6.1 Einführung
Es gibt zwei Arten moderner Allzweckcomputer: CISC und RISC. CISC steht für Complex Instruction Set Computer. RISK steht für Reduced Instruction Set Computer. Die 6502- oder 6510-Mikroprozessoren, wie sie für den Commodore-64-Computer gelten, ähneln eher der RISC-Architektur als einer CISC-Architektur.
RISC-Computer verfügen im Allgemeinen über kürzere Assembler-Anweisungen (bezogen auf die Anzahl der Bytes) im Vergleich zu CISC-Computern.
Notiz : Unabhängig davon, ob es sich um CISC, RISC oder einen alten Computer handelt, beginnt ein Peripheriegerät an einem internen Anschluss und führt über einen externen Anschluss an der vertikalen Oberfläche der Systemeinheit (Basiseinheit) des Computers zum externen Gerät.
Eine typische Anweisung eines CISC-Computers besteht darin, mehrere kurze Assembler-Anweisungen zu einer längeren Assembler-Anweisung zusammenzufügen, wodurch die resultierende Anweisung komplex wird. Insbesondere lädt ein CISC-Computer die Operanden aus dem Speicher in die Mikroprozessorregister, führt eine Operation aus und speichert das Ergebnis dann zurück im Speicher, alles in einem Befehl. Andererseits sind dies mindestens drei Anweisungen (kurz) für den RISC-Computer.
Es gibt zwei beliebte Serien von CISC-Computern: die Intel-Mikroprozessor-Computer und die AMD-Mikroprozessor-Computer. AMD steht für Advanced Micro Devices; Es handelt sich um ein Unternehmen, das Halbleiter herstellt. Die Intel-Mikroprozessorserien sind in der Reihenfolge ihrer Entwicklung 8086, 8088, 80186, 80286, 80386, 80486, Pentium, Core, i-Serie, Celeron und Xeon. Die Assembler-Anweisungen für die frühen Intel-Mikroprozessoren wie 8086 und 8088 sind nicht sehr komplex. Allerdings sind sie für die neuen Mikroprozessoren aufwändig. Die aktuellen AMD-Mikroprozessoren für die CISC-Serie sind Ryzen, Opteron, Athlon, Turion, Phenom und Sempron. Die Mikroprozessoren von Intel und AMD werden als x86-Mikroprozessoren bezeichnet.
ARM steht für Advanced RISC Machine. Die ARM-Architekturen definieren eine Familie von RISC-Prozessoren, die für den Einsatz in einer Vielzahl von Anwendungen geeignet sind. Während viele Intel- und AMD-Mikroprozessoren in Desktop-Personalcomputern verwendet werden, dienen viele ARM-Prozessoren als eingebettete Prozessoren in sicherheitskritischen Systemen wie Antiblockiersystemen für Kraftfahrzeuge und als Allzweckprozessoren in Smartwatches, tragbaren Telefonen, Tablets und Laptops . Obwohl beide Arten von Mikroprozessoren in kleinen und großen Geräten zu finden sind, sind RISC-Mikroprozessoren eher in kleinen als in großen Geräten zu finden.
Computerwort
Wenn ein Computer als Computer mit 32-Bit-Worten bezeichnet wird, bedeutet dies, dass die Informationen in Form von 32-Bit-Binärcodes im inneren Teil der Hauptplatine gespeichert, übertragen und manipuliert werden. Dies bedeutet auch, dass die Allzweckregister im Mikroprozessor des Computers 32 Bit breit sind. Die A-, X- und Y-Register des 6502-Mikroprozessors sind Allzweckregister. Sie sind acht Bit breit und daher ist der Commodore-64-Computer ein Acht-Bit-Wortcomputer.
Einige Vokabeln
X86-Computer
Die Bedeutungen von Byte, Wort, Doppelwort, Quadwort und Doppelquadwort sind für x86-Computer wie folgt:
- Byte : 8 Bit
- Wort : 16 Bit
- Doppelwort : 32 Bit
- Quadword : 64 Bit
- Doppeltes Quadwort : 128 Bit
ARM-Computer
Die Bedeutung von Byte, Halbwort, Wort und Doppelwort ist für die ARM-Computer wie folgt:
- Byte : 8 Bit
- Werde zur Hälfte : 16 Bit
- Wort : 32 Bit
- Doppelwort : 64 Bit
Die Unterschiede und Ähnlichkeiten zwischen den x86- und ARM-Namen (und -Werten) sollten beachtet werden.
Notiz : Die Vorzeichen-Ganzzahlen sind bei beiden Computertypen Zweierkomplemente.
Speicherort
Beim Commodore-64-Computer besteht ein Speicherort normalerweise aus einem Byte, kann aber gelegentlich auch aus zwei aufeinanderfolgenden Bytes bestehen, wenn man die Zeiger berücksichtigt (indirekte Adressierung). Bei einem modernen x86-Computer beträgt ein Speicherplatz 16 aufeinanderfolgende Bytes, wenn es um ein Doppelquadwort mit 16 Bytes (128 Bit) geht, 8 aufeinanderfolgende Bytes, wenn es um ein Quadwort mit 8 Bytes (64 Bits) geht, und 4 aufeinanderfolgende Bytes, wenn es um ein Doppelwort mit 8 Bytes (64 Bits) geht 4 Bytes (32 Bits), 2 aufeinanderfolgende Bytes bei der Verarbeitung eines Wortes mit 2 Bytes (16 Bits) und 1 Byte bei der Verarbeitung eines Bytes (8 Bits). Bei einem modernen ARM-Computer beträgt ein Speicherplatz 8 aufeinanderfolgende Bytes, wenn es um ein Doppelwort von 8 Bytes (64 Bits) geht, 4 aufeinanderfolgende Bytes, wenn es um ein Wort von 4 Bytes (32 Bits) geht, und 2 aufeinanderfolgende Bytes, wenn es um ein Halbwort geht von 2 Bytes (16 Bits) und 1 Byte, wenn es sich um ein Byte (8 Bits) handelt.
In diesem Kapitel wird erläutert, was die CISC- und RISC-Architekturen gemeinsam haben und worin ihre Unterschiede bestehen. Dies erfolgt im Vergleich mit dem 6502 µP und dem Commodore-64-Computer, wo es anwendbar ist.
6.2 Motherboard-Blockdiagramm eines modernen PCs
PC steht für Personal Computer. Das Folgende ist ein allgemeines Grundblockdiagramm für ein modernes Motherboard mit einem einzelnen Mikroprozessor für einen Personalcomputer. Es handelt sich um ein CISC- oder RISC-Motherboard.
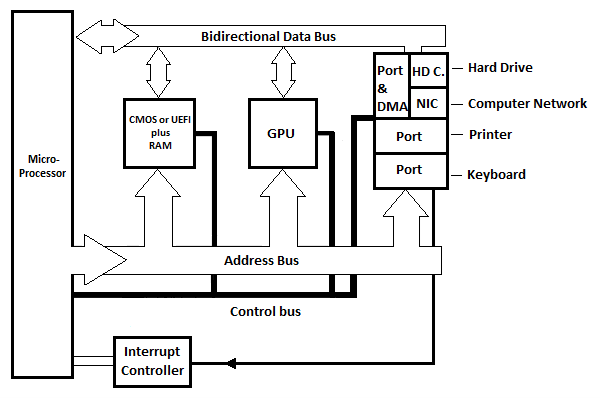
Abb. 6.21 Grundlegendes Motherboard-Blockdiagramm eines modernen PCs
Im Diagramm sind drei interne Ports dargestellt, in der Praxis gibt es jedoch noch mehr. Jeder Port verfügt über ein Register, das als Port selbst betrachtet werden kann. Jeder Portschaltkreis verfügt über mindestens ein weiteres Register, das als „Statusregister“ bezeichnet werden kann. Das Statusregister gibt den Port des Programms an, das das Interrupt-Signal an den Mikroprozessor sendet. Es gibt eine Interrupt-Controller-Schaltung (nicht gezeigt), die zwischen den verschiedenen Interrupt-Leitungen von den verschiedenen Ports unterscheidet und nur wenige Leitungen zum µP hat.
HD.C im Diagramm steht für Hard Drive Card. NIC steht für Network Interface Card. Die Festplattenkarte (Schaltkreis) ist mit der Festplatte verbunden, die sich in der Basiseinheit (Systemeinheit) des modernen Computers befindet. Die Netzwerkschnittstellenkarte (Schaltung) ist über ein externes Kabel mit einem anderen Computer verbunden. Im Diagramm sind ein Port und ein DMA (siehe folgende Abbildung) zu sehen, die mit der Festplattenkarte und/oder der Netzwerkschnittstellenkarte verbunden sind. DMA steht für Direct Memory Access.
Erinnern Sie sich aus dem Kapitel über den Commodore-64-Computer daran, dass zum Senden der Bytes aus dem Speicher an das Festplattenlaufwerk oder einen anderen Computer jedes Byte in ein Register im Mikroprozessor kopiert werden muss, bevor es in den entsprechenden internen Port kopiert wird, und zwar automatisch zum Gerät. Um die Bytes vom Festplattenlaufwerk oder einem anderen Computer in den Speicher zu empfangen, muss jedes Byte vom entsprechenden internen Portregister in ein Mikroprozessorregister kopiert werden, bevor es in den Speicher kopiert wird. Dies dauert normalerweise lange, wenn die Anzahl der Bytes im Stream groß ist. Die Lösung für eine schnelle Übertragung ist die Verwendung von Direct Memory Access (Schaltkreis) ohne Umweg über den Mikroprozessor.
Die DMA-Schaltung befindet sich zwischen dem Port und der Festplatte. C oder NIC. Beim direkten Speicherzugriff der DMA-Schaltung erfolgt die Übertragung großer Byteströme direkt zwischen der DMA-Schaltung und dem Speicher (RAM), ohne dass der Mikroprozessor weiterhin beteiligt sein muss. Der DMA verwendet den Adressbus und den Datenbus anstelle von µP. Die Gesamtdauer der Übertragung ist kürzer als bei Verwendung des µP-Hard. Sowohl HD C als auch NIC verwenden den DMA, wenn sie einen großen Datenstrom (Bytes) zur Übertragung mit dem RAM (dem Speicher) haben.
GPU steht für Graphics Processing Unit. Dieser Block auf der Hauptplatine ist dafür verantwortlich, den Text und die bewegten oder unbewegten Bilder an den Bildschirm zu senden.
Bei modernen Computern (PCs) gibt es keinen Read Only Memory (ROM). Es gibt jedoch das BIOS oder UEFI, bei dem es sich um eine Art nichtflüchtigen RAM handelt. Die Informationen im BIOS werden tatsächlich von einer Batterie aufrechterhalten. Die Batterie sorgt auch tatsächlich dafür, dass der Timer die richtige Uhrzeit und das richtige Datum für den Computer einhält. UEFI wurde nach dem BIOS erfunden und hat das BIOS ersetzt, obwohl das BIOS in modernen PCs immer noch sehr relevant ist. Wir werden später mehr darüber besprechen!
In modernen PCs sind die Adress- und Datenbusse zwischen dem µP und den internen Port-Schaltkreisen (und dem Speicher) keine parallelen Busse. Dabei handelt es sich um serielle Busse, die zwei Leiter für die Übertragung in die eine Richtung und zwei weitere Leiter für die Übertragung in die entgegengesetzte Richtung benötigen. Dies bedeutet beispielsweise, dass 32 Bits in Reihe (ein Bit nach dem anderen) in beide Richtungen gesendet werden können.
Erfolgt die serielle Übertragung nur in eine Richtung mit zwei Leitern (zwei Leitungen), spricht man von Halbduplex. Erfolgt die serielle Übertragung in beide Richtungen mit vier Leitern, einem Paar in jede Richtung, spricht man von Vollduplex.
Der gesamte Speicher des modernen Computers besteht immer noch aus einer Reihe von Byte-Speicherplätzen: acht Bits pro Byte. Ein moderner Computer verfügt über einen Speicherplatz von mindestens 4 Gigabyte = 4 x 210 x 2 10 x 2 10 = 4 x 1.073.741.824 10 Bytes = 4 x 1024 10/sub> x 1024 10 x 1024 10 = 4 x 1.073.741.824 10 .
Notiz : Obwohl auf dem vorherigen Motherboard kein Timer-Schaltkreis angezeigt wird, verfügen alle modernen Motherboards über Timer-Schaltkreise.
6.3 Die Grundlagen der x64-Computerarchitektur
6.31 Der x64-Registersatz
Der 64-Bit-Mikroprozessor der x86-Mikroprozessorserie ist ein 64-Bit-Mikroprozessor. Es ist recht modern, den 32-Bit-Prozessor der gleichen Serie zu ersetzen. Die Allzweckregister des 64-Bit-Mikroprozessors und ihre Namen lauten wie folgt:
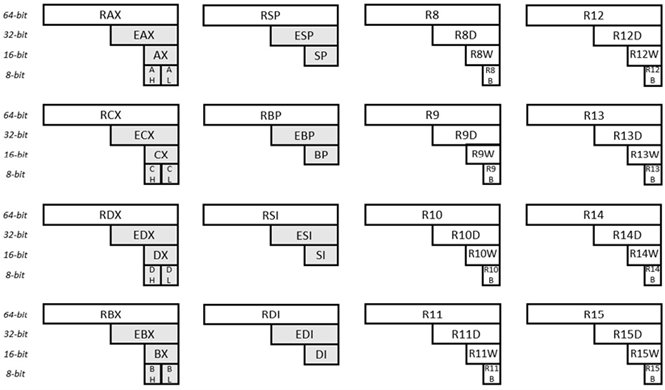
Abb. 6.31 Allzweckregister für x64
In der Abbildung sind sechzehn (16) Universalregister dargestellt. Jedes dieser Register ist 64 Bit breit. Wenn man sich das Register in der oberen linken Ecke ansieht, werden die 64 Bits als RAX identifiziert. Die ersten 32 Bits desselben Registers (von rechts) werden als EAX identifiziert. Die ersten 16 Bits desselben Registers (von rechts) werden als AX bezeichnet. Das zweite Byte (von rechts) desselben Registers wird als AH identifiziert (H bedeutet hier hoch). Und das erste Byte (dieselben Registers) wird als AL identifiziert (L bedeutet hier niedrig). Wenn man sich das Register in der unteren rechten Ecke ansieht, werden die 64 Bits als R15 identifiziert. Die ersten 32 Bits desselben Registers werden als R15D bezeichnet. Die ersten 16 Bits desselben Registers werden als R15W identifiziert. Und das erste Byte wird als R15B identifiziert. Die Namen der anderen Register (und Unterregister) werden auf ähnliche Weise erklärt.
