Nun werden wir alle oben genannten Bildverarbeitungsthemen im Detail erläutern.
1. Bildübersetzung
Die Bildübersetzung ist eine Bildverarbeitungsmethode, die uns hilft, das Bild entlang der x- und y-Achse zu verschieben. Wir können das Bild nach oben, unten, rechts, links oder in einer beliebigen Kombination verschieben.
Wir können die Übersetzungsmatrix mit dem Symbol M definieren und wir können sie in mathematischer Form darstellen, wie unten gezeigt:
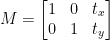
Wir können das Konzept des Übersetzungsbildes durch dieses Programm verstehen.
Python-Code: Wir behalten den Namen des folgenden Programms bei translate.py .
# Erforderliche Pakete importierenimportieren taub als z.B.
importieren argparse
importieren unnütz
importieren Lebenslauf2
# Wir implementieren den Argument-Parser
ap_obj = argparse. ArgumentParser ( )
ap_obj. add_argument ( '-k' , '--Bild' , erforderlich = Wahr ,
Hilfe = 'Speicherort der Bilddatei' )
Argumente = Deren ( ap_obj. parse_args ( ) )
# Laden Sie das Bild und zeigen Sie es auf dem Bildschirm an
Bild = Lebenslauf2. imgelesen ( Argumente [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original Bild' , Bild )
# Die Übersetzung des Bildes ist eine NumPy-Matrix, die unten angegeben ist:
# [[1, 0, shiftX], [0, 1, shiftY]]
# Wir werden die obige NumPy-Matrix verwenden, um die Bilder entlang der zu verschieben
# x-Achsen- und y-Achsenrichtungen. Dazu müssen wir einfach die Pixelwerte übergeben.
# In diesem Programm verschieben wir das Bild um 30 Pixel nach rechts
# und 70 Pixel nach unten.
translation_mat = z.B. float32 ( [ [ 1 , 0 , 30 ] , [ 0 , 1 , 70 ] ] )
Bild_Übersetzung = Lebenslauf2. warpAffine ( Bild , translation_mat ,
( Bild. Form [ 1 ] , Bild. Form [ 0 ] ) )
Lebenslauf2. imzeigen ( 'Bildübersetzung nach unten und rechts' , Bild_Übersetzung )
# Jetzt werden wir die obige NumPy-Matrix verwenden, um die Bilder entlang der zu verschieben
# Richtungen der x-Achse (links) und der y-Achse (oben).
# Hier verschieben wir die Bilder um 50 Pixel nach links
# und 90 Pixel nach oben.
translation_mat = z.B. float32 ( [ [ 1 , 0 , - fünfzig ] , [ 0 , 1 , - 90 ] ] )
Bild_Übersetzung = Lebenslauf2. warpAffine ( Bild , translation_mat ,
( Bild. Form [ 1 ] , Bild. Form [ 0 ] ) )
Lebenslauf2. imzeigen ( 'Bildübersetzung nach oben und links' , Bild_Übersetzung )
Lebenslauf2. WaitKey ( 0 )
Zeilen 1 bis 5: Wir importieren alle erforderlichen Pakete für dieses Programm, wie OpenCV, argparser und NumPy. Bitte beachten Sie, dass es eine andere Bibliothek gibt, die imutils ist. Dies ist kein Paket von OpenCV. Dies ist nur eine Bibliothek, die auf einfache Weise die gleiche Bildverarbeitung zeigt.
Die Bibliothek imutils wird bei der Installation von OpenCV nicht automatisch eingebunden. Um die imutils zu installieren, müssen wir also die folgende Methode verwenden:
pip imutils installieren
Zeilen 8 bis 15: Wir haben unseren Agrparser erstellt und unser Image geladen.
Zeilen 24 bis 25: In diesem Programmabschnitt findet die Übersetzung statt. Die Übersetzungsmatrix sagt uns, um wie viele Pixel das Bild nach oben oder unten oder nach links oder rechts verschoben wird. Da OpenCV erfordert, dass sich der Matrixwert in einem Gleitkomma-Array befindet, nimmt die Übersetzungsmatrix Werte in Gleitkomma-Arrays an.
Die erste Zeile der Übersetzungsmatrix sieht so aus:
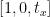
Diese Zeile der Matrix ist für die x-Achse. Der Wert von t x entscheidet, ob das Bild nach links oder rechts verschoben wird. Wenn wir einen negativen Wert übergeben, bedeutet dies, dass das Bild nach links verschoben wird, und wenn der Wert positiv ist, bedeutet dies, dass das Bild nach rechts verschoben wird.
Wir definieren nun die zweite Zeile der Matrix wie folgt:
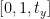
Diese Zeile der Matrix ist für die y-Achse. Der Wert von t Y entscheidet, ob das Bild nach oben oder unten verschoben wird. Wenn wir einen negativen Wert übergeben, bedeutet dies, dass das Bild nach oben verschoben wird, und wenn der Wert positiv ist, bedeutet dies, dass das Bild nach unten verschoben wird.
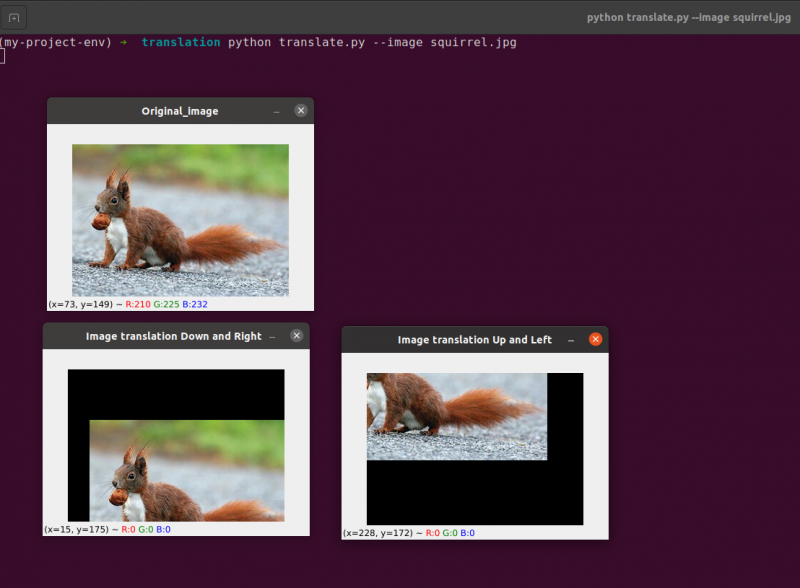
Im vorherigen Programm definieren wir in Zeile 24 das t x = 30 und die t Y = 70. Wir verschieben das Bild also um 30 Pixel nach rechts und 70 Pixel nach unten.
Aber der Hauptprozess der Bildübersetzung findet in Zeile 25 statt, wo wir die Übersetzungsmatrix definieren cv2.warpAffine . In dieser Funktion übergeben wir drei Parameter: Der erste Parameter ist das Bild, der zweite Parameter ist die Übersetzungsmatrix und der dritte Parameter ist die Bilddimension.
Zeile 27: Zeile 27 zeigt das Ergebnis in der Ausgabe an.
Jetzt werden wir eine weitere Übersetzungsmatrix für links und oben implementieren. Dazu müssen wir die Werte negativ definieren.
Zeile 33 bis 34: Im vorherigen Programm definieren wir in Zeile 33 das t x = -50 und die t Y = -90. Wir verschieben das Bild also um 50 Pixel nach links und um 90 Pixel nach oben. Aber der Hauptprozess der Bildübersetzung findet in Zeile 34 statt, wo wir die Übersetzungsmatrix definieren cv2.warpAffine .
Zeile 36 : Die Zeile 36 zeigt das Ergebnis wie in der Ausgabe gezeigt an.
Um den vorherigen Code auszuführen, müssen wir den Pfad des Bildes wie unten angegeben angeben.
Ausgabe: python translate.py – Bild Eichhörnchen.jpg
Jetzt implementieren wir dasselbe Bildübersetzungsprogramm mit der unnütz Bibliothek. Diese Bibliothek ist sehr einfach für die Bildbearbeitung zu verwenden. In dieser Bibliothek müssen wir nicht darüber nachdenken cv2.warpAffine denn diese Bibliothek wird sich darum kümmern. Lassen Sie uns also dieses Bildübersetzungsprogramm mit der imutils-Bibliothek implementieren.
