vorgang tatsächlich 0,254 bis 0,439 Millisekunden und es werden 1000 Zeilen abgerufen.
- Hash Cond – Dies gibt an, dass die Join-Bedingung einen Hash-Join verwendet, um die Spalten „film_id“ und „film_category“ in den Filmtabellen abzugleichen.
- Seq Scan auf film_category – Dieser Vorgang führt einen sequentiellen Scan auf der Tabelle film_category mit einem Kostenaufwand von 16,00 und geschätzten 1000 Zeilen durch. Die tatsächliche Zeit, die für diesen Vorgang benötigt wird, beträgt 0,008 bis 0,056 Millisekunden und es werden 1000 Zeilen abgerufen.
- Seq Scan auf Film – Die Abfrage führt einen sequentiellen Scan auf der Filmtabelle mit den resultierenden geschätzten und tatsächlichen Kosten und Zeilen in diesem Vorgang durch.
- Memoize – Dieser Vorgang speichert die Ergebnisse der Verknüpfung zwischen film_category und Filmtabellen für die spätere Verwendung zwischen.
- Cache-Schlüssel – Dies zeigt an, dass der Cache-Schlüssel, der für die Speicherung verwendet wird, auf der Spalte „category_id“ von „film_category“ basiert.
- Cache-Modus – Dies zeigt an, dass die Abfrage den logischen Cache-Modus verwendet.
- Treffer, Fehlschläge, Räumungen, Überläufe – Die drei Zeilen liefern Statistiken über den Cache, die Anzahl der Treffer, Fehlschläge, Räumungen und Überläufe während der Ausführung. Dieser Block umfasst auch die Speichernutzung während der Abfrageausführung.
- Index-Scan mit „category_pkey“ – Dies zeigt den Vorgang, der einen Index-Scan für die Kategorietabelle mithilfe des Primärschlüsselindex durchführt.
- Indexbedingung – Dies zeigt, dass der Indexscan auf der Bedingung basiert, die der Spalte „category_id“ in der Kategorietabelle entspricht.
- Planungszeit – Diese Zeile zeigt die für die Abfrageplanung benötigte Zeit an, die 3,005 Millisekunden beträgt.
- Ausführungszeit – Schließlich zeigt diese Zeile die Gesamtausführungszeit der Abfrage, die 0,745 Millisekunden beträgt.
Hier hast du es! Eine detaillierte Information zur Ausführung eines einfachen Joins in PostgreSQL.
Abschluss
Sie haben die Leistungsfähigkeit und Verwendung der EXPLAIN ANALYZE-Anweisung in PostgreSQL entdeckt. Die EXPLAIN ANALYZE-Anweisung ist ein leistungsstarkes Tool zur Abfrageanalyse und -optimierung. Verwenden Sie dieses Tool, um effiziente und weniger ressourcenintensive Abfragen zu erstellen.