Es gibt einige Unterschiede zwischen den Intel- und den AMD-µPs. Die Informationen in diesem Abschnitt gelten für Intel.
Beim 6502 µP ist das Programmzählerregister (nicht direkt zugänglich), das den nächsten auszuführenden Befehl enthält, 16 Bit breit. Hier (x64) wird der Programmzähler als Instruction Pointer bezeichnet und ist 64 Bit breit. Es ist als RIP gekennzeichnet. Das bedeutet, dass der x64 µP bis zu 264 = 1,844674407 x 1019 (tatsächlich 18.446.744.073.709.551.616) Speicherbyte-Speicherorte adressieren kann. RIP ist kein Allzweckregister.
Das Stack Pointer Register oder RSP gehört zu den 16 Allzweckregistern. Es zeigt auf den letzten Stapeleintrag im Speicher. Wie bei 6502 µP wächst der Stack für x64 nach unten. Beim x64 wird der Stack im RAM zum Speichern der Rücksprungadressen für Unterprogramme verwendet. Es wird auch zum Speichern des „Schattenraums“ verwendet (siehe folgende Diskussion).
Der 6502 µP verfügt über ein 8-Bit-Prozessorstatusregister. Das Äquivalent im x64 heißt RFLAGS-Register. Dieses Register speichert die Flags, die für die Ergebnisse von Operationen und zur Steuerung des Prozessors (µP) verwendet werden. Es ist 64 Bit breit. Die höheren 32 Bit sind reserviert und werden derzeit nicht verwendet. Die folgende Tabelle enthält die Namen, Indizes und Bedeutungen der häufig verwendeten Bits im RFLAGS-Register:
| Tabelle 6.31.1 Am häufigsten verwendete RFLAGS-Flags (Bits) |
|||
|---|---|---|---|
| Symbol | Bisschen | Name | Zweck |
| CF | 0 | Tragen | Es wird gesetzt, wenn eine arithmetische Operation einen Übertrag oder einen Kredit aus dem höchstwertigen Bit des Ergebnisses erzeugt; ansonsten gelöscht. Dieses Flag zeigt eine Überlaufbedingung für die Arithmetik mit vorzeichenlosen Ganzzahlen an. Es wird auch in der Arithmetik mit mehrfacher Genauigkeit verwendet. |
| PF | 2 | Parität | Es wird gesetzt, wenn das niederwertigste Byte des Ergebnisses eine gerade Anzahl von 1-Bits enthält; ansonsten gelöscht. |
| VON | 4 | Anpassen | Es wird gesetzt, wenn eine arithmetische Operation einen Übertrag oder einen Kredit aus Bit 3 des Ergebnisses erzeugt; ansonsten gelöscht. Dieses Flag wird in der binär codierten Dezimalarithmetik (BCD) verwendet. |
| ZF | 6 | Null | Es wird gesetzt, wenn das Ergebnis Null ist; ansonsten gelöscht. |
| SF | 7 | Zeichen | Es wird gesetzt, wenn es gleich dem höchstwertigen Bit des Ergebnisses ist, das das Vorzeichenbit einer vorzeichenbehafteten Ganzzahl ist (0 steht für einen positiven Wert und 1 für einen negativen Wert). |
| VON | elf | Überlauf | Es wird gesetzt, wenn das ganzzahlige Ergebnis eine zu große positive Zahl oder eine zu kleine negative Zahl (mit Ausnahme des Vorzeichenbits) ist, um in den Zieloperanden zu passen. ansonsten gelöscht. Dieses Flag zeigt eine Überlaufbedingung für die Arithmetik mit vorzeichenbehafteten Ganzzahlen (Zweierkomplement) an. |
| DF | 10 | Richtung | Es wird gesetzt, wenn die Richtungs-String-Anweisungen funktionieren (Inkrementieren oder Dekrementieren). |
| AUSWEIS | einundzwanzig | Identifikation | Es wird gesetzt, wenn die Veränderbarkeit das Vorhandensein der CPUID-Anweisung anzeigt. |
Zusätzlich zu den achtzehn 64-Bit-Registern, die zuvor angegeben wurden, verfügt der µP der x64-Architektur über acht 80-Bit breite Register für Gleitkomma-Arithmetik. Diese acht Register können auch als MMX-Register verwendet werden (siehe folgende Diskussion). Es gibt außerdem sechzehn 128-Bit-Register für XMM (siehe folgende Diskussion).
Dabei geht es nicht nur um Register. Es gibt weitere x64-Register, bei denen es sich um Segmentregister (meistens ungenutzt in x64), Steuerregister, Speicherverwaltungsregister, Debug-Register, Virtualisierungsregister und Leistungsregister handelt, die alle möglichen internen Parameter verfolgen (Cache-Hits/Miss, ausgeführte Mikrooperationen, Timing). , und vieles mehr).
SIMD
SIMD steht für Single Instruction Multiple Data. Dies bedeutet, dass ein Assembler-Befehl gleichzeitig auf mehrere Daten in einem Mikroprozessor einwirken kann. Betrachten Sie die folgende Tabelle:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | elf | 12 | 13 | 14 | fünfzehn | 16 |
| = | 10 | 12 | 14 | 16 | 18 | zwanzig | 22 | 24 |
In dieser Tabelle werden acht Zahlenpaare parallel (im gleichen Zeitraum) addiert, um acht Antworten zu ergeben. Ein Assembler-Befehl kann die acht parallelen Ganzzahladditionen in den MMX-Registern durchführen. Ähnliches kann mit den XMM-Registern durchgeführt werden. Es gibt also MMX-Anweisungen für Ganzzahlen und XMM-Anweisungen für Gleitkommazahlen.
6.32 Speicherkarte und x64
Da der Befehlszeiger (Programmzähler) 64 Bit hat, bedeutet dies, dass 264 = 1,844674407 x 1019 Speicherbyteplätze adressiert werden können. Im Hexadezimalformat ist die höchste Byteposition FFFF,FFFF,FFFF,FFFF16. Kein gewöhnlicher Computer kann heute einen so großen (vollständigen) Speicher bereitstellen. Eine geeignete Speicherzuordnung für den x64-Computer sieht also wie folgt aus:

Beachten Sie, dass die Lücke von 0000,8000,0000,000016 bis FFFF,7FFF,FFFF,FFFF16 keine Speicherorte (keine Speicher-RAM-Bänke) aufweist. Dies ist ein Unterschied von FFFF.0000.0000.000116, was ziemlich groß ist. Die kanonische obere Hälfte enthält das Betriebssystem, während die kanonische niedrige Hälfte die Benutzerprogramme (Anwendungen) und Daten enthält. Das Betriebssystem besteht aus zwei Teilen: einem kleinen UEFI (BIOS) und einem großen Teil, die von der Festplatte geladen werden. Im nächsten Kapitel wird mehr über die modernen Betriebssysteme gesprochen. Beachten Sie die Ähnlichkeit mit dieser Speicherzuordnung und der des Commodore-64, bei der 64 KB möglicherweise nach viel Speicher aussahen.
In diesem Zusammenhang wird das Betriebssystem grob als „Kernel“ bezeichnet. Der Kernel ähnelt dem Kernal des Commodore-64-Computers, verfügt jedoch über weitaus mehr Unterprogramme.
Die Endianness für x64 ist Little Endian, was bedeutet, dass für einen Speicherort die untere Adresse auf das untere Inhaltsbyte im Speicher zeigt.
6.33 Assembler-Adressierungsmodi für x64
Adressierungsmodi sind die Möglichkeiten, mit denen ein Befehl auf die µP-Register und den Speicher (einschließlich der internen Portregister) zugreifen kann. Der x64 verfügt über viele Adressierungsmodi, hier werden jedoch nur die häufig verwendeten Adressierungsmodi angesprochen. Die allgemeine Syntax für eine Anweisung lautet hier:
Opcode-Ziel, Quelle
Die Dezimalzahlen werden ohne Präfix oder Suffix geschrieben. Beim 6502 ist die Quelle implizit. Der x64 hat mehr Opcodes als der 6502, aber einige der Opcodes haben die gleichen Mnemoniken. Die einzelnen x64-Anweisungen sind unterschiedlich lang und können zwischen 1 und 15 Byte groß sein. Die am häufigsten verwendeten Adressierungsmodi sind wie folgt:
Sofortiger Adressierungsmodus
Hier ist der Quelloperand ein tatsächlicher Wert und keine Adresse oder Bezeichnung. Beispiel (Kommentar lesen):
EAX HINZUFÜGEN, 14 ; Dezimalzahl 14 zum 32-Bit-EAX des 64-Bit-RAX hinzufügen, die Antwort bleibt im EAX (Ziel)
Registrieren Sie sich, um den Adressierungsmodus zu registrieren
Beispiel:
R8B, AL HINZUFÜGEN; 8-Bit-AL von RAX zu R8B von 64-Bit-R8 hinzufügen – Antworten bleiben in R8B (Ziel)
Indirekter und indizierter Adressierungsmodus
Indirekte Adressierung mit dem 6502 µP bedeutet, dass die Position der angegebenen Adresse im Befehl die effektive Adresse (Zeiger) der endgültigen Position hat. Ähnliches passiert mit x64. Die Indexadressierung mit dem 6502 µP bedeutet, dass der Inhalt eines µP-Registers zur angegebenen Adresse im Befehl hinzugefügt wird, um die effektive Adresse zu erhalten. Ähnliches passiert mit dem x64. Außerdem kann beim x64 der Inhalt des Registers auch mit 1 oder 2 oder 4 oder 8 multipliziert werden, bevor er zur angegebenen Adresse addiert wird. Der mov-Befehl (Kopieren) des x64 kann sowohl indirekte als auch indizierte Adressierung kombinieren. Beispiel:
MOV R8W, 1234[8*RAX+RCX] ; Wort an Adresse verschieben (8 x RAX + RCX) + 1234
Hier hat R8W die ersten 16 Bit von R8. Die angegebene Adresse ist 1234. Das RAX-Register hat eine 64-Bit-Zahl, die mit 8 multipliziert wird. Das Ergebnis wird zum Inhalt des 64-Bit-RCX-Registers addiert. Dieses zweite Ergebnis wird zur angegebenen Adresse 1234 addiert, um die effektive Adresse zu erhalten. Die Zahl an der Stelle der effektiven Adresse wird an die erste 16-Bit-Stelle (R8W) des R8-Registers verschoben (kopiert) und ersetzt alles, was dort war. Beachten Sie die Verwendung der eckigen Klammern. Denken Sie daran, dass ein Wort in x64 16 Bit breit ist.
Relative RIP-Adressierung
Beim 6502 µP wird die relative Adressierung nur bei Verzweigungsbefehlen verwendet. Dort ist der einzelne Operand des Opcodes ein Offset, der zum Inhalt des Programmzählers für die effektive Befehlsadresse (nicht die Datenadresse) addiert oder subtrahiert wird. Ähnliches passiert beim x64, wo der Programmzähler als Anweisungszeiger bezeichnet wird. Die Anweisung mit x64 muss nicht nur eine Verzweigungsanweisung sein. Ein Beispiel für RIP-relative Adressierung ist:
MOV AL, [RIP]
AL von RAX verfügt über eine 8-Bit-Zahl mit Vorzeichen, die zum Inhalt im RIP (64-Bit-Befehlszeiger) addiert oder davon subtrahiert wird, um auf den nächsten Befehl zu verweisen. Beachten Sie, dass in dieser Anleitung ausnahmsweise Quelle und Ziel vertauscht sind. Beachten Sie auch die Verwendung der eckigen Klammern, die sich auf den Inhalt von RIP beziehen.
6.34 Häufig verwendete Anweisungen von x64
In der folgenden Tabelle bedeutet * verschiedene mögliche Suffixe einer Teilmenge von Opcodes:
| Tabelle 6.34.1 Häufig verwendete Anweisungen in x64 |
|
|---|---|
| Opcode | Bedeutung |
| MOV | Verschieben (Kopieren) zum/vom/zwischen Speicher und Registern |
| CMOV* | Verschiedene bedingte Bewegungen |
| XCHG | Austausch |
| BSWAP | Byte-Tausch |
| PUSH POP | Stack-Nutzung |
| ADD/ADC | Hinzufügen/mit Übertragen |
| SUB/SBC | Subtrahieren/mit Übertrag |
| MUL/IMUL | Multiplizieren/ohne Vorzeichen |
| DIV/IDIV | Teilen/ohne Vorzeichen |
| INC/DEC | Inkrementieren/Dekrementieren |
| NEG | Negieren |
| CMP | Vergleichen |
| UND/ODER/XOR/NICHT | Bitweise Operationen |
| SHR/SAR | Logisch/arithmetisch nach rechts verschieben |
| SHL/SAL | Logisch/arithmetisch nach links verschieben |
| ROR/ROLLE | Nach rechts/links drehen |
| RCR/RCL | Durch das Carry-Bit nach rechts/links drehen |
| BT/BTS/BTR | Bittest/und setzen/und zurücksetzen |
| JMP | Bedingungsloser Sprung |
| JE/JNE/JC/JNC/J* | Springen, wenn gleich/ungleich/tragen/nicht tragen/viele andere |
| GEHEN/GEHEN/GEHEN | Schleife mit ECX |
| ANRUFEN/RUF | Unterprogramm aufrufen/zurückgeben |
| NEIN | Keine Operation |
| CPUID | CPU-Informationen |
Der x64 verfügt über Multiplikations- und Divisionsanweisungen. Es verfügt über Multiplikations- und Divisions-Hardwareschaltungen in seinem µP. Der 6502 µP verfügt nicht über Multiplikations- und Divisions-Hardwareschaltungen. Die Multiplikation und Division ist mit Hardware schneller durchzuführen als mit Software (einschließlich der Verschiebung von Bits).
String-Anweisungen
Es gibt eine Reihe von String-Anweisungen, aber die einzige, die hier besprochen werden soll, ist die MOVS-Anweisung (für Move String), mit der eine Zeichenfolge ab Adresse C000 kopiert wird H . Beginnend bei Adresse C100 H , verwenden Sie die folgende Anweisung:
MOVS [C100H], [C000H]
Beachten Sie das Suffix H für hexadezimal.