Python-Code: Wir behalten den Namen des folgenden Programms bei translate_imutils.py .
# Importieren Sie die erforderlichen Paketeimportieren taub als z.B.
importieren argparse
importieren unnütz
importieren Lebenslauf2
# Diese Funktion implementiert die Bildübersetzung und
# gibt das übersetzte Bild an die aufrufende Funktion zurück.
def Übersetzen ( Bild , x , Y ) :
Übersetzungsmatrix = z.B. float32 ( [ [ 1 , 0 , x ] , [ 0 , 1 , Y ] ] )
Bild_Übersetzung = Lebenslauf2. warpAffine ( Bild , Übersetzungsmatrix ,
( Bild. Form [ 1 ] , Bild. Form [ 0 ] ) )
Rückkehr Bild_Übersetzung
# Konstruieren Sie den Argument-Parser und parsen Sie die Argumente
ap = argparse. ArgumentParser ( )
ap. add_argument ( '-ich' , '--Bild' , erforderlich = Wahr , Hilfe = 'Weg zum Bild' )
Argumente = Deren ( ap. parse_args ( ) )
# Laden Sie das Bild und zeigen Sie es auf dem Bildschirm an
Bild = Lebenslauf2. imgelesen ( Argumente [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original Bild' , Bild )
Bild_Übersetzung = unnütz. Übersetzen ( Bild , 10 , 70 )
Lebenslauf2. imzeigen ( 'Bildübersetzung nach rechts und unten' ,
Bild_Übersetzung )
Lebenslauf2. WaitKey ( 0 )
Zeilen 9 bis 13: In diesem Abschnitt des Programms findet die Übersetzung statt. Die Translationsmatrix informiert uns, um wie viele Pixel das Bild nach oben oder unten oder nach links oder rechts verschoben wird.
Diese Zeilen wurden bereits erklärt, aber jetzt werden wir eine Funktion namens translate () erstellen und ihr drei verschiedene Parameter schicken. Als erster Parameter dient das Bild selbst. Die x- und y-Werte der Übersetzungsmatrix entsprechen dem zweiten und dritten Parameter.
Notiz Hinweis: Es ist nicht erforderlich, diese Übersetzungsfunktion im Programm zu definieren, da sie bereits im imutils-Bibliothekspaket enthalten ist. Ich habe es innerhalb des Programms zur einfachen Erklärung verwendet. Wir können diese Funktion direkt mit den imutils aufrufen, wie in Zeile 24 gezeigt.
Zeile 24: Das vorherige Programm zeigt, dass wir in Zeile 24 tx = 10 und ty = 70 definieren. Wir verschieben also das Bild um 10 Pixel nach rechts und 70 Pixel nach unten.
In diesem Programm kümmern wir uns nicht um cv2.warpAffine-Funktionen, da sie bereits im imutils-Bibliothekspaket enthalten sind.
Um den vorherigen Code auszuführen, müssen wir den Pfad des Bildes wie unten angegeben angeben:
Ausgabe:
Python-Imutils. py --Bild Eichhörnchen. jpg 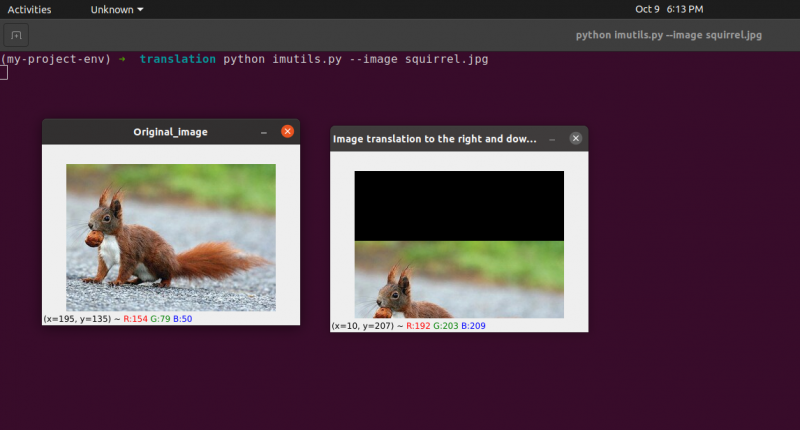
2. Bilddrehung
Wir haben in der vorherigen Lektion (oder einer beliebigen Kombination) besprochen, wie man ein Bild nach oben, unten, links und rechts übersetzt (d. h. verschiebt). Als Nächstes besprechen wir die Rotation in Bezug auf die Bildverarbeitung.
Ein Bild wird in einem als Drehung bekannten Prozess um einen Winkel Theta gedreht. Der Winkel, um den wir das Bild drehen, wird durch Theta dargestellt. Darüber hinaus werde ich später die Funktion zum Drehen von Bildern bereitstellen, um das Drehen von Bildern zu vereinfachen.
Ähnlich wie bei der Translation, und vielleicht nicht überraschend, der Drehung um einen Winkel, wird Theta bestimmt, indem eine Matrix M im folgenden Format erstellt wird:
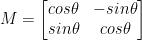
Diese Matrix kann einen Vektor in Theta-Grad (gegen den Uhrzeigersinn) um den Ursprung einer gegebenen (x, y)-kartesischen Ebene drehen. Normalerweise wäre in diesem Szenario der Ursprung der Mittelpunkt des Bildes, aber tatsächlich könnten wir einen beliebigen (x, y) Punkt als unseren Drehmittelpunkt bestimmen.
Das gedrehte Bild R wird dann durch einfache Matrixmultiplikation aus dem Originalbild I erzeugt: R = IM
OpenCV hingegen bietet zusätzlich die Möglichkeit, (1) ein Bild zu skalieren (d. h. die Größe zu ändern) und (2) ein beliebiges Rotationszentrum anzubieten, um die Rotation auszuführen.
Unsere modifizierte Rotationsmatrix M ist unten dargestellt:
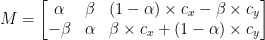
Beginnen wir mit dem Öffnen und Generieren einer neuen Datei namens rotieren.py :
# Importieren der erforderlichen Paketeimportieren taub als z.B.
importieren argparse
importieren unnütz
importieren Lebenslauf2
# Erstellen des argumentparser-Objekts und des Parsing-Arguments
apobj = argparse. ArgumentParser ( )
apobj. add_argument ( '-k' , '--Bild' , erforderlich = Wahr , Hilfe = 'Bildpfad' )
Argumente = Deren ( apobj. parse_args ( ) )
Bild = Lebenslauf2. imgelesen ( Argumente [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original Bild' , Bild )
# Berechnen Sie die Mitte des Bildes anhand der Abmessungen des Bildes.
( Höhe , Breite ) = Bild. Form [ : 2 ]
( ZentrumX , ZentrumY ) = ( Breite / 2 , Höhe / 2 )
# Jetzt drehen wir mit cv2 das Bild um 55 Grad nach
# Ermittle die Rotationsmatrix mit getRotationMatrix2D()
RotationMatrix = Lebenslauf2. getRotationMatrix2D ( ( ZentrumX , ZentrumY ) , 55 , 1.0 )
gedrehtes Bild = Lebenslauf2. warpAffine ( Bild , RotationMatrix , ( Breite , Höhe ) )
Lebenslauf2. imzeigen ( 'Bild um 55 Grad gedreht' , gedrehtes Bild )
Lebenslauf2. WaitKey ( 0 )
# Das Bild wird nun um -85 Grad gedreht.
RotationMatrix = Lebenslauf2. getRotationMatrix2D ( ( ZentrumX , ZentrumY ) , - 85 , 1.0 )
gedrehtes Bild = Lebenslauf2. warpAffine ( Bild , RotationMatrix , ( Breite , Höhe ) )
Lebenslauf2. imzeigen ( 'Bild um -85 Grad gedreht' , gedrehtes Bild )
Lebenslauf2. WaitKey ( 0 )
Zeilen 1 bis 5: Wir importieren alle erforderlichen Pakete für dieses Programm, wie OpenCV, argparser und NumPy. Bitte beachten Sie, dass es eine andere Bibliothek gibt, die imutils ist. Dies ist kein Paket von OpenCV. Dies ist nur eine Bibliothek, die verwendet wird, um die gleiche Bildverarbeitung einfach zu zeigen.