6.35 Einschleifen in x64
Der 6502 µP verfügt über Verzweigungsbefehle zum Schleifen. Ein Verzweigungsbefehl springt zu einer Adressstelle, die den neuen Befehl enthält. Der Adressort kann als „Schleife“ bezeichnet werden. Der x64 verfügt über LOOP/LOOPE/LOOPNE-Anweisungen zum Schleifen. Diese reservierten Assemblerwörter dürfen nicht mit der Bezeichnung „Schleife“ (ohne Anführungszeichen) verwechselt werden. Das Verhalten ist wie folgt:
LOOP dekrementiert ECX und prüft, ob ECX nicht Null ist. Wenn diese Bedingung (Null) erfüllt ist, wird zu einem angegebenen Label gesprungen. Andernfalls fällt es durch (fahren Sie mit den restlichen Anweisungen in der folgenden Diskussion fort).
LOOPE dekrementiert ECX und prüft, ob ECX nicht Null ist (z. B. 1) und ZF gesetzt ist (auf 1). Wenn diese Bedingungen erfüllt sind, springt es zum Label. Sonst fällt es durch.
LOOPNE dekrementiert ECX und prüft, ob ECX nicht Null ist und ZF NICHT gesetzt ist (d. h. Null sein). Wenn diese Bedingungen erfüllt sind, wird zum Label gesprungen. Sonst fällt es durch.
Bei x64 enthält das RCX-Register oder seine Unterteile wie ECX oder CX die Zähler-Ganzzahl. Bei den LOOP-Anweisungen zählt der Zähler normalerweise herunter und dekrementiert bei jedem Sprung (Schleife) um 1. Im folgenden Schleifencodesegment erhöht sich die Zahl im EAX-Register in zehn Iterationen von 0 auf 10, während die Zahl in ECX zehnmal herunterzählt (dekrementiert) (lesen Sie die Kommentare):
MOV EAX, 0 ;
MOV ECX, 10 ; Zählen Sie standardmäßig 10 Mal herunter, einmal für jede Iteration
Etikett:
INC EAX ; Erhöhen Sie EAX als Schleifenkörper
LOOP-Label ; Dekrementieren Sie EAX, und wenn EAX nicht Null ist, führen Sie den Schleifenkörper ab „label:“ erneut aus.
Die Schleifencodierung beginnt mit „label:“. Beachten Sie die Verwendung des Doppelpunkts. Die Schleifencodierung endet mit dem „LOOP-Label“, das besagt, dass EAX dekrementiert wird. Wenn sein Inhalt nicht Null ist, kehren Sie zur Anweisung nach „label:“ zurück und führen Sie alle Anweisungen (alle Hauptanweisungen) erneut aus, die bis zum „LOOP label“ nach unten kommen. Beachten Sie, dass „label“ noch einen anderen Namen haben kann.
6.36 Eingabe/Ausgabe von x64
In diesem Abschnitt des Kapitels geht es um das Senden der Daten an einen (internen) Ausgangsport oder den Empfang der Daten von einem (internen) Eingangsport. Der Chipsatz verfügt über Acht-Bit-Ports. Zwei beliebige aufeinanderfolgende 8-Bit-Ports können als 16-Bit-Ports behandelt werden, und alle vier aufeinanderfolgenden Ports können als 32-Bit-Ports behandelt werden. Auf diese Weise kann der Prozessor 8, 16 oder 32 Bit an oder von einem externen Gerät übertragen.
Die Übertragung der Informationen zwischen dem Prozessor und einem internen Port kann auf zwei Arten erfolgen: über eine sogenannte speicherabgebildete Ein-/Ausgabe oder über einen separaten Ein-/Ausgabe-Adressraum. Die speicherzugeordneten E/A ähneln denen des 6502-Prozessors, bei dem die Portadressen tatsächlich Teil des gesamten Speicherraums sind. In diesem Fall werden die Daten beim Senden an einen bestimmten Adressort an einen Port und nicht an eine Speicherbank gesendet. Ports können über einen separaten E/A-Adressraum verfügen. Im letzteren Fall beginnen alle Speicherbänke mit ihren Adressen bei Null. Es gibt einen separaten Adressbereich von 0000H bis FFFF16. Diese werden von den Ports im Chipsatz verwendet. Das Motherboard ist so programmiert, dass es nicht zu einer Verwechslung zwischen speicherzugeordneten E/A und separatem E/A-Adressraum kommt.
Speicherabgebildete E/A
Dabei werden die Ports als Speicherorte betrachtet und die normalen Opcodes, die zwischen Speicher und µP verwendet werden, werden für die Datenübertragung zwischen µP und Ports verwendet. Um also ein Byte von einem Port an der Adresse F000H in das µP-Register RAX:EAX:AX:AL zu verschieben, gehen Sie wie folgt vor:
MOV AL, [F000H]
Ein String kann vom Speicher zu einem Port und umgekehrt verschoben werden. Beispiel:
MOVS [F000H], [C000H] ; Quelle ist C000H und Ziel ist Port bei F000H.
Separater E/A-Adressraum
Dabei sind die speziellen Anweisungen zur Ein- und Ausgabe zu verwenden.
Einzelne Artikel übertragen
Das Prozessorregister für die Übertragung ist RAX. Eigentlich ist es RAX:EAX für Doppelwort, RAX:EAX:AX für Wort und RAX:EAX:AX:AL für Byte. Um also ein Byte von einem Port bei FFF0h nach RAX:EAX:AX:AL zu übertragen, geben Sie Folgendes ein:
IN AL, [FFF0H]
Geben Sie für die Rückübertragung Folgendes ein:
OUT [FFF0H], AL
Für einzelne Artikel lauten die Anweisungen also IN und OUT. Die Portadresse kann auch im RDX:EDX:DX-Register angegeben werden.
Übertragen von Zeichenfolgen
Ein String kann vom Speicher an einen Chipsatz-Port und umgekehrt übertragen werden. Um eine Zeichenfolge von einem Port an der Adresse FFF0H in den Speicher zu übertragen, beginnen Sie bei C100H und geben Sie Folgendes ein:
INS [ESI], [DX]
was den gleichen Effekt hat wie:
INS [EDI], [DX]
Der Programmierer sollte die Zwei-Byte-Portadresse von FFF0H in das RDX:EDX:Dx-Register und die Zwei-Byte-Adresse von C100H in das RSI:ESI- oder RDI:EDI-Register einfügen. Gehen Sie für die Rückübertragung wie folgt vor:
INS [DX], [ESI]
was den gleichen Effekt hat wie:
INS [DX], [EDI]
6.37 Der Stack in x64
Wie der 6502-Prozessor verfügt auch der x64-Prozessor über einen Stack im RAM. Der Stapel für den x64 kann 2 sein 16 = 65.536 Bytes lang oder es können 2 sein 32 = 4.294.967.296 Bytes lang. Es wächst auch nach unten. Wenn der Inhalt eines Registers auf den Stapel verschoben wird, wird die Zahl im RSP-Stapelzeiger um 8 verringert. Denken Sie daran, dass eine Speicheradresse für x64 64 Bit breit ist. Der Wert im Stapelzeiger im µP zeigt auf die nächste Stelle im Stapel im RAM. Wenn der Inhalt eines Registers (oder ein Wert in einem Operanden) vom Stapel in ein Register verschoben wird, wird die Zahl im RSP-Stapelzeiger um 8 erhöht. Das Betriebssystem entscheidet über die Größe des Stapels und wo er im RAM beginnt und wächst nach unten. Denken Sie daran, dass es sich bei einem Stapel um eine LIFO-Struktur (Last-In-First-Out) handelt, die in diesem Fall nach unten wächst und nach oben schrumpft.
Gehen Sie wie folgt vor, um den Inhalt des µP-RBX-Registers auf den Stapel zu übertragen:
RBX DRÜCKEN
Gehen Sie wie folgt vor, um den letzten Eintrag im Stapel zurück zu RBX zu übertragen:
POP RBX
6.38 Vorgehensweise in x64
Das Unterprogramm im x64 heißt „Prozedur“. Der Stack wird hier stärker beansprucht als beim 6502 µP. Die Syntax für eine x64-Prozedur lautet:
proc_name:
Verfahrensorgan
…
Rechts
Bevor Sie fortfahren, beachten Sie, dass bei den Opcodes und Beschriftungen für eine x64-Subroutine (Assembler-Anweisungen im Allgemeinen) die Groß-/Kleinschreibung nicht beachtet wird. Das heißt, proc_name ist derselbe wie PROC_NAME. Wie beim 6502 beginnt der Name des Prozedurnamens (Label) am Anfang einer neuen Zeile im Texteditor für die Assemblersprache. Darauf folgt ein Doppelpunkt und nicht Leerzeichen und Opcode wie beim 6502. Es folgt der Unterprogrammkörper, der mit RET endet und nicht mit RTS wie beim 6502 µP. Wie beim 6502 beginnt jede Anweisung im Hauptteil, einschließlich RET, nicht am Anfang ihrer Zeile. Beachten Sie, dass eine Beschriftung hier mehr als 8 Zeichen lang sein kann. Um diese Prozedur oberhalb oder unterhalb der typisierten Prozedur aufzurufen, gehen Sie wie folgt vor:
CALL proc_name
Beim 6502 ist der Name des Etiketts nur ein Tipp zum Aufrufen. Allerdings wird hier das reservierte Wort „CALL“ oder „call“ eingegeben, gefolgt vom Namen der Prozedur (Unterroutine) nach einem Leerzeichen.
Beim Umgang mit Verfahren gibt es in der Regel zwei Verfahren. Eine Prozedur ruft die andere auf. Die aufrufende Prozedur (mit der Aufrufanweisung) wird als „Anrufer“ bezeichnet, die aufgerufene Prozedur als „Aufgerufener“. Es gibt eine Konvention (Regeln), die befolgt werden muss.
Die Regeln des Anrufers
Der Aufrufer sollte beim Aufruf einer Unterroutine die folgenden Regeln beachten:
1. Bevor ein Unterprogramm aufgerufen wird, sollte der Aufrufer den Inhalt bestimmter Register, die als vom Aufrufer gespeichert gekennzeichnet sind, im Stapel speichern. Die vom Aufrufer gespeicherten Register sind R10, R11 und alle Register, in die die Parameter eingefügt werden (RDI, RSI, RDX, RCX, R8, R9). Wenn der Inhalt dieser Register während des Unterprogrammaufrufs erhalten bleiben soll, verschieben Sie ihn auf den Stapel, anstatt ihn dann im RAM zu speichern. Dies ist erforderlich, da die Register vom Angerufenen zum Löschen des vorherigen Inhalts verwendet werden müssen.
2. Wenn die Prozedur beispielsweise darin besteht, zwei Zahlen zu addieren, sind die beiden Zahlen die Parameter, die an den Stapel übergeben werden. Um die Parameter an das Unterprogramm zu übergeben, tragen Sie sechs davon der Reihe nach in die folgenden Register ein: RDI, RSI, RDX, RCX, R8, R9. Wenn das Unterprogramm mehr als sechs Parameter enthält, schieben Sie den Rest in umgekehrter Reihenfolge (d. h. der letzte Parameter zuerst) auf den Stapel. Da der Stapel kleiner wird, wird der erste der zusätzlichen Parameter (eigentlich der siebte Parameter) an der niedrigsten Adresse gespeichert (diese Umkehrung der Parameter wurde früher verwendet, um die Übergabe der Funktionen (Unterprogramme) mit einer variablen Anzahl von Parametern zu ermöglichen).
3. Um das Unterprogramm (Prozedur) aufzurufen, verwenden Sie die Aufrufanweisung. Diese Anweisung platziert die Rücksprungadresse oben auf den Parametern im Stapel (unterste Position) und verzweigt zum Unterprogrammcode.
4. Nachdem das Unterprogramm zurückgekehrt ist (d. h. unmittelbar nach der Aufrufanweisung), muss der Aufrufer alle zusätzlichen Parameter (über die sechs in Registern gespeicherten Parameter hinaus) aus dem Stapel entfernen. Dadurch wird der Stapel in den Zustand vor dem Aufruf zurückversetzt.
5. Der Aufrufer kann damit rechnen, den Rückgabewert (Adresse) der Unterroutine im RAX-Register zu finden.
6. Der Aufrufer stellt den Inhalt der vom Aufrufer gespeicherten Register (R10, R11 und alle in den Parameterübergaberegistern) wieder her, indem er sie vom Stapel entfernt. Der Aufrufer kann davon ausgehen, dass durch das Unterprogramm keine weiteren Register verändert wurden.
Aufgrund der Art und Weise, wie die Aufrufkonvention strukturiert ist, kommt es normalerweise vor, dass einige (oder die meisten) dieser Schritte keine Änderungen am Stapel bewirken. Wenn beispielsweise sechs oder weniger Parameter vorhanden sind, wird in diesem Schritt nichts auf den Stapel verschoben. Ebenso halten die Programmierer (und Compiler) in den Schritten 1 und 6 normalerweise die Ergebnisse, die ihnen wichtig sind, aus den vom Aufrufer gespeicherten Registern fern, um übermäßige Pushs und Pops zu verhindern.
Es gibt zwei weitere Möglichkeiten, die Parameter an ein Unterprogramm zu übergeben, diese werden jedoch in diesem Online-Karrierekurs nicht behandelt. Einer von ihnen verwendet den Stack selbst anstelle der Allzweckregister.
Die Regeln des Angerufenen
Die Definition des aufgerufenen Unterprogramms sollte sich an folgende Regeln halten:
1. Ordnen Sie die lokalen Variablen (Variablen, die innerhalb der Prozedur entwickelt werden) zu, indem Sie die Register verwenden oder Platz auf dem Stapel schaffen. Denken Sie daran, dass der Stapel nach unten wächst. Um Platz oben im Stapel zu schaffen, sollte der Stapelzeiger dekrementiert werden. Der Betrag, um den der Stapelzeiger dekrementiert wird, hängt von der benötigten Anzahl lokaler Variablen ab. Wenn beispielsweise ein lokaler Float und ein lokaler Long (insgesamt 12 Bytes) erforderlich sind, muss der Stapelzeiger um 12 dekrementiert werden, um Platz für diese lokalen Variablen zu schaffen. In einer Hochsprache wie C bedeutet dies, die Variablen zu deklarieren, ohne die Werte zuzuweisen (zu initialisieren).
2. Als nächstes müssen die Werte aller Register gespeichert werden, die vom Aufrufer gespeichert werden sollen (Allzweckregister, die nicht vom Aufrufer gespeichert werden), die von der Funktion verwendet werden. Um die Register zu speichern, schieben Sie sie auf den Stapel. Die vom Aufrufer gespeicherten Register sind RBX, RBP und R12 bis R15 (RSP wird ebenfalls durch die Aufrufkonvention beibehalten, muss aber in diesem Schritt nicht auf den Stapel verschoben werden).
Nachdem diese drei Aktionen ausgeführt wurden, kann der eigentliche Betrieb des Unterprogramms fortgesetzt werden. Wenn das Unterprogramm zur Rückkehr bereit ist, werden die Aufrufkonventionsregeln fortgesetzt.
3. Wenn die Subroutine fertig ist, sollte der Rückgabewert für die Subroutine in RAX platziert werden, falls er noch nicht vorhanden ist.
4. Die Subroutine muss die alten Werte aller vom Aufrufer gespeicherten Register (RBX, RBP und R12 bis R15) wiederherstellen, die geändert wurden. Die Registerinhalte werden wiederhergestellt, indem sie vom Stapel entfernt werden. Beachten Sie, dass die Register in der umgekehrten Reihenfolge, in der sie gepusht wurden, geöffnet werden sollten.
5. Als nächstes geben wir die lokalen Variablen frei. Der einfachste Weg, dies zu tun, besteht darin, zum RSP den gleichen Betrag hinzuzufügen, der in Schritt 1 davon abgezogen wurde.
6. Schließlich kehren wir zum Aufrufer zurück, indem wir eine ret-Anweisung ausführen. Diese Anweisung findet die entsprechende Rücksprungadresse und entfernt sie vom Stapel.
Ein Beispiel für den Hauptteil einer Aufrufer-Subroutine zum Aufrufen einer anderen Subroutine namens „myFunc“ lautet wie folgt (lesen Sie die Kommentare):
; Sie möchten eine Funktion „myFunc“ aufrufen, die drei benötigt
; ganzzahliger Parameter. Der erste Parameter befindet sich in RAX.
; Zweiter Parameter ist die Konstante 456. Dritter
; Parameter liegt im Speicherort „Variable“
push rdi ; rdi wird ein Parameter sein, also speichern Sie es
; long retVal = myFunc(x, 456, z);
mov rdi, rax; Geben Sie den ersten Parameter in RDI ein
mov rsi, 456 ; Geben Sie den zweiten Parameter in RSI ein
mov rdx , [variabl] ; Geben Sie den dritten Parameter in RDX ein
rufe myFunc auf; Rufen Sie die Funktion auf
Pop RDI; Gespeicherten RDI-Wert wiederherstellen
; Der Rückgabewert von myFunc ist jetzt in RAX verfügbar
Ein Beispiel für eine aufgerufene Funktion (myFunc) ist (lesen Sie die Kommentare):
myFunc:
; ∗∗∗ Standard-Unterprogramm-Prolog ∗∗∗
sub-rsp, 8 ; Platz für eine lokale 64-Bit-Variable (Ergebnis) unter Verwendung des „Sub“-Opcodes
rbx drücken; Save Callee-Save Register
rbp drücken; beide werden von myFunc verwendet
; ∗∗∗ Unterroutinenkörper ∗∗∗
mov rax, rdi; Parameter 1 auf RAX
mov rbp, rsi; Parameter 2 auf RBP
mov rbx , rdx ; Parameter 3 zu rb x
mov [rsp + 1 6], rbx; rbx in die lokale Variable einfügen
add [rsp + 1 6], rbp; Fügen Sie rbp zur lokalen Variablen hinzu
mov rax, [rsp +16]; MOV-Inhalte der lokalen Variablen nach RAX verschieben
; (Rückgabewert/Endergebnis)
; ∗∗∗ Standard-Unterprogramm-Epilog ∗∗∗
Pop rbp ; Wiederherstellen der gespeicherten Register des Angerufenen
pop rbx ; umgekehrt wie beim Drücken
add rsp, 8 ; Lokale Variable(n) freigeben. 8 bedeutet 8 Bytes
zurück; Oberen Wert vom Stapel entfernen und dorthin springen
6.39 Unterbrechungen und Ausnahmen für x64
Der Prozessor bietet zwei Mechanismen zum Unterbrechen der Programmausführung, Interrupts und Ausnahmen:
- Ein Interrupt ist ein asynchrones Ereignis (das jederzeit auftreten kann), das normalerweise von einem E/A-Gerät ausgelöst wird.
- Eine Ausnahme ist ein synchrones Ereignis (passiert, wenn der Code ausgeführt wird, vorprogrammiert ist, basierend auf einem bestimmten Ereignis), das generiert wird, wenn der Prozessor beim Ausführen einer Anweisung eine oder mehrere vordefinierte Bedingungen erkennt. Es werden drei Klassen von Ausnahmen angegeben: Fehler, Traps und Abbrüche.
Der Prozessor reagiert auf Interrupts und Ausnahmen im Wesentlichen auf die gleiche Weise. Wenn ein Interrupt oder eine Ausnahme signalisiert wird, stoppt der Prozessor die Ausführung des aktuellen Programms oder der aktuellen Aufgabe und wechselt zu einer Handlerprozedur, die speziell für die Behandlung der Interrupt- oder Ausnahmebedingung geschrieben wurde. Der Prozessor greift über einen Eintrag in der Interrupt Descriptor Table (IDT) auf die Handler-Prozedur zu. Wenn der Handler die Behandlung des Interrupts oder der Ausnahme abgeschlossen hat, wird die Programmsteuerung an das unterbrochene Programm oder die unterbrochene Aufgabe zurückgegeben.
Das Betriebssystem, die Exekutive und/oder die Gerätetreiber behandeln die Interrupts und Ausnahmen normalerweise unabhängig von den Anwendungsprogrammen oder Aufgaben. Die Anwendungsprogramme können jedoch auf die in einem Betriebssystem integrierten Interrupt- und Exception-Handler zugreifen oder diese über Assembler-Aufrufe ausführen.
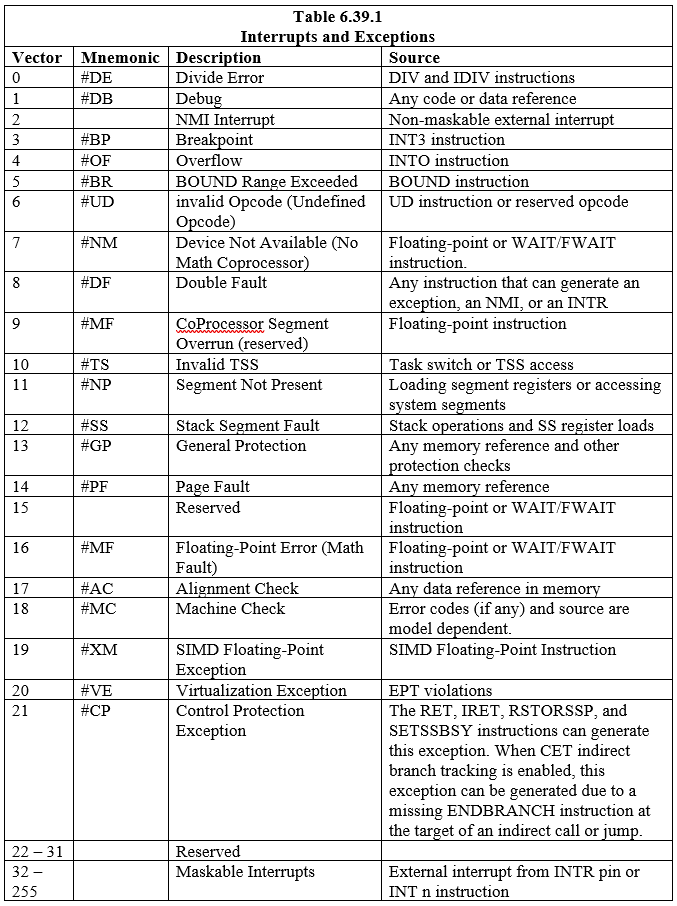
Es werden achtzehn (18) vordefinierte Interrupts und Ausnahmen definiert, die Einträgen im IDT zugeordnet sind. Außerdem können zweihundertvierundzwanzig (224) benutzerdefinierte Interrupts erstellt und der Tabelle zugeordnet werden. Jeder Interrupt und jede Ausnahme im IDT wird mit einer Nummer identifiziert, die als „Vektor“ bezeichnet wird. Tabelle 6.39.1 listet die Interrupts und Ausnahmen mit Einträgen im IDT und ihre jeweiligen Vektoren auf. Die Vektoren 0 bis 8, 10 bis 14 und 16 bis 19 sind die vordefinierten Interrupts und Ausnahmen. Die Vektoren 32 bis 255 sind für die softwaredefinierten Interrupts (Benutzer) vorgesehen, die entweder für Software-Interrupts oder maskierbare Hardware-Interrupts gelten.
Wenn der Prozessor einen Interrupt oder eine Ausnahme erkennt, führt er eine der folgenden Aktionen aus:
- Führen Sie einen impliziten Aufruf einer Handlerprozedur aus
- Führen Sie einen impliziten Aufruf einer Handler-Aufgabe aus
6.4 Die Grundlagen der 64-Bit-ARM-Computerarchitektur
Die ARM-Architekturen definieren eine Familie von RISC-Prozessoren, die für den Einsatz in einer Vielzahl von Anwendungen geeignet sind. ARM ist eine Lade-/Speicherarchitektur, bei der die Daten aus dem Speicher in ein Register geladen werden müssen, bevor damit eine Verarbeitung wie etwa eine ALU-Operation (Arithmetic Logic Unit) stattfinden kann. Eine nachfolgende Anweisung speichert das Ergebnis zurück im Speicher. Während dies wie ein Rückschritt gegenüber den x86- und x64-Architekturen erscheinen mag, die in einem einzigen Befehl direkt auf die Operanden im Speicher einwirken (natürlich unter Verwendung von Prozessorregistern), ermöglicht der Lade-/Speicheransatz in der Praxis mehrere sequentielle Vorgänge mit hoher Geschwindigkeit an einem Operanden ausgeführt werden, sobald dieser in eines der vielen Prozessorregister geladen wird. ARM-Prozessoren verfügen über die Option Little Endianness oder Big Endianness. Die Standardeinstellung von ARM 64 ist Little-Endian, die Konfiguration, die üblicherweise von den Betriebssystemen verwendet wird. Die 64-Bit-ARM-Architektur ist modern und soll die 32-Bit-ARM-Architektur ersetzen.
Notiz : Jeder Befehl für den 64-Bit-ARM-µP ist 4 Bytes (32 Bit) lang.
6.41 Der 64-Bit-ARM-Registersatz
Es gibt 31 allgemeine 64-Bit-Register für den 64-Bit-ARM-µP. Das folgende Diagramm zeigt die Allzweckregister und einige wichtige Register:
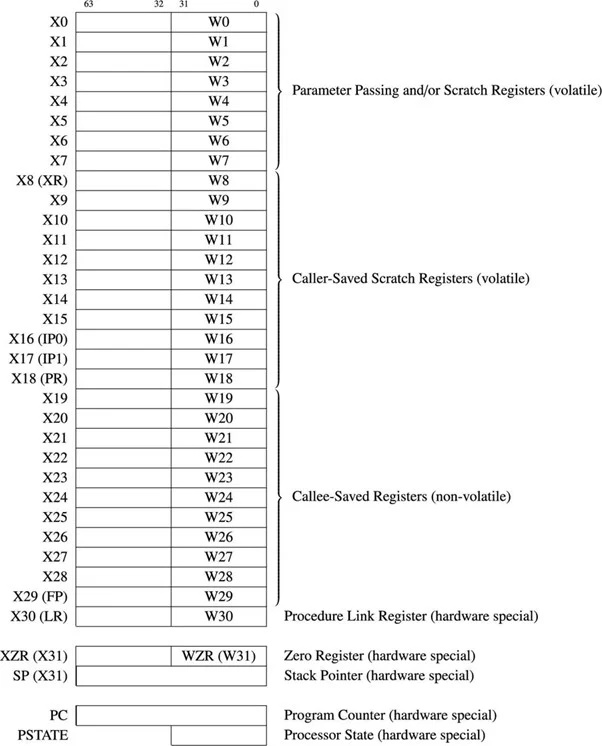
Abb. 4.11.1 64-Bit-Allzweckregister und einige wichtige Register
Die Allzweckregister werden mit X0 bis X30 bezeichnet. Der erste 32-Bit-Teil für jedes Register wird als W0 bis W30 bezeichnet. Wenn der Unterschied zwischen 32 Bit und 64 Bit nicht betont wird, wird das Präfix „R“ verwendet. R14 bezieht sich beispielsweise auf W14 oder X14.
Der 6502 µP verfügt über einen 16-Bit-Programmzähler und kann die 2 adressieren 16 Speicherbyte-Speicherorte. Der 64-Bit-ARM-µP verfügt über einen 64-Bit-Programmzähler und kann bis zu 2 adressieren 64 = 1,844674407 x 1019 (tatsächlich 18.446.744.073.709.551.616) Speicherbyte-Speicherorte. Der Programmzähler speichert die Adresse des nächsten auszuführenden Befehls. Die Länge der Anweisung des ARM64 oder AArch64 beträgt typischerweise vier Bytes. Der Prozessor erhöht dieses Register automatisch um vier, nachdem jeder Befehl aus dem Speicher abgerufen wurde.
Das Stapelzeigerregister oder SP gehört nicht zu den 31 Allzweckregistern. Der Stapelzeiger jeder Architektur zeigt auf den letzten Stapeleintrag im Speicher. Beim ARM-64 wächst der Stack nach unten.
Der 6502 µP verfügt über ein 8-Bit-Prozessorstatusregister. Das Äquivalent im ARM64 heißt PSTATE-Register. Dieses Register speichert die Flags, die für die Ergebnisse von Operationen und zur Steuerung des Prozessors (µP) verwendet werden. Es ist 32 Bit breit. Die folgende Tabelle enthält die Namen, Indizes und Bedeutungen für die häufig verwendeten Bits im PSTATE-Register:
| Tabelle 6.41.1 Am häufigsten verwendete PSTATE-Flags (Bits) |
||
|---|---|---|
| Symbol | Bisschen | Zweck |
| M | 0-3 | Modus: Die aktuelle Ausführungsberechtigungsstufe (USR, SVC usw.). |
| T | 4 | Thumb: Wird gesetzt, wenn der T32-Befehlssatz (Thumb) aktiv ist. Wenn leer, ist der ARM-Befehlssatz aktiv. Der Benutzercode kann dieses Bit setzen und löschen. |
| UND | 9 | Endianness: Durch Setzen dieses Bits wird der Big-Endian-Modus aktiviert. Wenn klar, ist der Little-Endian-Modus aktiv. Der Standardwert ist der Little-Endian-Modus. |
| Q | 27 | Flag für kumulative Sättigung: Es wird gesetzt, wenn es zu einem bestimmten Zeitpunkt in einer Reihe von Vorgängen zu einem Überlauf oder einer Sättigung kommt |
| IN | 28 | Überlaufflag: Es wird gesetzt, wenn die Operation zu einem signierten Überlauf geführt hat. |
| C | 29 | Carry-Flag: Zeigt an, ob die Addition einen Carry oder die Subtraktion einen Borrow erzeugt hat. |
| MIT | 30 | Null-Flag: Es wird gesetzt, wenn das Ergebnis einer Operation Null ist. |
| N | 31 | Negativ-Flag: Es wird gesetzt, wenn das Ergebnis einer Operation negativ ist. |
Der ARM-64 µP verfügt über viele weitere Register.