Die Bibliothek imutils wird bei der Installation von OpenCV nicht automatisch eingebunden. OpenCV installiert die imutils. Wir müssen die folgende Methode anwenden:
pip imutils installieren
Zeilen 8 bis 14: Wir haben unseren Agrparser erstellt und unser Image geladen. In diesem Argparser verwenden wir nur ein Bildargument, das uns den Pfad des Bildes mitteilt, das wir in diesem Programm verwenden werden, um die Drehung zu demonstrieren.
Beim Drehen eines Bildes müssen wir den Drehpunkt der Drehung definieren. Meistens möchten Sie ein Bild um seine Mitte drehen, aber OpenCV ermöglicht es Ihnen, stattdessen einen beliebigen Punkt auszuwählen. Drehen wir das Bild einfach um seinen Mittelpunkt.
Zeilen 17 bis 18 Nehmen Sie die Breite bzw. Höhe des Bildes und teilen Sie dann jede Dimension durch zwei, um die Mitte des Bildes festzulegen.
Wir konstruieren eine Matrix, um ein Bild zu drehen, genauso wie wir eine Matrix definiert haben, um ein Bild zu verschieben. Wir rufen einfach an cv2.getRotationMatrix2D Funktion auf Zeile 22, anstatt die Matrix manuell mit NumPy zu erstellen (was etwas umständlich sein kann).
Das cv2.getRotationMatrix2D Funktion erfordert drei Parameter. Die erste Eingabe ist der gewünschte Rotationswinkel (in diesem Fall die Bildmitte). Theta wird dann verwendet, um anzugeben, um wie viel Grad (gegen den Uhrzeigersinn) das Bild gedreht wird. Hier drehen wir das Bild um 45 Grad. Die letzte Option bezieht sich auf die Größe des Bildes.
Unabhängig davon, dass wir das Skalieren eines Bildes noch nicht besprochen haben, können Sie hier eine Fließkommazahl mit 1,0 angeben, die angibt, dass das Bild in seinen ursprünglichen Proportionen verwendet werden soll. Wenn Sie jedoch einen Wert von 2,0 eingeben, wird das Bild doppelt so groß. Eine Zahl von 0,5 reduziert die Bildgröße so.
Zeile 22 bis 23: Nach Erhalt unserer Rotationsmatrix M von der cv2.getRotationMatrix2D Funktion drehen wir unser Bild mit der cv2.warpAffine Technik in Zeile 23. Die erste Eingabe der Funktion ist das Bild, das wir drehen möchten. Breite und Höhe unseres Ausgabebildes werden dann zusammen mit unserer Rotationsmatrix M definiert. In Zeile 23 wird das Bild dann um 55 Grad gedreht.
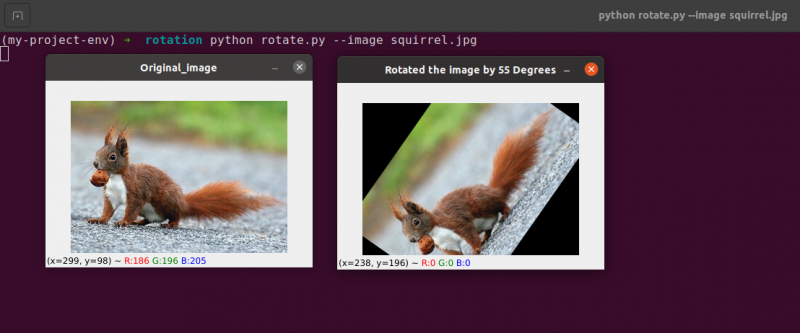
Sie können feststellen, dass unser Bild gedreht wurde.
Zeilen 28 bis 30 bilden die zweite Rotation. Die Zeilen 22–23 des Codes sind identisch, außer dass wir diesmal um -85 Grad statt um 55 Grad drehen.
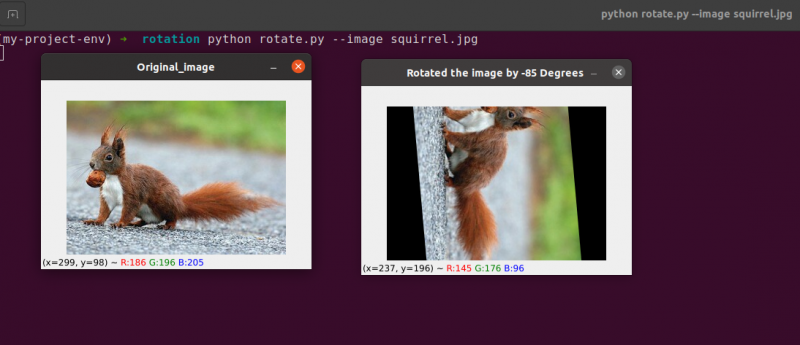
Bis zu diesem Punkt haben wir ein Bild einfach um seinen Mittelpunkt gedreht. Was wäre, wenn wir das Bild um einen zufälligen Punkt drehen wollten?
Beginnen wir mit dem Öffnen und Generieren einer neuen Datei namens rotieren.py:
# Importieren der erforderlichen Paketeimportieren taub als z.B.
importieren argparse
importieren unnütz
importieren Lebenslauf2
# Erstellen des argumentparser-Objekts und des Parsing-Arguments
ap_obj = argparse. ArgumentParser ( )
ap_obj. add_argument ( '-k' , '--Bild' , erforderlich = Wahr , Hilfe = 'Bildpfad' )
Streit = Deren ( ap_obj. parse_args ( ) )
# Laden Sie das Bild und zeigen Sie es auf dem Bildschirm an
Bild = Lebenslauf2. imgelesen ( Streit [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original Bild' , Bild )
# Berechnen Sie die Mitte des Bildes anhand der Abmessungen des Bildes.
( Höhe , Breite ) = Bild. Form [ : 2 ]
( ZentrumX , ZentrumY ) = ( Breite / 2 , Höhe / 2 )
# Jetzt drehen wir mit cv2 das Bild um 55 Grad nach
# Ermittle die Rotationsmatrix mit getRotationMatrix2D()
RotationMatrix = Lebenslauf2. getRotationMatrix2D ( ( ZentrumX , ZentrumY ) , 55 , 1.0 )
gedrehtes Bild = Lebenslauf2. warpAffine ( Bild , RotationMatrix , ( Breite , Höhe ) )
Lebenslauf2. imzeigen ( 'Bild um 55 Grad gedreht' , gedrehtes Bild )
Lebenslauf2. WaitKey ( 0 )
# Das Bild wird nun um -85 Grad gedreht.
RotationMatrix = Lebenslauf2. getRotationMatrix2D ( ( ZentrumX , ZentrumY ) , - 85 , 1.0 )
gedrehtes Bild = Lebenslauf2. warpAffine ( Bild , RotationMatrix , ( Breite , Höhe ) )
Lebenslauf2. imzeigen ( 'Bild um -85 Grad gedreht' , gedrehtes Bild )
Lebenslauf2. WaitKey ( 0 )
# Bildrotation von einem beliebigen Punkt, nicht von der Mitte
RotationMatrix = Lebenslauf2. getRotationMatrix2D ( ( ZentrumX - 40 , ZentrumY - 40 ) , 55 , 1.0 )
gedrehtes Bild = Lebenslauf2. warpAffine ( Bild , RotationMatrix , ( Breite , Höhe ) )
Lebenslauf2. imzeigen ( 'Bilddrehung von beliebigen Punkten aus' , gedrehtes Bild )
Lebenslauf2. WaitKey ( 0 )
Zeile 34 bis 35: Nun, dieser Code sollte zum Drehen eines Objekts ziemlich üblich erscheinen. Um das Bild um einen Punkt zu drehen, der 40 Pixel nach links und 40 Pixel über seiner Mitte liegt, weisen wir die an cv2.getRotationMatrix2D Funktion, um auf ihren ersten Parameter zu achten.