SIMD
SIMD steht für Single Instruction, Multiple Data. Dies bedeutet, dass ein Assembler-Befehl gleichzeitig auf mehrere Daten in einem Mikroprozessor einwirken kann. Es gibt zweiunddreißig 128 Bit breite Register zur Verwendung mit SIMD- und Gleitkommaoperationen.
6.42 Speicherzuordnung
RAM und DRAM sind beide Random Access Memorys. DRAM arbeitet langsamer als RAM. DRAM ist billiger als RAM. Wenn mehr als 32 Gigabyte (GB) kontinuierlicher DRAM im Speicher vorhanden sind, treten weitere Probleme bei der Speicherverwaltung auf: 32 GB = 32 x 1024 x 1024 x 1024 Bytes. Bei einem Gesamtspeicherplatz, der deutlich größer als 32 GB ist, sollte der DRAM über 32 GB zur besseren Speicherverwaltung mit RAMs durchsetzt werden. Um die ARM-64-Speicherzuordnung zu verstehen, sollten Sie zunächst die 4-GB-Speicherzuordnung für die 32-Bit-ARM-Zentraleinheit (CPU) verstehen. CPU bedeutet µP. Bei einem 32-Bit-Computer beträgt der maximal adressierbare Speicherplatz 2 32 = 4 x 2 10 x 2 10 x 2 10 = 4 x 1024 x 1024 x 1024 = 4.294.967.296 = 4 GB.
32-Bit-ARM-Speicherzuordnung
Die Speicherzuordnung für einen 32-Bit-ARM ist:

Bei einem 32-Bit-Computer beträgt die maximale Größe des gesamten Speichers 4 GB. Von der 0-GB-Adresse bis zur 1-GB-Adresse befinden sich das ROM-Betriebssystem, der RAM und die E/A-Speicherorte. Die gesamte Idee von ROM-Betriebssystem, RAM und I/O-Adressen ähnelt der Situation des Commodore-64 mit einer möglichen 6502-CPU. Das Betriebssystem-ROM für den Commodore-64 befindet sich am oberen Ende des Speicherplatzes. Das ROM-Betriebssystem ist hier viel größer als das des Commodore-64 und steht am Anfang des gesamten Speicheradressraums. Im Vergleich zu anderen modernen Computern ist das ROM-Betriebssystem hier vollständig, in dem Sinne, dass es mit der Menge an Betriebssystem auf ihren Festplatten vergleichbar ist. Es gibt zwei Hauptgründe dafür, dass sich das Betriebssystem in den ROM-integrierten Schaltkreisen befindet: 1) ARM-CPUs werden hauptsächlich in kleinen Geräten wie Smartphones verwendet. Viele Festplatten sind aus Sicherheitsgründen größer als Smartphones und andere kleine Geräte. Wenn sich das Betriebssystem im Nur-Lese-Speicher befindet, kann es von Hackern nicht beschädigt (Teile überschrieben) werden. Auch die RAM-Bereiche und Ein-/Ausgabebereiche sind im Vergleich zu denen des Commodore-64 sehr groß.
Wenn das 32-Bit-ROM-Betriebssystem eingeschaltet wird, muss das Betriebssystem mit der Adresse 0x00000000 oder der Adresse 0xFFFF0000 starten (booten), wenn HiVECs aktiviert ist. Wenn also nach der Reset-Phase die Stromversorgung eingeschaltet wird, lädt die CPU-Hardware 0x00000000 oder 0xFFFF0000 in den Programmzähler. Das Präfix „0x“ bedeutet Hexadezimal. Die Boot-Adresse von ARMv8-64-Bit-CPUs ist eine definierte Implementierung. Aus Gründen der Abwärtskompatibilität empfiehlt der Autor dem Computeringenieur jedoch, bei 0x00000000 oder 0xFFFF0000 zu beginnen.
Von 1 GB bis 2 GB ist der zugeordnete Ein-/Ausgang. Es gibt einen Unterschied zwischen der zugeordneten E/A und nur der E/A, die zwischen 0 GB und 1 GB liegt. Bei I/O ist die Adresse für jeden Port wie beim Commodore-64 festgelegt. Bei zugeordneten E/A ist die Adresse für jeden Port nicht unbedingt bei jedem Betrieb des Computers gleich (dynamisch).
Von 2 GB bis 4 GB ist DRAM. Dies ist der erwartete (oder übliche) RAM. DRAM steht für Dynamic RAM und bedeutet nicht, dass sich die Adresse während des Computerbetriebs ändert, sondern dass der Wert jeder Zelle im physischen RAM bei jedem Taktimpuls aktualisiert werden muss.
Notiz :
- Von 0x0000.0000 bis 0x0000 ist FFFF das Betriebssystem-ROM.
- Von 0x0001.0000 bis 0x3FFF,FFFF kann es mehr ROM, dann RAM und dann einige E/A geben.
- Von 0x4000.0000 bis 0x7FFF,FFFF ist ein zusätzlicher I/O und/oder zugeordneter I/O zulässig.
- Von 0x8000.0000 bis 0xFFFF ist FFFF der erwartete DRAM.
Dies bedeutet, dass der erwartete DRAM in der Praxis nicht an der 2-GB-Speichergrenze beginnen muss. Warum sollte der Programmierer die idealen Grenzen respektieren, wenn nicht genügend physische RAM-Bänke auf dem Motherboard vorhanden sind? Dies liegt daran, dass der Kunde nicht genug Geld für alle RAM-Banken hat.
36-Bit-ARM-Speicherzuordnung
Bei einem 64-Bit-ARM-Computer werden alle 32 Bit zur Adressierung des gesamten Speichers verwendet. Bei einem 64-Bit-ARM-Computer können die ersten 36 Bits verwendet werden, um den gesamten Speicher zu adressieren, der in diesem Fall 2 beträgt 36 = 68.719.476.736 = 64 GB. Das ist schon viel Speicher. Heutzutage benötigen normale Computer nicht mehr so viel Speicher. Dies entspricht noch nicht dem maximalen Speicherbereich, auf den 64 Bit zugreifen können. Die Speicherzuordnung für 36-Bit für die ARM-CPU lautet:
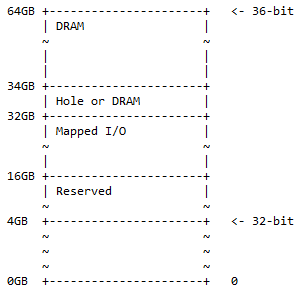
Von der 0-GB-Adresse bis zur 4-GB-Adresse ist die 32-Bit-Speicherzuordnung. „Reserviert“ bedeutet nicht verwendet und wird für die zukünftige Verwendung aufbewahrt. Es müssen keine physischen Speicherbänke sein, die für diesen Platz auf dem Motherboard gesteckt werden. Hier haben DRAM und zugeordnete E/A die gleiche Bedeutung wie für die 32-Bit-Speicherzuordnung.
In der Praxis kann folgende Situation vorkommen:
- 0x1 0000 0000 – 0x3 FFFF FFFF; reserviert. 12 GB Adressraum sind für die zukünftige Verwendung reserviert.
- 0x4 0000 0000 – 0x7 FFFF FFFF; zugeordnete E/A. Für dynamisch zugeordnete E/A stehen 16 GB Adressraum zur Verfügung.
- 0x8 0000 0000 – 0x8 7FFF FFFF FFFF; Loch oder DRAM. 2 GB Adressraum können Folgendes enthalten:
- Loch zum Aktivieren der DRAM-Gerätepartitionierung (wie in der folgenden Diskussion beschrieben).
- DRAM.
- 0x8 8000 0000 – 0xF FFFF FFFF; DRAM. 30 GB Adressraum für DRAM.
Diese Speicherzuordnung ist eine Obermenge der 32-Bit-Adresszuordnung, wobei der zusätzliche Speicherplatz in 50 % DRAM (1/2) mit einem optionalen Loch darin und 25 % zugeordneten E/A-Speicherplatz und reservierten Speicherplatz (1/4) aufgeteilt ist ). Die restlichen 25 % (1/4) sind für die 32-Bit-Speicherzuordnung ½ + ¼ + ¼ = 1.
Notiz : Von 32 Bit auf 360 Bit ist eine Addition von 4 Bit zur höchstwertigen Seite von 36 Bit.
40-Bit-Speicherkarte
Die 40-Bit-Adresszuordnung ist eine Obermenge der 36-Bit-Adresszuordnung und folgt dem gleichen Muster: 50 % DRAM einer optionalen Lücke darin, 25 % zugeordneter E/A-Speicherplatz und reservierter Speicherplatz und der Rest der 25 % Platz für die vorherige Speicherzuordnung (36-Bit). Das Diagramm für die Speicherzuordnung ist:
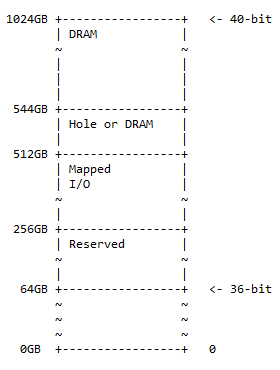
Die Größe des Lochs beträgt 544 – 512 = 32 GB. In der Praxis kann folgende Situation vorkommen:
- 0x10 0000 0000 – 0x3F FFFF FFFF; reserviert. 192 GB Adressraum sind für die zukünftige Verwendung reserviert.
- 0x40 0000 0000 – 0x7F FFFF FFFF; kartiert. E/A 256 GB Adressraum stehen für dynamisch zugeordnete E/A zur Verfügung.
- 0x80 0000 0000 – 0x87 FFFF FFFF; Loch oder DRAM. 32 GB Adressraum können Folgendes enthalten:
- Loch zum Aktivieren der DRAM-Gerätepartitionierung (wie in der folgenden Diskussion beschrieben)
- DRAM
- 0x88 0000 0000 – 0xFF FFFF FFFF; DRAM. 480 GB Adressraum für DRAM.
Notiz : Von 36 Bit auf 40 Bit ist eine Addition von 4 Bit zur höchstwertigen Seite von 36 Bit.
DRAM-Loch
In der Speicherzuordnung über 32 Bit hinaus handelt es sich entweder um ein DRAM-Loch oder um eine Fortsetzung des DRAM von oben. Wenn es sich um eine Lücke handelt, ist dies wie folgt zu verstehen: Eine DRAM-Lücke bietet eine Möglichkeit, ein großes DRAM-Gerät in mehrere Adressbereiche zu unterteilen. Das optionale DRAM-Loch wird am Anfang der höheren DRAM-Adressgrenze vorgeschlagen. Dies ermöglicht ein vereinfachtes Decodierungsschema bei der Partitionierung eines DRAM-Geräts mit großer Kapazität über den unteren physikalisch adressierten Bereich.
Beispielsweise wird ein 64-GB-DRAM-Teil in drei Bereiche unterteilt, wobei die Adressversätze durch eine einfache Subtraktion der höherwertigen Adressbits wie folgt durchgeführt werden:
| Tabelle 6.42.1 Beispiel für eine 64-GB-DRAM-Partitionierung mit Löchern |
|||
|---|---|---|---|
| Physische Adressen im SoC | Versatz | Interne DRAM-Adresse | |
| 2 GByte (32-Bit-Karte) | 0x00 8000 0000 – 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 – 0x00 7FFF FFFF |
| 30 GByte (36-Bit-Karte) | 0x08 8000 0000 – 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 – 0x07 FFFF FFFF |
| 32 GByte (40-Bit-Karte) | 0x88 0000 0000 – 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 – 0x0F FFFF FFFF |
Vorgeschlagene adressierte 44-Bit- und 48-Bit-Speicherzuordnungen für ARM-CPUs
Gehen Sie davon aus, dass ein Personal Computer über 1024 GB (= 1 TB) Speicher verfügt; das ist zu viel Speicher. Daher sind die 44-Bit- und 48-Bit-adressierten Speicherkarten für ARM-CPUs für 16 TB bzw. 256 TB lediglich Vorschläge für zukünftige Computeranforderungen. Tatsächlich folgen diese Vorschläge für die ARM-CPUs der gleichen Speicheraufteilung nach Verhältnis wie die vorherigen Speicherzuordnungen. Das heißt: 50 % DRAM mit einem optionalen Loch darin, 25 % zugeordneter E/A-Speicherplatz und reservierter Speicherplatz und der Rest der 25 % Speicherplatz für die vorherige Speicherzuordnung.
Die 52-Bit-, 56-Bit-, 60-Bit- und 64-Bit-adressierten Speicherkarten sollen für die ferne Zukunft noch für den ARM 64-Bit vorgeschlagen werden. Wenn die damaligen Wissenschaftler die Aufteilung des gesamten Speicherraums im Verhältnis 50 : 25 : 25 noch sinnvoll finden, werden sie das Verhältnis beibehalten.
Notiz : SoC steht für System-on-Chip und bezieht sich auf Schaltkreise im µP-Chip, die sonst nicht vorhanden wären.
SRAM oder Static Random Access Memory ist schneller als das traditionellere DRAM, benötigt aber mehr Siliziumfläche. SRAM erfordert keine Aktualisierung. Der Leser kann sich RAM als SRAM vorstellen.
6.43 Assembler-Adressierungsmodi für ARM 64
ARM ist eine Lade-/Speicherarchitektur, bei der die Daten aus dem Speicher in ein Prozessorregister geladen werden müssen, bevor damit eine Verarbeitung, beispielsweise eine arithmetisch-logische Operation, stattfinden kann. Eine nachfolgende Anweisung speichert das Ergebnis zurück im Speicher. Während dies wie ein Rückschritt gegenüber x86 und seinen nachfolgenden x64-Architekturen erscheinen mag, die die Operanden im Speicher in einem einzigen Befehl direkt bearbeiten, ermöglicht der Lade/Speicher-Ansatz in der Praxis die Ausführung mehrerer sequenzieller Vorgänge mit hoher Geschwindigkeit ein Operand, sobald er in eines der vielen Prozessorregister geladen wird.