Das Bild, das entsteht, wenn wir diese Drehung anwenden, wird unten gezeigt:
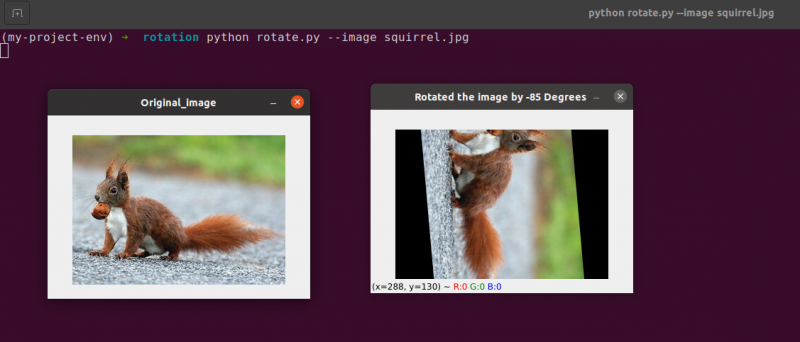
Wir können deutlich sehen, dass das Rotationszentrum jetzt die (x, y)-Koordinate ist, die 40 Pixel links und 40 Pixel über dem berechneten Mittelpunkt des Bildes liegt.
3. Bildarithmetik
Tatsächlich ist die Bildarithmetik nur eine Matrixaddition mit einigen zusätzlichen Einschränkungen für Datentypen, die wir später behandeln werden.
Nehmen wir uns einen Moment Zeit, um einige hübsche Grundlagen der linearen Algebra durchzugehen.
Erwägen Sie, die nächsten beiden Matrizen zu kombinieren:
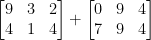
Welches Ergebnis würde die Matrixaddition ergeben? Die einfache Antwort ist die Summe der Matrixeinträge, Element für Element:
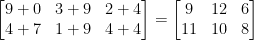
Einfach genug, oder?
Wir alle verstehen zu diesem Zeitpunkt die grundlegenden Operationen der Addition und Subtraktion. Bei der Arbeit mit Bildern müssen wir jedoch die Einschränkungen beachten, die durch unseren Farbraum und Datentyp auferlegt werden.
Pixel in RGB-Bildern liegen beispielsweise zwischen [0, 255]. Was passiert, wenn wir versuchen, 10 zu einem Pixel mit einer Intensität von 250 hinzuzufügen, während wir es betrachten?
Wir würden auf einen Wert von 260 kommen, wenn wir die üblichen arithmetischen Prinzipien anwenden würden. 260 ist kein gültiger Wert, da RGB-Bilder als 8-Bit-Ganzzahlen ohne Vorzeichen dargestellt werden.
Was soll also passieren? Sollten wir eine Überprüfung durchführen, um sicherzustellen, dass kein Pixel außerhalb des Bereichs von [0, 255] liegt, und jedes Pixel auf einen Wert zwischen 0 und 255 beschneiden?
Oder „wickeln wir um“ und führen eine Modulo-Operation durch? Die Addition von 10 zu 255 ergäbe nach den Modulregeln gerade mal einen Wert von 9.
Wie sollten Additionen und Subtraktionen zu Bildern jenseits des Bereichs von [0, 255] gehandhabt werden?
Die Wahrheit ist, dass es keine richtige oder falsche Technik gibt; es hängt alles davon ab, wie Sie mit Ihren Pixeln arbeiten und was Sie erreichen möchten.
Denken Sie jedoch daran, dass es Unterschiede zwischen der Addition in OpenCV und der Addition in NumPy gibt. Modularithmetik und „Wrap Around“ werden von NumPy durchgeführt. Im Gegensatz dazu führt OpenCV das Clipping aus und stellt sicher, dass Pixelwerte niemals den Bereich [0, 255] verlassen.
Beginnen wir mit dem Erstellen einer neuen Datei mit dem Namen arithmetik.py und öffnen:
# python arithmetic.py --image eichhörnchen.jpg# Importieren der erforderlichen Pakete
importieren taub als z.B.
importieren argparse
importieren unnütz
importieren Lebenslauf2
# Erstellen des argumentparser-Objekts und des Parsing-Arguments
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-k' , '--Bild' , erforderlich = Wahr , Hilfe = 'Bildpfad' )
Argumente = Deren ( apObj. parse_args ( ) )
Bild = Lebenslauf2. imgelesen ( Argumente [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original Bild' , Bild )
'''
Die Werte unserer Pixel liegen im Bereich [0, 255]
da Bilder NumPy-Arrays sind, die als vorzeichenlose 8-Bit-Ganzzahlen gespeichert werden.
Bei der Verwendung von Funktionen wie cv2.add und cv2.subtract werden Werte abgeschnitten
zu diesem Bereich, auch wenn sie von außerhalb hinzugefügt oder abgezogen werden
[0, 255] Bereich. Hier ist eine Abbildung:
'''
drucken ( 'maximal 255: {}' . Format ( Str ( Lebenslauf2. addieren ( z.B. uint8 ( [ 201 ] ) ,
z.B. uint8 ( [ 100 ] ) ) ) ) )
drucken ( 'Minimum 0: {}' . Format ( Str ( Lebenslauf2. subtrahieren ( z.B. uint8 ( [ 60 ] ) ,
z.B. uint8 ( [ 100 ] ) ) ) ) )
'''
Wenn Sie mit diesen Arrays mit NumPy arithmetische Operationen durchführen,
Der Wert wird umbrochen, anstatt auf den abgeschnitten zu werden
[0, 255]Bereich. Bei der Verwendung von Bildern ist dies unbedingt einzuhalten
im Kopf.
'''
drucken ( 'Umbruch: {}' . Format ( Str ( z.B. uint8 ( [ 201 ] ) + z.B. uint8 ( [ 100 ] ) ) ) )
drucken ( 'Umbruch: {}' . Format ( Str ( z.B. uint8 ( [ 60 ] ) - z.B. uint8 ( [ 100 ] ) ) ) )
'''
Lassen Sie uns die Helligkeit jedes Pixels in unserem Bild mit 101 multiplizieren.
Dazu generieren wir ein NumPy-Array in der gleichen Größe wie unsere Matrix,
mit Einsen gefüllt und mit 101 multipliziert, um ein gefülltes Array zu erzeugen
mit 101s. Schließlich führen wir die beiden Bilder zusammen.
Sie werden feststellen, dass das Bild jetzt „heller“ ist.
'''
Matrix = z.B. Einsen ( Bild. Form , dtyp = 'uint8' ) * 101
image_added = Lebenslauf2. addieren ( Bild , Matrix )
Lebenslauf2. imzeigen ( 'Bildergebnis hinzugefügt' , image_added )
#In ähnlicher Weise können wir unser Bild durch Aufnehmen dunkler machen
# 60 von allen Pixeln entfernt.
Matrix = z.B. Einsen ( Bild. Form , dtyp = 'uint8' ) * 60
image_subtracted = Lebenslauf2. subtrahieren ( Bild , Matrix )
Lebenslauf2. imzeigen ( 'Subtrahiertes Bildergebnis' , image_subtracted )
Lebenslauf2. WaitKey ( 0 )
Zeilen 1 bis 16 wird verwendet, um unseren normalen Prozess auszuführen, der das Importieren unserer Pakete, das Konfigurieren unseres Argumentparsers und das Laden unseres Bildes beinhaltet.
Erinnern Sie sich, wie ich zuvor den Unterschied zwischen OpenCV und NumPy-Zusatz besprochen habe? Nachdem wir es nun gründlich behandelt haben, schauen wir uns einen bestimmten Fall an, um sicherzustellen, dass wir es verstehen.
Zwei 8-Bit-Integer-NumPy-Arrays ohne Vorzeichen sind definiert Zeile 26 . Ein Wert von 201 ist das einzige Element im ersten Array. Obwohl sich nur ein Mitglied im zweiten Array befindet, hat es einen Wert von 100. Die Werte werden dann mit der cv2.add-Funktion von OpenCV hinzugefügt.
Was erwarten Sie als Ergebnis?
Nach herkömmlichen arithmetischen Prinzipien müsste die Antwort 301 lauten. Aber denken Sie daran, dass wir es mit 8-Bit-Ganzzahlen ohne Vorzeichen zu tun haben, die nur im Bereich [0, 255] liegen können. Da wir die cv2.add-Methode verwenden, verarbeitet OpenCV das Clipping und stellt sicher, dass die Addition nur ein maximales Ergebnis von 255 zurückgibt.
Die erste Zeile der folgenden Auflistung zeigt das Ergebnis der Ausführung dieses Codes:
Arithmetik. pymaximal 255 : [ [ 255 ] ]
Die Summe ergab tatsächlich eine Zahl von 255.