Das Format der ARM-Assemblersprache weist Ähnlichkeiten und Unterschiede zur x64 (x86)-Serie auf.
- Versatz : Dem Basisregister kann eine vorzeichenbehaftete Konstante hinzugefügt werden. Der Offset wird als Teil der Anweisung eingegeben. Beispiel: ldr x0, [rx, #10] lädt r0 mit dem Wort an der Adresse r1+10.
- Registrieren : Ein vorzeichenloses Inkrement, das in einem Register gespeichert ist, kann zum Wert in einem Basisregister addiert oder davon subtrahiert werden. Beispiel: ldr r0, [x1, x2] lädt r0 mit dem Wort an der Adresse x1+x2. Jedes der Register kann als Basisregister betrachtet werden.
- Skaliertes Register : Ein Inkrement in einem Register wird um eine angegebene Anzahl von Bitpositionen nach links oder rechts verschoben, bevor es zum Basisregisterwert addiert oder davon subtrahiert wird. Beispiel: ldr x0, [x1, x2, lsl #3] lädt r0 mit dem Wort an der Adresse r1+(r2×8). Die Verschiebung kann eine logische Links- oder Rechtsverschiebung (lsl oder lsr) sein, die Nullbits an den frei gewordenen Bitpositionen einfügt, oder eine arithmetische Rechtsverschiebung (asr), die das Vorzeichenbit an den frei gewordenen Positionen repliziert.
Wenn zwei Operanden beteiligt sind, steht das Ziel vor (links) der Quelle (hiervon gibt es einige Ausnahmen). Bei den Opcodes für die ARM-Assemblersprache wird die Groß-/Kleinschreibung nicht beachtet.
Sofortiger ARM64-Adressierungsmodus
Beispiel:
mov r0, #0xFF000000 ; Laden Sie den 32-Bit-Wert FF000000h in r0
Ein Dezimalwert hat kein 0x, wird aber trotzdem mit # vorangestellt.
Registrieren Sie sich direkt
Beispiel:
mov x0, x1 ; Kopieren Sie x1 nach x0
Indirekt registrieren
Beispiel:
str x0, [x3] ; Speichern Sie x0 an der Adresse in x3
Registrieren Sie indirekt mit Offset
Beispiele:
ldr x0, [x1, #32] ; Laden Sie r0 mit dem Wert an der Adresse [r1+32]; r1 ist das Basisregister
str x0, [x1, #4] ; Speichern Sie r0 an der Adresse [r1+4]; r1 ist das Basisregister; Zahlen haben die Basis 10
Register Indirekt mit Offset (vorinkrementiert)
Beispiele:
ldr x0, [x1, #32]! ; Laden Sie r0 mit [r1+32] und aktualisieren Sie r1 auf (r1+32).
str x0, [x1, #4]! ; Speichern Sie r0 in [r1+4] und aktualisieren Sie r1 auf (r1+4).
Beachten Sie die Verwendung des „!“ Symbol.
Register Indirekt mit Offset (post-inkrementiert)
Beispiele:
ldr x0, [x1], #32 ; Laden Sie [x1] auf x0 und aktualisieren Sie dann x1 auf (x1+32).
str x0, [x1], #4 ; Speichern Sie x0 in [x1] und aktualisieren Sie dann x1 auf (x1+4).
Doppeltes Register indirekt
Die Adresse des Operanden ist die Summe eines Basisregisters und eines Inkrementregisters. Die Registernamen sind in eckige Klammern eingeschlossen.
Beispiele:
ldr x0, [x1, x2] ; Laden Sie x0 mit [x1+x2]
str x0, [rx, x2] ; Speichern Sie x0 in [x1+x2]
Relativer Adressierungsmodus
Im relativen Adressierungsmodus ist der wirksame Befehl der nächste Befehl im Programmzähler plus ein Index. Der Index kann positiv oder negativ sein.
Beispiel:
ldr x0, [pc, #24]
Damit ist das Laderegister X0 mit dem Wort gemeint, auf das der PC-Inhalt zeigt, plus 24.
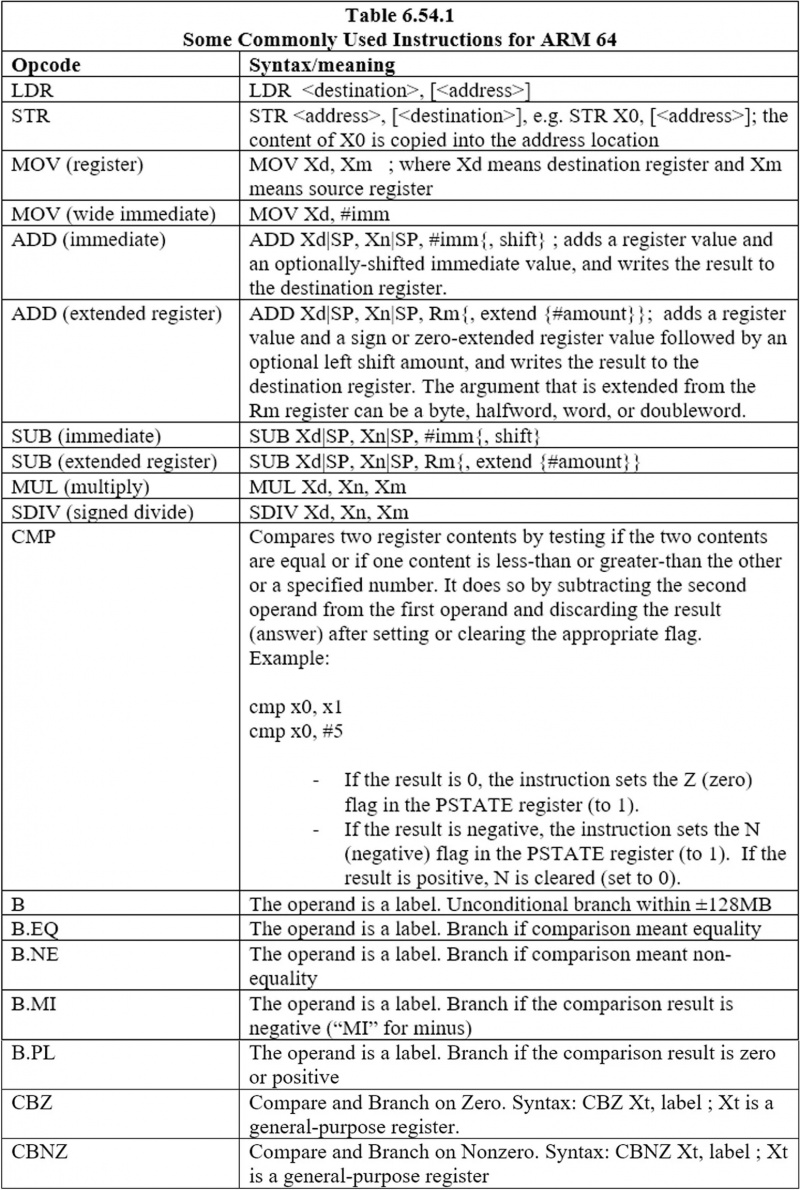
6.44 Einige häufig verwendete Anweisungen für ARM 64
Hier sind die am häufigsten verwendeten Anweisungen:
6.45 Looping
Illustration
Der folgende Code addiert den Wert im X10-Register so lange zum Wert in X9, bis der Wert in X8 Null ist. Gehen Sie davon aus, dass alle Werte ganze Zahlen sind. Der Wert in X8 wird in jeder Iteration um 1 subtrahiert:
Schleife:
CBZ X8, überspringen
ADD X9, X9, X10 ; Der erste X9 ist das Ziel und der zweite X9 die Quelle
SUB X8, X8, #1 ; Der erste X8 ist das Ziel und der zweite X8 die Quelle
B-Schleife
überspringen:
Wie beim 6502 µP und dem X64 µP beginnt die Beschriftung beim ARM 64 µP am Anfang der Zeile. Die restlichen Anweisungen beginnen einige Leerzeichen nach dem Zeilenanfang. Bei x64 und ARM 64 folgt auf die Bezeichnung ein Doppelpunkt und eine neue Zeile. Bei 6502 folgt auf die Bezeichnung nach einem Leerzeichen eine Anweisung. Im vorherigen Code bedeutet die erste Anweisung „CBZ X8, überspringen“, dass, wenn der Wert in 'überspringen:'. „B-Schleife“ ist ein bedingungsloser Sprung zur Bezeichnung „Schleife“. Anstelle von „loop“ kann jeder andere Labelname verwendet werden.
Verwenden Sie also wie beim 6502 µP die Verzweigungsanweisungen, um eine Schleife mit dem ARM 64 zu erstellen.
6.46 ARM 64 Eingang/Ausgang
Alle ARM-Peripheriegeräte (interne Ports) sind speicherzugeordnet. Das bedeutet, dass es sich bei der Programmierschnittstelle um einen Satz speicheradressierter Register (interne Ports) handelt. Die Adresse eines solchen Registers ist ein Offset von einer bestimmten Speicherbasisadresse. Dies ähnelt der Art und Weise, wie der 6502 die Ein-/Ausgabe durchführt. ARM verfügt nicht über die Option für einen separaten E/A-Adressraum.
6,47 Stapel von ARM 64
Der ARM 64 verfügt über einen Stapel im Arbeitsspeicher (RAM), ähnlich wie der 6502 und der x64. Beim ARM64 gibt es jedoch keinen Push- oder Pop-Opcode. Auch der Stack in ARM 64 wächst nach unten. Die Adresse im Stapelzeiger zeigt direkt nach dem letzten Byte des letzten Werts, der im Stapel platziert wird.
Der Grund, warum es für den ARM64 keinen generischen Pop- oder Push-Opcode gibt, liegt darin, dass ARM 64 seinen Stapel in Gruppen von aufeinanderfolgenden 16 Bytes verwaltet. Die Werte liegen jedoch in Bytegruppen von einem Byte, zwei Bytes, vier Bytes und 8 Bytes vor. So kann ein Wert in den Stapel gelegt werden und die restlichen Stellen (Byte-Speicherorte), um 16 Bytes auszugleichen, werden mit Dummy-Bytes aufgefüllt. Dies hat den Nachteil, dass Speicher verschwendet wird. Eine bessere Lösung besteht darin, den 16-Byte-Speicherort mit kleineren Werten zu füllen und vom Programmierer Code schreiben zu lassen, der verfolgt, woher die Werte im 16-Byte-Speicherort stammen (Register). Dieser zusätzliche Code wird auch zum Zurückziehen der Werte benötigt. Eine Alternative dazu besteht darin, zwei 8-Byte-Allzweckregister mit den unterschiedlichen Werten zu füllen und dann den Inhalt der beiden 8-Byte-Register an einen Stapel zu senden. Hier ist noch ein zusätzlicher Code erforderlich, um die spezifischen kleinen Werte zu verfolgen, die in den Stapel gelangen und den Stapel verlassen.
Der folgende Code speichert vier 4-Byte-Daten im Stapel:
str w0, [sp, #-4]!
str w1, [sp, #-8]!
str w2, [sp, #-12]!
str w3, [sp, #-16]!
Die ersten vier Bytes (w) der Register – x0, x1, x2 und x3 – werden an 16 aufeinanderfolgende Byte-Positionen im Stapel gesendet. Beachten Sie die Verwendung von „str“ und nicht „push“. Beachten Sie das Ausrufezeichen am Ende jeder Anweisung. Da der Speicherstapel nach unten wächst, beginnt der erste Vier-Byte-Wert an einer Position, die minus vier Bytes unter der vorherigen Stapelzeigerposition liegt. Die restlichen Vier-Byte-Werte folgen nach unten. Das folgende Codesegment führt das korrekte (und in der richtigen Reihenfolge) Äquivalent zum Platzieren der vier Bytes durch:
ldr w3, [sp], #0
ldr w2, [sp], #4
ldr w1, [sp], #8
ldr w0, [sp], #12
Beachten Sie die Verwendung des LDR-Opcodes anstelle von Pop. Beachten Sie auch, dass das Ausrufezeichen hier nicht verwendet wird.
Alle Bytes in X0 (8 Bytes) und X1 (8 Bytes) können wie folgt an die 16-Byte-Position im Stapel gesendet werden:
Schritt x0, x1, [sp, #-16]! ; 8 + 8 = 16
In diesem Fall werden die Register x2 (w2) und x3 (w3) nicht benötigt. Alle gewünschten Bytes befinden sich in den Registern X0 und X2. Beachten Sie den STP-Opcode zum Speichern der Registerinhaltspaare im RAM. Beachten Sie auch das Ausrufezeichen. Das Pop-Äquivalent ist:
ldp x0, x1, [sp], #0
Für diese Anweisung gibt es kein Ausrufezeichen. Beachten Sie den Opcode LDP anstelle von LDR zum Laden zweier aufeinanderfolgender Datenstellen aus dem Speicher in zwei µP-Register. Denken Sie auch daran, dass das Kopieren vom Speicher in ein µP-Register ein Laden ist, nicht zu verwechseln mit dem Laden einer Datei von der Festplatte in den RAM, und dass das Kopieren von einem µP-Register in den RAM ein Speichern ist.
6.48 Unterprogramm
Eine Unterroutine ist ein Codeblock, der eine Aufgabe ausführt, optional basierend auf einigen Argumenten, und optional ein Ergebnis zurückgibt. Konventionell werden die Register R0 bis R3 (vier Register) verwendet, um die Argumente (Parameter) an ein Unterprogramm zu übergeben, und R0 wird verwendet, um ein Ergebnis an den Aufrufer zurückzusenden. Eine Unterroutine, die mehr als 4 Eingaben benötigt, verwendet den Stapel für die zusätzlichen Eingaben. Um ein Unterprogramm aufzurufen, verwenden Sie den Link oder die bedingte Verzweigungsanweisung. Die Syntax für die Link-Anweisung lautet:
BL-Label
Dabei ist BL der Opcode und die Bezeichnung den Start (die Adresse) des Unterprogramms. Dieser Zweig ist bedingungslos, vorwärts oder rückwärts innerhalb von 128 MB. Die Syntax für die bedingte Verzweigungsanweisung lautet:
B.cond-Label
Dabei ist cond die Bedingung, z. B. eq (gleich) oder ne (ungleich). Das folgende Programm verfügt über die Unterroutine doadd, die die Werte zweier Argumente addiert und ein Ergebnis in R0 zurückgibt:
AREA subroute, CODE, READONLY ; Benennen Sie diesen Codeblock
EINTRAG; Markieren Sie die erste auszuführende Anweisung
MOV starten r0, #10 ; Parameter einrichten
MOV r1, #3
BL doadd ; Unterprogramm aufrufen
MOV stoppen r0, #0x18 ; angel_SWIreason_ReportException
LDR r1, =0x20026 ; ADP_Stopped_ApplicationExit
SVC #0x123456 ; ARM-Semihosting (ehemals SWI)
doadd ADD r0, r0, r1 ; Unterprogrammcode
BX lr ; Rückkehr vom Unterprogramm
;
ENDE ; Ende der Datei markieren
Die hinzuzufügenden Zahlen sind Dezimalzahl 10 und Dezimalzahl 3. Die ersten beiden Zeilen in diesem Codeblock (Programm) werden später erklärt. Die nächsten drei Zeilen senden 10 an das R0-Register und 3 an das R1-Register und rufen außerdem die Unterroutine doadd auf. „doadd“ ist die Bezeichnung, die die Adresse des Anfangs der Unterroutine enthält.