Anschließend Zeile 26 verwendet cv2.subtract, um eine Subtraktion durchzuführen. Wieder definieren wir zwei 8-Bit-NumPy-Arrays mit vorzeichenlosen Ganzzahlen mit jeweils einem einzigen Element. Der Wert des ersten Arrays ist 60, während der Wert des zweiten Arrays 100 ist.
Unsere Arithmetik schreibt vor, dass die Subtraktion einen Wert von -40 ergeben sollte, aber OpenCV übernimmt das Clipping erneut für uns. Wir stellen fest, dass der Wert auf 0 getrimmt wurde. Unser Ergebnis unten zeigt dies:
Arithmetik. pymindestens 0 : [ [ 0 ] ]
Subtrahieren Sie mit cv2 100 von 60 subtract, was den Wert 0 ergibt.
Aber was passiert, wenn wir NumPy anstelle von OpenCV verwenden, um die Berechnungen durchzuführen?
Linien 38 und 39 dieses Problem ansprechen.
Zunächst werden zwei vorzeichenlose 8-Bit-Integer-NumPy-Arrays mit jeweils einem einzelnen Element definiert. Der Wert des ersten Arrays ist 201, während der Wert des zweiten Arrays 100 ist. Unsere Addition würde gekürzt und ein Wert von 255 zurückgegeben, wenn wir die Funktion cv2.add verwenden würden.
NumPy hingegen 'wickelt herum' und führt Modulo-Arithmetik statt Clipping durch. NumPy springt auf Null, sobald ein Wert von 255 erreicht ist, und zählt dann weiter, bis 100 Schritte erreicht sind. Dies wird durch die erste Zeile der Ausgabe bestätigt, die unten gezeigt wird:
Arithmetik. pyumwickeln: [ Vier fünf ]
Dann werden zwei weitere NumPy-Arrays definiert, eines mit einem Wert von 50 und das andere mit 100. Diese Subtraktion würde durch die cv2.subtract-Methode getrimmt, um ein Ergebnis von 0 zurückzugeben. Wir sind uns jedoch bewusst, dass NumPy ausgeführt wird, anstatt es zu beschneiden Modulo-Arithmetik. Stattdessen laufen die Modulo-Prozeduren um und beginnen rückwärts von 255 zu zählen, sobald 0 während der Subtraktion erreicht wird. Wir können dies aus der folgenden Ausgabe sehen:
Arithmetik. pyumwickeln: [ 207 ]
Noch einmal zeigt unsere Terminalausgabe den Unterschied zwischen Clipping und Wraparound:
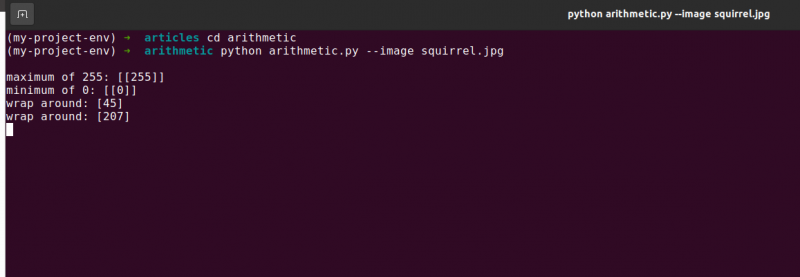
Es ist wichtig, dass Sie Ihr gewünschtes Ergebnis im Hinterkopf behalten, wenn Sie ganzzahlige Arithmetik durchführen. Sollen Werte außerhalb des Bereichs [0, 255] abgeschnitten werden? Verwenden Sie danach die integrierten Bildarithmetiktechniken von OpenCV.
Möchten Sie, dass Werte umgebrochen werden, wenn sie außerhalb des Bereichs von [0, 255] und Modulo-Arithmetikoperationen liegen? Die NumPy-Arrays werden dann einfach wie gewohnt addiert und subtrahiert.
Zeile 48 definiert ein eindimensionales NumPy-Array mit den gleichen Abmessungen wie unser Bild. Auch hier stellen wir sicher, dass unser Datentyp 8-Bit-Ganzzahlen ohne Vorzeichen ist. Wir multiplizieren einfach unsere Matrix aus einstelligen Werten mit 101, um sie mit Werten von 101 statt 1 zu füllen. Schließlich verwenden wir die Funktion cv2.add, um unsere Matrix aus 100ern zum Originalbild hinzuzufügen. Dadurch wird die Intensität jedes Pixels um 101 erhöht und gleichzeitig sichergestellt, dass alle Werte, die versuchen, 255 zu überschreiten, auf den Bereich [0, 255] begrenzt werden.
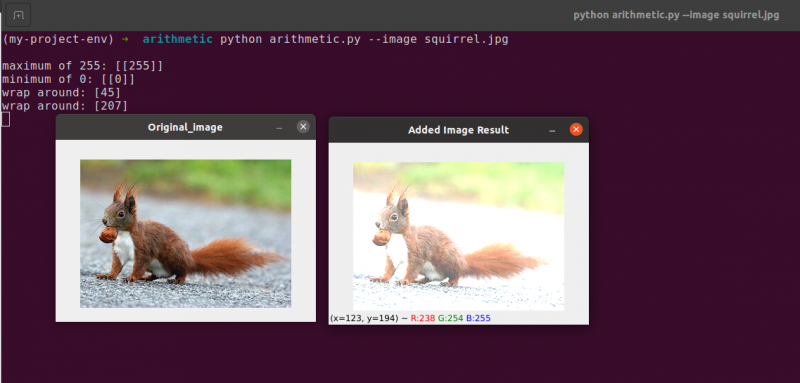
Beachten Sie, wie das Bild merklich heller und „verwaschener“ erscheint als das Original. Dies liegt daran, dass wir Pixel zu helleren Farben treiben, indem wir ihre Pixelintensitäten um 101 erhöhen.
Um 60 von jeder Pixelintensität des Bildes zu subtrahieren, erstellen wir zuerst ein zweites NumPy-Array auf Zeile 54, das mit den 60ern gefüllt ist.
Die Ergebnisse dieser Subtraktion sind im folgenden Bild dargestellt:
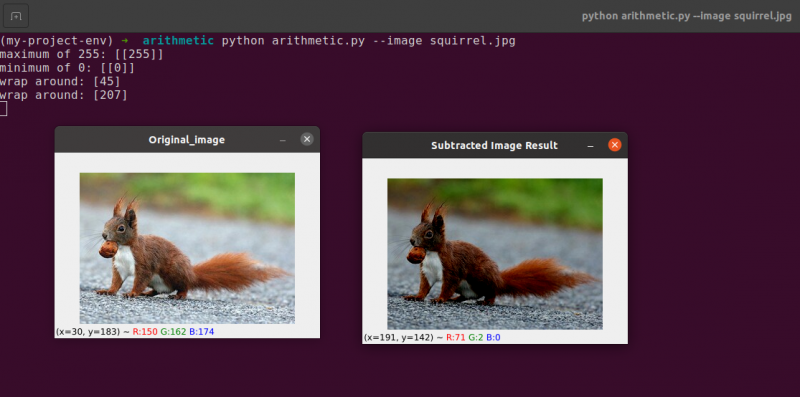
Die Gegenstände um uns herum erscheinen deutlich dunkler als zuvor. Das liegt daran, dass wir durch das Subtrahieren von 60 von jedem Pixel die Pixel im RGB-Farbraum in die dunkleren Regionen verschieben.
4. Bildspiegelung
Ähnlich wie bei der Drehung ist das Spiegeln eines Bildes um seine x- oder y-Achse eine weitere Option, die OpenCV anbietet. Auch wenn Wendeoperationen nicht so häufig verwendet werden, ist es aus verschiedenen Gründen, die Sie vielleicht nicht sofort erkennen, unglaublich vorteilhaft, sie zu kennen.
Wir entwickeln einen Klassifikator für maschinelles Lernen für ein kleines Startup-Unternehmen, das versucht, Gesichter in Bildern zu identifizieren. Damit unser System „lernt“, was ein Gesicht ist, bräuchten wir eine Art Datensatz mit Mustergesichtern. Leider hat uns das Unternehmen nur einen kleinen Datensatz von 40 Gesichtern gegeben, und wir können keine weiteren Informationen sammeln.
Was tun wir dann?
Da ein Gesicht ein Gesicht bleibt, ob gespiegelt oder nicht, können wir jedes Bild eines Gesichts horizontal spiegeln und die gespiegelten Versionen als zusätzliche Trainingsdaten verwenden.
Dieses Beispiel mag dumm und künstlich erscheinen, ist es aber nicht. Flipping ist eine bewusste Strategie, die von starken Deep-Learning-Algorithmen verwendet wird, um während der Trainingsphase mehr Daten zu produzieren.
Aus dem Vorhergehenden geht hervor, dass die Bildverarbeitungsmethoden, die Sie in diesem Modul lernen, als Grundlage für größere Computer-Vision-Systeme dienen.
Ziele:
Verwendung der cv2.flip In dieser Sitzung lernen Sie, wie Sie ein Bild sowohl horizontal als auch vertikal spiegeln.
Spiegeln ist die nächste Bildmanipulation, die wir untersuchen werden. Die x- und y-Achsen eines Bildes können gespiegelt werden oder sogar beides. Bevor wir in die Codierung eintauchen, ist es am besten, sich zuerst die Ergebnisse eines Bildwechsels anzusehen. Sehen Sie sich ein Bild an, das im folgenden Bild horizontal gespiegelt wurde:
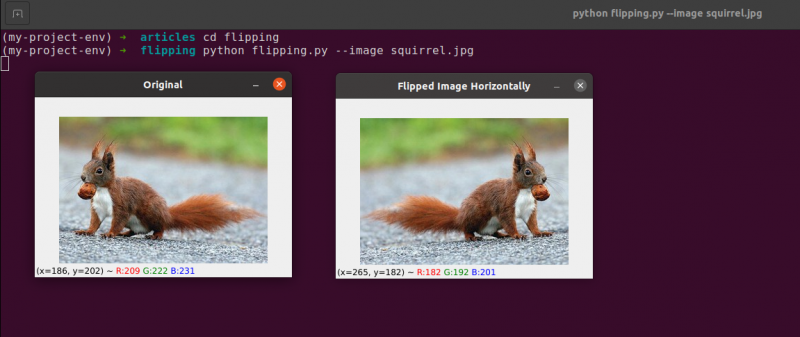
Beachten Sie, wie unser Originalbild auf der linken Seite ist und wie das Bild auf der rechten Seite horizontal gespiegelt wurde.
Beginnen wir mit dem Erstellen einer neuen Datei mit dem Namen flipping.py .
Sie haben ein Beispiel für einen Bildwechsel gesehen, also schauen wir uns den Code an:
# python flipping.py --image quirrel.jpg# Importieren der erforderlichen Pakete
importieren argparse
importieren Lebenslauf2
# Erzeuge das Objekt des Argument-Parsers und parse das Argument
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-ich' , '--Bild' , erforderlich = Wahr , Hilfe = 'Bildpfad' )
Streit = Deren ( apObj. parse_args ( ) )
Bild = Lebenslauf2. imgelesen ( Streit [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original' , Bild )
# Bild horizontal spiegeln
Bild umgedreht = Lebenslauf2. kippen ( Bild , 1 )
Lebenslauf2. imzeigen ( „Bild horizontal gespiegelt“ , Bild umgedreht )
# Bild vertikal spiegeln
Bild umgedreht = Lebenslauf2. kippen ( Bild , 0 )
Lebenslauf2. imzeigen ( 'Bild vertikal gespiegelt' , Bild umgedreht )
# Bildspiegelung entlang beider Achsen
Bild umgedreht = Lebenslauf2. kippen ( Bild , - 1 )
Lebenslauf2. imzeigen ( 'Horizontal und vertikal gespiegelt' , Bild umgedreht )
Lebenslauf2. WaitKey ( 0 )
Die Schritte, die wir unternehmen, um unsere Pakete zu importieren, unsere Eingaben zu parsen und unser Image von der Festplatte zu laden, werden in l behandelt Zeilen 1 bis 12 .
Durch Aufruf der Funktion cv2.flip on Zeile 15 , ist es einfach, ein Bild horizontal zu spiegeln. Das Bild, das wir umdrehen möchten, und ein bestimmter Code oder ein Flag, das angibt, wie das Bild umgedreht werden soll, sind die beiden Argumente, die für die Methode cv2.flip benötigt werden.
Ein Flip-Code-Wert von 1 bedeutet, dass wir das Bild um die y-Achse drehen, um es horizontal zu spiegeln ( Zeile 15 ). Wenn wir einen Flip-Code von 0 angeben, möchten wir das Bild um die x-Achse drehen ( Zeile 19 ). Ein negativer Flipcode ( Zeile 23 ) dreht das Bild um beide Achsen.
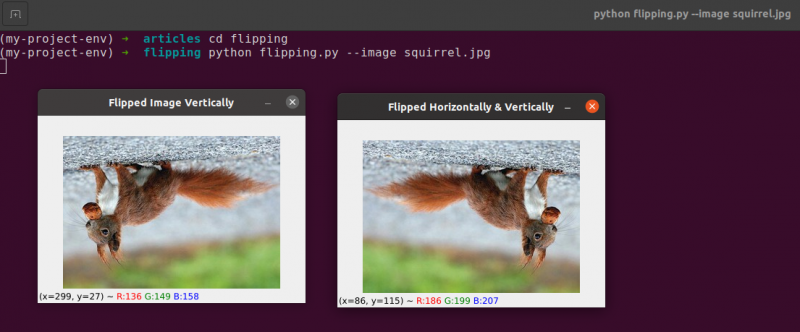
Eines der einfachsten Beispiele zu diesem Thema ist das Spiegeln eines Bildes, was grundlegend ist.
Als Nächstes besprechen wir das Zuschneiden von Bildern und verwenden NumPy-Array-Slices, um bestimmte Bildteile zu extrahieren.
5. Bildausschnitt
Zuschneiden ist, wie der Name schon sagt, der Prozess des Auswählens und Entfernens der Region of Interest (oder einfach ROI), die der Bereich des Bildes ist, der uns interessiert.
Das Gesicht müsste für eine Gesichtserkennungsanwendung aus einem Bild ausgeschnitten werden. Wenn wir außerdem ein Python-Skript erstellen, um Hunde in Bildern zu finden, möchten wir den Hund möglicherweise aus dem Bild ausschneiden, wenn wir ihn finden.
Ziele: Unser Hauptziel ist es, sich mit NumPy-Array-Slicing vertraut zu machen und sich damit vertraut zu machen, um Bereiche aus einem Bild zuzuschneiden.
Zuschneiden : Wenn wir ein Bild zuschneiden, ist es unser Ziel, die äußeren Elemente zu eliminieren, die uns nicht interessieren. Der Prozess der Auswahl unseres ROI wird oft als Auswahl unserer Interessenregion bezeichnet.
Erstellen Sie eine neue Datei mit dem Namen crop.py , öffnen Sie es und fügen Sie den folgenden Code hinzu:
# python crop.py# Importieren der erforderlichen Pakete
importieren Lebenslauf2
# Bild laden und auf dem Bildschirm anzeigen
Bild = Lebenslauf2. imgelesen ( 'Eichhörnchen.jpg' )
drucken ( Bild. Form )
Lebenslauf2. imzeigen ( 'Original' , Bild )
# NumPy-Array-Slices werden verwendet, um ein Bild schnell zu trimmen
# Wir werden das Eichhörnchengesicht aus dem Bild zuschneiden
Eichhörnchengesicht = Bild [ 35 : 90 , 35 : 100 ]
Lebenslauf2. imzeigen ( 'Eichhörnchengesicht' , Eichhörnchengesicht )
Lebenslauf2. WaitKey ( 0 )
# Und jetzt werden wir hier den ganzen Körper beschneiden
# des Eichhörnchens
Eichhörnchen = Bild [ 35 : 148 , 23 : 143 ]
Lebenslauf2. imzeigen ( 'Eichhörnchenkörper' , Eichhörnchen )
Lebenslauf2. WaitKey ( 0 )
Wir zeigen das Zuschneiden in Python und OpenCV anhand eines Bildes, das wir von der Festplatte laden Linie 5 und 6 .

Originalbild, das wir zuschneiden werden
Wir verwenden nur grundlegende Zuschneidetechniken und zielen darauf ab, das Eichhörnchengesicht und den Eichhörnchenkörper von der Umgebung zu trennen.