Das Unterprogramm besteht nur aus zwei Zeilen. Die erste Zeile fügt den Inhalt 3 von R zum Inhalt 10 von R0 hinzu, was das Ergebnis 13 in R0 ermöglicht. Die zweite Zeile mit dem BX-Opcode und dem LR-Operanden führt vom Unterprogramm zum Aufrufercode zurück.
RECHTS
Der RET-Opcode in ARM 64 kümmert sich immer noch um die Unterroutine, funktioniert aber anders als RTS in 6502 oder RET auf x64 oder die „BX LR“-Kombination in ARM 64. In ARM 64 lautet die Syntax für RET:
GERADE {Xn}
Diese Anweisung gibt dem Programm die Möglichkeit, mit einer Unterroutine fortzufahren, die nicht die aufrufende Unterroutine ist, oder einfach mit einer anderen Anweisung und dem darauffolgenden Codesegment fortzufahren. Xn ist ein Allzweckregister, das die Adresse enthält, an der das Programm fortgesetzt werden soll. Diese Anweisung verzweigt bedingungslos. Wenn Xn nicht angegeben ist, wird standardmäßig der Inhalt von X30 verwendet.
Prozeduraufruf Standard
Wenn der Programmierer möchte, dass sein Code mit einem Code interagiert, der von jemand anderem geschrieben wurde oder mit einem Code, der von einem Compiler erstellt wurde, muss der Programmierer mit der Person oder dem Compiler-Autor die Regeln für die Registernutzung vereinbaren. Für die ARM-Architektur werden diese Regeln als Procedure Call Standard oder PCS bezeichnet. Dabei handelt es sich um Vereinbarungen zwischen zwei oder drei Parteien. Das PCS spezifiziert Folgendes:
- Welche µP-Register werden verwendet, um die Argumente an die Funktion (Unterroutine) zu übergeben?
- Welche µP-Register werden verwendet, um das Ergebnis an die aufrufende Funktion zurückzugeben, die als Aufrufer bezeichnet wird?
- Welcher µP die aufgerufene Funktion registriert, die als Aufgerufener bezeichnet wird, kann beschädigt werden
- Welcher µP den Angerufenen registriert, kann nicht beschädigt werden
6.49 Unterbrechungen
Für den ARM-Prozessor stehen zwei Arten von Interrupt-Controller-Schaltkreisen zur Verfügung:
- Standard-Interrupt-Controller: Der Interrupt-Handler bestimmt, welches Gerät gewartet werden muss, indem er ein Geräte-Bitmap-Register im Interrupt-Controller liest.
- Vector Interrupt Controller (VIC): Priorisiert die Interrupts und vereinfacht die Bestimmung, welches Gerät den Interrupt verursacht hat. Nachdem jedem Interrupt eine Priorität und eine Handler-Adresse zugeordnet wurden, sendet der VIC nur dann ein Interrupt-Signal an den Prozessor, wenn die Priorität eines neuen Interrupts höher ist als die des aktuell ausgeführten Interrupt-Handlers.
Notiz : Ausnahme bezieht sich auf Fehler. Die Details zum Vektor-Interrupt-Controller für den 32-Bit-ARM-Computer lauten wie folgt (64-Bit ist ähnlich):
| Tabelle 6.49.1 ARM-Vektor-Ausnahme/Interrupt für 32-Bit-Computer |
|||
|---|---|---|---|
| Ausnahme/Unterbrechung | Kurze Hand | Adresse | Hohe Adresse |
| Zurücksetzen | ZURÜCKSETZEN | 0x00000000 | 0xffff0000 |
| Undefinierte Anweisung | UNDEF | 0x00000004 | 0xffff0004 |
| Software-Unterbrechung | SWI | 0x00000008 | 0xffff0008 |
| Prefetch-Abbruch | pabt | 0x0000000C | 0xffff000C |
| Abtreibungsdatum | DABT | 0x00000010 | 0xffff0010 |
| Reserviert | – | 0x00000014 | 0xffff0014 |
| Unterbrechungsanforderung | IRQ | 0x00000018 | 0xffff0018 |
| Schnelle Unterbrechungsanforderung | FIQ | 0x0000001C | 0xffff001C |
Dies sieht aus wie die Anordnung für die 6502-Architektur, wo NMI , BR , Und IRQ kann Zeiger auf Seite Null haben und die entsprechenden Routinen befinden sich weit oben im Speicher (ROM-Betriebssystem). Kurzbeschreibungen der Zeilen der vorherigen Tabelle lauten wie folgt:
ZURÜCKSETZEN
Dies geschieht, wenn der Prozessor hochfährt. Es initialisiert das System und richtet die Stapel für verschiedene Prozessormodi ein. Es handelt sich um die Ausnahme mit der höchsten Priorität. Beim Eintritt in den Reset-Handler befindet sich das CPSR im SVC-Modus und sowohl IRQ- als auch FIQ-Bits werden auf 1 gesetzt, wodurch etwaige Interrupts maskiert werden.
DATUM DER ABTREIBUNG
Die zweithöchste Priorität. Dies geschieht, wenn wir versuchen, eine ungültige Adresse zu lesen/schreiben oder auf die falsche Zugriffsberechtigung zuzugreifen. Beim Eintritt in den Data Abort Handler werden die IRQs deaktiviert (I-Bit auf 1 gesetzt) und FIQ aktiviert. Die IRQs sind maskiert, die FIQs bleiben jedoch unmaskiert.
FIQ
Die Interrupts mit der höchsten Priorität, IRQ und FIQs, werden deaktiviert, bis FIQ verarbeitet wird.
IRQ
Der Interrupt mit hoher Priorität, der IRQ-Handler, wird nur eingegeben, wenn kein laufender FIQ- und Datenabbruch vorliegt.
Abbruch des Vorabrufs
Dies ähnelt einem Datenabbruch, tritt jedoch bei einem Fehler beim Adressabruf auf. Beim Eintritt in den Handler werden IRQs deaktiviert, FIQs bleiben jedoch aktiviert und können während eines Abbruchs vor dem Abruf auftreten.
SWI
Eine Software-Interrupt-Ausnahme (SWI) tritt auf, wenn der SWI-Befehl ausgeführt wird und keine der anderen Ausnahmen mit höherer Priorität gekennzeichnet wurde.
Undefinierte Anweisung
Die Ausnahme „Undefinierte Anweisung“ tritt auf, wenn eine Anweisung, die nicht im ARM- oder Thumb-Befehlssatz enthalten ist, die Ausführungsphase der Pipeline erreicht und keine der anderen Ausnahmen gekennzeichnet wurde. Dies hat die gleiche Priorität wie SWI, da jeweils ein Fehler auftreten kann. Dies bedeutet, dass der ausgeführte Befehl nicht gleichzeitig ein SWI-Befehl und ein undefinierter Befehl sein kann.
ARM-Ausnahmebehandlung
Die folgenden Ereignisse treten auf, wenn eine Ausnahme auftritt:
- Speichern Sie das CPSR im SPSR des Ausnahmemodus.
- PC wird im LR des Ausnahmemodus gespeichert.
- Das Linkregister wird basierend auf dem aktuellen Befehl auf eine bestimmte Adresse gesetzt. Beispiel: Für ISR ist LR = zuletzt ausgeführte Anweisung + 8.
- Aktualisieren Sie den CPSR bezüglich der Ausnahme.
- Stellen Sie den PC auf die Adresse des Ausnahmebehandlers ein.
6.5 Anweisungen und Daten
Daten beziehen sich auf Variablen (Beschriftungen mit ihren Werten) sowie Arrays und andere Strukturen, die Arrays ähneln. Die Zeichenfolge ist wie ein Array von Zeichen. In einem der vorherigen Kapitel wurde ein Array von Ganzzahlen gesehen. Anweisungen beziehen sich auf Opcodes und ihre Operanden. Ein Programm kann mit gemischten Opcodes und Daten in einem fortlaufenden Speicherabschnitt geschrieben werden. Dieser Ansatz hat Nachteile, wird jedoch nicht empfohlen.
Ein Programm sollte zuerst mit den Anweisungen geschrieben werden, gefolgt von den Daten (Plural von Datum ist Daten). Der Abstand zwischen den Anweisungen und den Daten kann nur wenige Bytes betragen. Bei einem Programm können sich sowohl die Anweisungen als auch die Daten in einem oder zwei separaten Abschnitten im Speicher befinden.
6.6 Die Harvard-Architektur
Einer der frühen Computer heißt Harvard Mark I (1944). Eine strikte Harvard-Architektur verwendet einen Adressraum für Programmanweisungen und einen anderen separaten Adressraum für Daten. Das bedeutet, dass es zwei getrennte Speicher gibt. Das Folgende zeigt die Architektur:
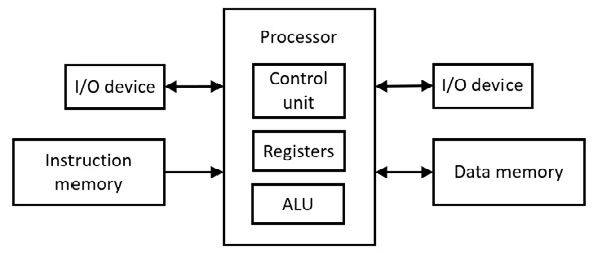
Abbildung 6.71 Harvard-Architektur
Die Steuereinheit übernimmt die Befehlsdekodierung. Die Arithmetic Logic Unit (ALU) führt die arithmetischen Operationen mit kombinatorischer Logik (Gattern) aus. ALU übernimmt auch die logischen Operationen (z. B. Verschiebung).
Beim Mikroprozessor 6502 geht ein Befehl zuerst an den Mikroprozessor (Steuereinheit), bevor das Datum (Singular für Daten) an das µP-Register geht, bevor sie interagieren. Dies erfordert mindestens zwei Taktimpulse und es handelt sich nicht um einen gleichzeitigen Zugriff auf Befehl und Datum. Andererseits ermöglicht die Harvard-Architektur den gleichzeitigen Zugriff auf Befehle und Daten, wobei sowohl Befehle als auch Daten gleichzeitig in den µP gelangen (Opcode an die Steuereinheit und Daten an das µP-Register), wodurch mindestens ein Taktimpuls eingespart wird. Dies ist eine Form der Parallelität. Diese Form der Parallelität wird im Hardware-Cache moderner Motherboards verwendet (siehe folgende Diskussion).
6.7 Cache-Speicher
Cache-Speicher (RAM) ist ein Hochgeschwindigkeitsspeicherbereich (im Vergleich zur Geschwindigkeit des Hauptspeichers), der die Programmanweisungen oder Daten für die zukünftige Verwendung vorübergehend speichert. Der Cache-Speicher arbeitet schneller als der Hauptspeicher. Normalerweise werden diese Anweisungen oder Datenelemente aus dem aktuellen Hauptspeicher abgerufen und werden wahrscheinlich in Kürze erneut benötigt. Der Hauptzweck des Cache-Speichers besteht darin, die Geschwindigkeit des wiederholten Zugriffs auf dieselben Hauptspeicherplätze zu erhöhen. Um effektiv zu sein, muss der Zugriff auf die zwischengespeicherten Elemente deutlich schneller erfolgen als der Zugriff auf die ursprüngliche Quelle der Anweisungen oder Daten, die als Backing Store bezeichnet wird.
Wenn Caching verwendet wird, beginnt jeder Versuch, auf einen Hauptspeicherort zuzugreifen, mit einer Suche im Cache. Wenn der angeforderte Artikel vorhanden ist, ruft der Prozessor ihn ab und verwendet ihn sofort. Dies wird als Cache-Hit bezeichnet. Wenn die Cache-Suche nicht erfolgreich ist (Cache-Fehler), muss die Anweisung oder das Datenelement aus dem Sicherungsspeicher (Hauptspeicher) abgerufen werden. Beim Abrufen des angeforderten Elements wird dem Cache eine Kopie für eine voraussichtliche Verwendung in naher Zukunft hinzugefügt.
Speicherverwaltungseinheit
Die Memory Management Unit (MMU) ist eine Schaltung, die den Hauptspeicher und die zugehörigen Speicherregister auf dem Motherboard verwaltet. Früher war es ein separater integrierter Schaltkreis auf der Hauptplatine; aber heute ist es typischerweise Teil des Mikroprozessors. Die MMU sollte auch den Cache (Schaltkreis) verwalten, der heute ebenfalls Teil des Mikroprozessors ist. Der Cache-Schaltkreis war früher ein separater integrierter Schaltkreis.
Statischer RAM
Statischer RAM (SRAM) hat eine wesentlich schnellere Zugriffszeit als DRAM, allerdings auf Kosten einer deutlich komplexeren Schaltung. Die SRAM-Bitzellen nehmen viel mehr Platz auf dem Chip der integrierten Schaltung ein als die Zellen eines DRAM-Geräts, das eine entsprechende Datenmenge speichern kann. Der Hauptspeicher (RAM) besteht typischerweise aus DRAM (Dynamic RAM).
Der Cache-Speicher verbessert die Computerleistung, da viele Algorithmen, die von Betriebssystemen und Anwendungen ausgeführt werden, die Lokalität der Referenz aufweisen. Die Referenzlokalität bezieht sich auf die Wiederverwendung von Daten, auf die kürzlich zugegriffen wurde. Dies wird als zeitliche Lokalität bezeichnet. Auf einem modernen Motherboard befindet sich der Cache-Speicher im selben integrierten Schaltkreis wie der Mikroprozessor. Der Hauptspeicher (DRAM) liegt weit entfernt und ist über die Busse zugänglich. Die Referenzlokalität bezieht sich auch auf die räumliche Lokalität. Die räumliche Lokalität hängt mit der höheren Geschwindigkeit des Datenzugriffs aufgrund der physischen Nähe zusammen.