Wir werden unser Vorwissen über das Bild nutzen und die NumPy-Array-Schnitte manuell bereitstellen, in denen der Körper und das Gesicht vorhanden sind. Unter normalen Bedingungen würden wir im Allgemeinen maschinelles Lernen und Computer-Vision-Algorithmen einsetzen, um das Gesicht und den Körper im Bild zu erkennen. Aber lassen Sie uns die Dinge vorerst einfach halten und auf den Einsatz von Erkennungsmodellen verzichten.
Wir können das Gesicht im Bild mit nur einer Codezeile identifizieren. Zeile 13 , Um einen rechteckigen Teil des Bildes zu extrahieren, beginnend bei (35, 35), stellen wir NumPy-Array-Slices (90, 100) bereit. Es mag verwirrend erscheinen, dass wir den Zuschnitt mit den Indizes in der Reihenfolge „Höhe zuerst“ und „Breite zweite“ füttern, aber denken Sie daran, dass OpenCV Bilder als NumPy-Arrays speichert. Daher müssen wir die Werte für die y-Achse vor der x-Achse liefern.
NumPy benötigt die folgenden vier Indizes, um unser Zuschneiden durchzuführen:
Beginn y: Die y-Koordinate am Anfang. Für dieses Beispiel beginnen wir bei y=35.
Ende y: Die y-Koordinate am Ende. Unsere Ernte wird aufhören, wenn y = 90 ist.
Beginn x: Die X-Koordinate des Slice-Anfangs. Der Zuschnitt beginnt bei x=35.
Ende x: Die X-Achsen-Endkoordinate des Segments. Bei x=100 ist unser Slice fertig.
In ähnlicher Weise beschneiden wir die Regionen (23, 35) und (143, 148) aus dem Originalbild, um den gesamten Körper aus dem Bild zu extrahieren Zeile 19 .
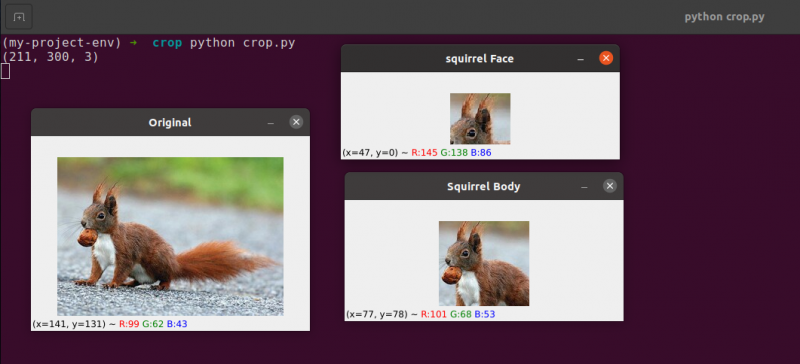
Sie können sehen, dass das Bild beschnitten wurde, um nur den Körper und das Gesicht zu zeigen.
6. Bildgröße ändern
Das Vergrößern oder Verkleinern der Breite und Höhe eines Bildes wird als Skalierung oder einfach als Größenänderung bezeichnet. Das Seitenverhältnis, also das Verhältnis der Breite eines Bildes zu seiner Höhe, sollte bei der Größenänderung eines Bildes berücksichtigt werden. Die Vernachlässigung des Seitenverhältnisses kann dazu führen, dass skalierte Bilder komprimiert und verzerrt erscheinen:
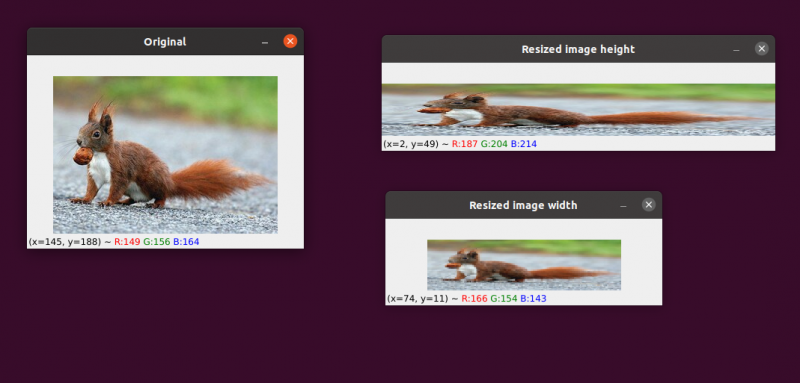
Unser Anfangsbild ist auf der linken Seite. Auf der rechten Seite sehen Sie zwei Bilder, die ohne Beibehaltung des Seitenverhältnisses skaliert wurden, wodurch das Verhältnis der Breite des Bildes zu seiner Höhe verzerrt wird. Wenn Sie die Größe Ihrer Bilder ändern, sollten Sie im Allgemeinen das Seitenverhältnis berücksichtigen.
Die von unserem Größenänderungsalgorithmus verwendete Interpolationstechnik muss auch das Ziel der Interpolationsfunktion berücksichtigen, diese Nachbarschaften von Pixeln zu verwenden, um die Bildgröße entweder zu vergrößern oder zu verkleinern.
Im Allgemeinen ist es viel effektiver, die Größe des Bildes zu verkleinern. Dies liegt daran, dass das Entfernen von Pixeln aus einem Bild alles ist, was die Interpolationsfunktion tun muss. Andererseits müsste das Interpolationsverfahren die Lücken zwischen Pixeln füllen, die zuvor nicht vorhanden waren, wenn die Bildgröße erhöht werden sollte.
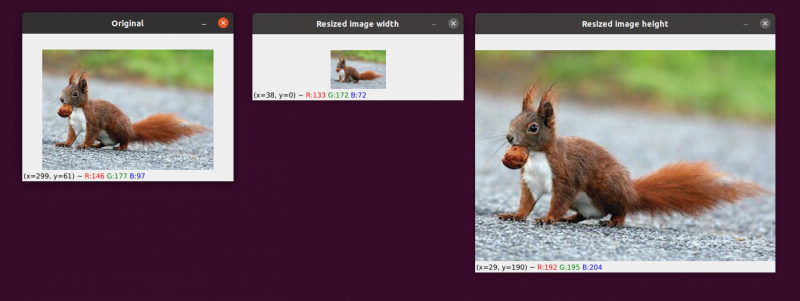
Wir haben unser Originalbild auf der linken Seite. Das Bild wurde in der Mitte auf die Hälfte seiner ursprünglichen Größe verkleinert, aber ansonsten hat es keinen Verlust an „Qualität“ des Bildes gegeben. Trotzdem wurde die Größe des Bildes auf der rechten Seite erheblich vergrößert. Es erscheint jetzt „aufgeblasen“ und „verpixelt“.
Wie ich bereits erwähnt habe, möchten Sie die Größe eines Bildes normalerweise verringern, anstatt es zu vergrößern. Durch die Reduzierung der Bildgröße analysieren wir weniger Pixel und müssen mit weniger „Rauschen“ umgehen, was die Bildverarbeitungsalgorithmen schneller und präziser macht.
Translation und Rotation sind die beiden bisher angesprochenen Bildtransformationen. Wir werden nun untersuchen, wie man die Größe eines Bildes ändert.
Es überrascht nicht, dass wir die Größe unserer Bilder mit der cv2.resize-Methode ändern. Wie ich bereits angedeutet habe, müssen wir bei der Verwendung dieser Methode das Seitenverhältnis des Bildes berücksichtigen. Aber bevor wir zu tief in die Einzelheiten einsteigen, gestatten Sie mir, Ihnen eine Veranschaulichung zu geben:
# python resize.py --image eichhörnchen.jpg# Importieren der erforderlichen Pakete
importieren argparse
importieren Lebenslauf2
# Erzeuge das Objekt des Argument-Parsers und parse das Argument
apObj = argparse. ArgumentParser ( )
apObj. add_argument ( '-k' , '--Bild' , erforderlich = Wahr , Hilfe = 'Bildpfad' )
Argumente = Deren ( apObj. parse_args ( ) )
# Laden Sie das Bild und zeigen Sie es auf dem Bildschirm an
Bild = Lebenslauf2. imgelesen ( Argumente [ 'Bild' ] )
Lebenslauf2. imzeigen ( 'Original' , Bild )
# Um zu verhindern, dass das Bild verzerrt erscheint, Seitenverhältnis
# muss berücksichtigt oder verformt werden; deshalb finden wir heraus, was
# das Verhältnis des neuen Bildes zum aktuellen Bild.
# Machen wir die Breite unseres neuen Bildes auf 160 Pixel.
Aspekt = 160,0 / Bild. Form [ 1 ]
Abmessungen = ( 160 , int ( Bild. Form [ 0 ] * Aspekt ) )
# Diese Zeile zeigt die tatsächlichen Größenänderungen an
verkleinertes Bild = Lebenslauf2. Größe ändern ( Bild , Abmessungen , Interpolation = Lebenslauf2. INTER_AREA )
Lebenslauf2. imzeigen ( 'Bildbreite angepasst' , verkleinertes Bild )
# Was wäre, wenn wir die Höhe des Bildes ändern wollten? - Verwendung der
# Gleiches Prinzip, wir können das Seitenverhältnis basierend berechnen
# eher auf Höhe als auf Breite. Lassen Sie uns die Skala machen
# Bildhöhe 70 Pixel.
Aspekt = 70.0 / Bild. Form [ 0 ]
Abmessungen = ( int ( Bild. Form [ 1 ] * Aspekt ) , 70 )
# Führen Sie die Größenänderung durch
verkleinertes Bild = Lebenslauf2. Größe ändern ( Bild , Abmessungen , Interpolation = Lebenslauf2. INTER_AREA )
Lebenslauf2. imzeigen ( „Bildhöhe angepasst“ , verkleinertes Bild )
Lebenslauf2. WaitKey ( 0 )
Zeilen 1-14 , Nachdem wir unsere Pakete importiert und unseren Argument-Parser konfiguriert haben, werden wir unser Bild laden und anzeigen.
Zeilen 20 und 21: In diesen Zeilen beginnt die jeweilige Codierung . Bei der Größenänderung muss das Seitenverhältnis des Bildes berücksichtigt werden. Das Verhältnis zwischen Breite und Höhe des Bildes wird als Seitenverhältnis bezeichnet.
Höhe Breite ist das Seitenverhältnis.
Wenn wir das Seitenverhältnis nicht berücksichtigen, werden die Ergebnisse unserer Größenänderung verzerrt.
An Zeile 20 , wird die Berechnung des Größenverhältnisses durchgeführt. Wir geben die Breite unseres neuen Bildes als 160 Pixel in dieser Codezeile an. Wir definieren unser Verhältnis (Aspectratio) einfach als die neue Breite (160 Pixel) dividiert durch die alte Breite, auf die wir mit image zugreifen, um das Verhältnis der neuen Höhe zur alten Höhe zu berechnen. Form[1].
Die neuen Dimensionen des Bildes auf Zeile 21 kann nun berechnet werden, da wir unser Verhältnis kennen. Das neue Bild hat wieder eine Breite von 160 Pixel. Nachdem wir die alte Höhe mit unserem Verhältnis multipliziert und das Ergebnis in eine Ganzzahl umgewandelt haben, wird die Höhe berechnet. Wir können das ursprüngliche Seitenverhältnis des Bildes beibehalten, indem wir diesen Vorgang ausführen.
Zeile 24 Hier wird die Größe des Bildes wirklich geändert. Das Bild, dessen Größe geändert werden soll, ist das erste Argument, und das zweite sind die Abmessungen, die wir für das neue Bild berechnet haben. Unsere Interpolationsmethode, also der Algorithmus zur Größenänderung des eigentlichen Bildes, ist der letzte Parameter.
Endlich weiter Zeile 25 , zeigen wir unser skaliertes Bild an.
Wir definieren unser Seitenverhältnis (Aspectratio) neu Zeile 31 . Die Höhe unseres neuen Bildes beträgt 70 Pixel. Wir teilen 70 durch die ursprüngliche Höhe, um das neue Verhältnis von Höhe zu ursprünglicher Höhe zu erhalten.
Als nächstes legen wir die Abmessungen des neuen Bildes fest. Das neue Bild wird eine bereits bekannte Höhe von 70 Pixel haben. Wir können das ursprüngliche Seitenverhältnis des Bildes wieder beibehalten, indem wir die alte Breite mit dem Verhältnis multiplizieren, um die neue Breite zu erhalten.
Das Bild wird dann tatsächlich weiter verkleinert Zeile 35 , und es wird angezeigt Zeile 36.
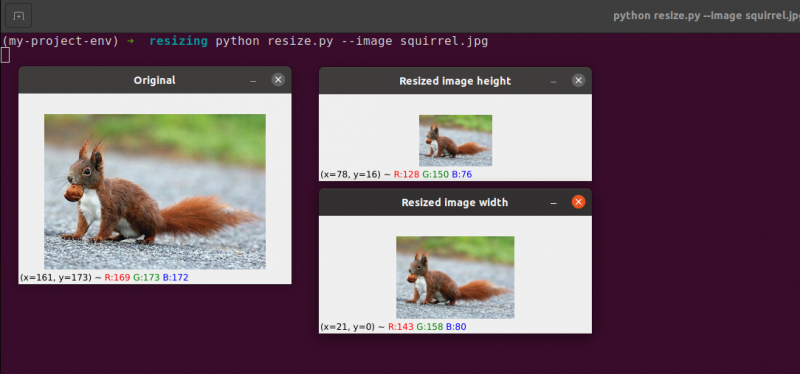
Hier können wir sehen, dass wir die Breite und Höhe unseres Originalbildes reduziert haben, während das Seitenverhältnis beibehalten wurde. Unser Bild würde verzerrt erscheinen, wenn das Seitenverhältnis nicht beibehalten würde.
Fazit
In diesem Blog haben wir die grundlegenden unterschiedlichen Bildverarbeitungskonzepte untersucht. Wir haben die Bildübersetzung mit Hilfe des OpenCV-Pakets gesehen. Wir haben die Methoden zum Verschieben des Bildes nach oben, unten, rechts und links gesehen. Diese Methoden sind sehr nützlich, wenn wir einen Datensatz ähnlicher Bilder erstellen, um ihn als Trainingsdatensatz zu geben, damit die Maschine unterschiedliche Bilder sieht, selbst wenn sie gleich sind. In diesem Artikel haben Sie auch gelernt, wie Sie ein Bild mithilfe einer Rotationsmatrix um einen beliebigen Punkt im kartesischen Raum drehen. Dann haben Sie entdeckt, wie OpenCV Bilder mithilfe dieser Matrix dreht, und ein paar Illustrationen von sich drehenden Bildern gesehen.
In diesem Abschnitt wurden die beiden grundlegenden (aber wesentlichen) Bildrechenoperationen Addition und Subtraktion untersucht. Wie Sie sehen können, ist das Addieren und Subtrahieren von Grundmatrizen alles, was Bildrechenoperationen mit sich bringen.
Zusätzlich haben wir OpenCV und NumPy verwendet, um die Besonderheiten der Bildarithmetik zu untersuchen. Diese Einschränkungen müssen beachtet werden, sonst riskieren Sie unerwartete Ergebnisse, wenn Sie arithmetische Operationen an Ihren Bildern ausführen.
Es ist wichtig, sich daran zu erinnern, dass, obwohl NumPy eine Modulo-Operation durchführt und „umschließt“, OpenCV-Additions- und Subtraktionswerte außerhalb des Bereichs [0, 255] schneiden, um in den Bereich zu passen. Wenn Sie Ihre eigenen Computer-Vision-Anwendungen entwickeln, hilft Ihnen dies dabei, die Suche nach kniffligen Fehlern zu vermeiden.
Das Spiegeln von Bildern ist zweifellos eine der einfacheren Ideen, die wir in diesem Kurs untersuchen werden. Flipping wird häufig beim maschinellen Lernen eingesetzt, um mehr Trainingsdatenproben zu generieren, was zu leistungsfähigeren und zuverlässigeren Bildklassifizierern führt.
Wir haben auch gelernt, wie man OpenCV verwendet, um die Größe eines Bildes zu ändern. Es ist wichtig, sowohl die von Ihnen verwendete Interpolationsmethode als auch das Seitenverhältnis Ihres Originalbildes zu berücksichtigen, wenn Sie die Größe ändern, damit das Ergebnis nicht verzerrt erscheint.
Schließlich ist es wichtig, sich daran zu erinnern, dass es immer am besten ist, von einem größeren zu einem kleineren Bild zu wechseln, wenn die Bildqualität ein Problem ist. In den meisten Fällen erzeugt das Vergrößern eines Bildes Artefakte und verschlechtert seine Qualität.