In der Regel sind die Cache-Speicherbereiche im Vergleich zum Sicherungsspeicher (Hauptspeicher) klein (in Bezug auf die Anzahl der Byte-Speicherplätze). Die Cache-Speichergeräte sind auf maximale Geschwindigkeit ausgelegt, was im Allgemeinen bedeutet, dass sie pro Bit komplexer und teurer sind als die Datenspeichertechnologie, die im Backing Store verwendet wird. Aufgrund ihrer begrenzten Größe neigen die Cache-Speichergeräte dazu, sich schnell zu füllen. Wenn ein Cache keinen verfügbaren Speicherort zum Speichern eines neuen Eintrags hat, muss ein älterer Eintrag verworfen werden. Der Cache-Controller verwendet eine Cache-Ersetzungsrichtlinie, um auszuwählen, welcher Cache-Eintrag durch den neuen Eintrag überschrieben wird.
Das Ziel des Mikroprozessor-Cache-Speichers besteht darin, den Prozentsatz der Cache-Treffer im Laufe der Zeit zu maximieren und so die höchste nachhaltige Befehlsausführungsrate zu gewährleisten. Um dieses Ziel zu erreichen, muss die Caching-Logik bestimmen, welche Anweisungen und Daten im Cache abgelegt und für die nahe Zukunft aufbewahrt werden.
Die Caching-Logik eines Prozessors bietet keine Garantie dafür, dass ein zwischengespeichertes Datenelement jemals wieder verwendet wird, sobald es in den Cache eingefügt wurde.
Die Logik des Cachings beruht auf der Wahrscheinlichkeit, dass aufgrund der zeitlichen (sich im Laufe der Zeit wiederholenden) und räumlichen (räumlichen) Lokalität eine sehr gute Chance besteht, dass auf die zwischengespeicherten Daten in naher Zukunft zugegriffen wird. In praktischen Implementierungen auf modernen Prozessoren treten Cache-Treffer typischerweise bei 95 bis 97 Prozent der Speicherzugriffe auf. Da die Latenz des Cache-Speichers nur einen kleinen Bruchteil der Latenz des DRAM ausmacht, führt eine hohe Cache-Trefferrate zu einer erheblichen Leistungsverbesserung im Vergleich zu einem Cache-freien Design.
Etwas Parallelität mit Cache
Wie bereits erwähnt, sind bei einem guten Programm die Anweisungen im Speicher von den Daten getrennt. In einigen Cache-Systemen gibt es einen Cache-Schaltkreis „links“ vom Prozessor und einen weiteren Cache-Schaltkreis „rechts“ vom Prozessor. Der linke Cache verarbeitet die Anweisungen eines Programms (oder einer Anwendung) und der rechte Cache verarbeitet die Daten desselben Programms (oder derselben Anwendung). Dies führt zu einer besseren Geschwindigkeitssteigerung.
6.8 Prozesse und Threads
Sowohl der CISC- als auch der RISC-Computer verfügen über Prozesse. Ein Prozess befindet sich in der Software. Ein Programm, das läuft (ausführt), ist ein Prozess. Das Betriebssystem bringt eigene Programme mit. Während der Computer läuft, laufen auch die Programme des Betriebssystems, die den Betrieb des Computers ermöglichen. Dies sind Betriebssystemprozesse. Der Benutzer oder Programmierer kann seine eigenen Programme schreiben. Wenn das Programm des Benutzers ausgeführt wird, handelt es sich um einen Prozess. Dabei spielt es keine Rolle, ob das Programm in Assembler oder in einer Hochsprache wie C oder C++ geschrieben ist. Alle Prozesse (Benutzer oder Betriebssystem) werden von einem anderen Prozess namens „Scheduler“ verwaltet.
Ein Thread ist wie ein Unterprozess, der zu einem Prozess gehört. Ein Prozess kann gestartet und in Threads aufgeteilt werden und dann weiterhin als ein Prozess fortgesetzt werden. Ein Prozess ohne Threads kann als Hauptthread betrachtet werden. Prozesse und ihre Threads werden vom selben Scheduler verwaltet. Der Scheduler selbst ist ein Programm, wenn er sich auf der Betriebssystemfestplatte befindet. Bei der Ausführung im Speicher ist der Scheduler ein Prozess.
6.9 Mehrfachverarbeitung
Threads werden fast wie Prozesse verwaltet. Multiprocessing bedeutet, dass mehr als ein Prozess gleichzeitig ausgeführt wird. Es gibt Computer mit nur einem Mikroprozessor. Es gibt Computer mit mehr als einem Mikroprozessor. Bei einem einzelnen Mikroprozessor nutzen die Prozesse und/oder Threads denselben Mikroprozessor in einer verschachtelten (oder zeitaufteilenden) Weise. Das bedeutet, dass ein Prozess den Prozessor nutzt und ohne Abschluss stoppt. Ein anderer Prozess oder Thread nutzt den Prozessor und stoppt, ohne ihn zu beenden. Dann nutzt ein anderer Prozess oder Thread den Mikroprozessor und stoppt, ohne ihn zu beenden. Dies wird so lange fortgesetzt, bis alle Prozesse und Threads, die vom Scheduler in die Warteschlange gestellt wurden, einen Anteil am Prozessor erhalten haben. Dies wird als gleichzeitiges Multiprocessing bezeichnet.
Wenn mehr als ein Mikroprozessor vorhanden ist, liegt im Gegensatz zur Parallelität ein paralleles Multiprocessing vor. In diesem Fall führt jeder Prozessor einen bestimmten Prozess oder Thread aus, der sich von dem unterscheidet, was der andere Prozessor ausführt. Alle Prozessoren auf demselben Motherboard führen ihre unterschiedlichen Prozesse und/oder unterschiedlichen Threads gleichzeitig im parallelen Multiprocessing aus. Die Prozesse und Threads im parallelen Multiprocessing werden weiterhin vom Scheduler verwaltet. Paralleles Multiprocessing ist schneller als gleichzeitiges Multiprocessing.
An dieser Stelle fragt sich der Leser vielleicht, warum die parallele Verarbeitung schneller ist als die gleichzeitige Verarbeitung. Dies liegt daran, dass die Prozessoren denselben Speicher und dieselben Ein-/Ausgabeanschlüsse gemeinsam nutzen (zu unterschiedlichen Zeiten nutzen müssen). Nun, durch die Verwendung von Cache ist der Gesamtbetrieb des Motherboards schneller.
6.10 Paging
Die Memory Management Unit (MMU) ist eine Schaltung, die sich in der Nähe des Mikroprozessors oder im Mikroprozessorchip befindet. Es behandelt die Speicherzuordnung oder das Paging sowie andere Speicherprobleme. Weder der 6502 µP noch der Commodore-64-Computer verfügen per se über eine MMU (obwohl es im Commodore-64 immer noch eine gewisse Speicherverwaltung gibt). Der Commodore-64 verwaltet den Speicher durch Paging, wobei jede Seite 256 ist 10 Bytes lang (100 16 Bytes lang). Es war nicht zwingend erforderlich, den Speicher durch Paging zu verwalten. Es könnte immer noch nur eine Speicherkarte und dann Programme geben, die sich einfach in die verschiedenen dafür vorgesehenen Bereiche einfügen. Nun, Paging ist eine Möglichkeit, den Speicher effizient zu nutzen, ohne viele Speicherabschnitte zu haben, die keine Daten oder Programme enthalten können.
Die Computerarchitektur x86 386 wurde 1985 veröffentlicht. Der Adressbus ist 32 Bit breit. Also insgesamt 2 32 = 4.294.967.296 Adressraum ist möglich. Dieser Adressraum ist in 1.048.576 Seiten = 1.024 KB-Seiten unterteilt. Bei dieser Seitenanzahl besteht eine Seite aus 4.096 Bytes = 4 KB. Die folgende Tabelle zeigt die physischen Adressseiten für die x86-32-Bit-Architektur:
| Tabelle 6.10.1 Physisch adressierbare Seiten für die x86-Architektur |
||
|---|---|---|
| Basis 16 Adressen | Seiten | Basis 10 Adressen |
| FFFFF000 – FFFFFFFF | Seite 1.048.575 | 4.294.963.200 – 4.294.967.295 |
| FFFFE000 – FFFFEFFF | Seite 1.044.479 | 4.294.959.104 – 4.294.963.199 |
| FFFFD000 – FFFFDFFF | Seite 1.040.383 | 4.294.955.008 – 4.294.959.103 |
| | | | |
| | | |
| | | |
| 00002000 – 00002FFF | Seite 2 | 8.192 – 12.288 |
| 00001000 – 00001FFF | Seite 1 | 4.096 – 8.191 |
| 00000000 – 00000FFF | Seite 0 | 0 – 4.095 |
Eine Anwendung besteht heute aus mehr als einem Programm. Ein Programm kann weniger als eine Seite (weniger als 4096) oder zwei oder mehr Seiten beanspruchen. Eine Anwendung kann also eine oder mehrere Seiten beanspruchen, wobei jede Seite 4096 Byte lang ist. Eine Bewerbung kann von verschiedenen Personen verfasst werden, wobei jeder Person eine oder mehrere Seiten zugeordnet sind.
Beachten Sie, dass Seite 0 von 00000000H bis 00000FFF reicht
Seite 1 ist von 00001000H bis 00001FFFH, Seite 2 ist von 00002000 H – 00002FFF H , und so weiter. Bei einem 32-Bit-Computer gibt es im Prozessor zwei 32-Bit-Register für die physische Seitenadressierung: eines für die Basisadresse und das andere für die Indexadresse. Um beispielsweise auf die Byte-Speicherorte von Seite 2 zuzugreifen, sollte das Register für die Basisadresse 00002 sein H Das sind die ersten 20 Bits (von links) für die Startadressen der Seite 2. Die restlichen Bits liegen im Bereich 000 H zu FFF H befinden sich in dem Register, das „Indexregister“ genannt wird. Auf alle Bytes der Seite kann also zugegriffen werden, indem einfach der Inhalt im Indexregister von 000 an erhöht wird H zu FFF H . Der Inhalt im Indexregister wird zu dem sich nicht ändernden Inhalt im Basisregister addiert, um die effektive Adresse zu erhalten. Dieses Indexadressierungsschema gilt für die anderen Seiten.
Dies ist jedoch nicht wirklich die Art und Weise, wie das Assemblerprogramm für jede Seite geschrieben wird. Für jede Seite schreibt der Programmierer den Code beginnend mit Seite 000 H zur Seite FFF H . Da der Code auf verschiedenen Seiten miteinander verbunden ist, verwendet der Compiler die Indexadressierung, um alle zugehörigen Adressen auf verschiedenen Seiten zu verbinden. Nehmen wir beispielsweise an, dass Seite 0, Seite 1 und Seite 2 für eine Anwendung gelten und jeweils die Nummer 555 haben H Adressen, die miteinander verbunden sind, kompiliert der Compiler so, dass bei 555 H der Seite 0 aufgerufen werden soll, 00000 H wird im Basisregister stehen und 555 H wird im Indexregister stehen. Wenn 555 H der Seite 1 aufgerufen werden soll, 00001 H wird im Basisregister stehen und 555 H wird im Indexregister stehen. Wenn 555 H auf Seite 2 zugegriffen werden soll, 00002 H befindet sich im Basisregister und 555H im Indexregister. Dies ist möglich, da die Adressen über Labels (Variablen) identifiziert werden können. Die verschiedenen Programmierer müssen sich auf die Namen der Labels einigen, die für die verschiedenen Verbindungsadressen verwendet werden sollen.
Virtueller Seitenspeicher
Wie zuvor beschrieben, kann das Paging geändert werden, um die Größe des Speichers in einer Technik zu erhöhen, die als „Page Virtual Memory“ bezeichnet wird. Unter der Annahme, dass alle physischen Speicherseiten, wie zuvor beschrieben, etwas enthalten (Anweisungen und Daten), sind derzeit nicht alle Seiten aktiv. Die derzeit nicht aktiven Seiten werden an die Festplatte gesendet und durch die Seiten von der Festplatte ersetzt, die ausgeführt werden müssen. Dadurch vergrößert sich der Speicher. Während der Computer weiterarbeitet, werden die inaktiv gewordenen Seiten mit den Seiten auf der Festplatte ausgetauscht, bei denen es sich möglicherweise noch um die Seiten handelt, die vom Speicher an die Festplatte gesendet wurden. All dies wird von der Memory Management Unit (MMU) erledigt.
6.11 Probleme
Dem Leser wird empfohlen, alle Probleme in einem Kapitel zu lösen, bevor er mit dem nächsten Kapitel fortfährt.
1) Nennen Sie die Gemeinsamkeiten und Unterschiede der CISC- und RISC-Computerarchitekturen. Nennen Sie je ein Beispiel für einen SISC- und einen RISC-Rechner.
2) a) Wie lauten die folgenden Namen für den CISC-Computer in Bezug auf Bits: Byte, Wort, Doppelwort, Quadwort und Doppelquadwort.
b) Wie lauten die folgenden Namen für den RISC-Computer in Bezug auf Bits: Byte, Halbwort, Wort und Doppelwort?
c) Ja oder Nein. Bedeuten Doppelwort und Quadwort in CISC- und RISC-Architekturen dasselbe?
3 a) Für x64 reicht die Anzahl der Bytes für die Assembler-Anweisungen von was bis was?
b) Ist die Anzahl der Bytes für alle Assembler-Anweisungen für den ARM 64 festgelegt? Wenn ja, wie viele Bytes haben alle Befehle?
4) Listen Sie die am häufigsten verwendeten Assembler-Anweisungen für x64 und ihre Bedeutung auf.
5) Listen Sie die am häufigsten verwendeten Assembler-Anweisungen für ARM 64 und ihre Bedeutung auf.
6) Zeichnen Sie ein beschriftetes Blockdiagramm der Harvard-Architektur des alten Computers. Erklären Sie, wie seine Anweisungen und Datenfunktionen im Cache moderner Computer verwendet werden.
7) Unterscheiden Sie zwischen einem Prozess und einem Thread und geben Sie den Namen des Prozesses an, der die Prozesse und Threads in den meisten Computersystemen verarbeitet.
8) Erklären Sie kurz, was Multiprocessing ist.
9) a) Erklären Sie Paging im Hinblick auf die x86 386 µP-Computerarchitektur.
b) Wie kann dieses Paging geändert werden, um die Größe des gesamten Speichers zu vergrößern?