Künstliche Intelligenz ist eine der am schnellsten wachsenden Technologien, die Algorithmen des maschinellen Lernens nutzt, um Modelle anhand riesiger Datenmengen zu trainieren und zu testen. Die Daten können in verschiedenen Formaten gespeichert werden, aber um große Sprachmodelle mit LangChain zu erstellen, ist JSON der am häufigsten verwendete Typ. Die Trainings- und Testdaten müssen klar und vollständig sein und keine Unklarheiten aufweisen, damit das Modell effektiv funktionieren kann.
In dieser Anleitung wird der Prozess der Verwendung des pydantic JSON-Parsers in LangChain demonstriert.
Wie verwende ich den Pydantic (JSON)-Parser in LangChain?
Die JSON-Daten enthalten das Textformat von Daten, die durch Web Scraping und viele andere Quellen wie Protokolle usw. gesammelt werden können. Um die Genauigkeit der Daten zu überprüfen, verwendet LangChain die Pydantic-Bibliothek von Python, um den Prozess zu vereinfachen. Um den pydantic JSON-Parser in LangChain zu verwenden, gehen Sie einfach diese Anleitung durch:
Schritt 1: Module installieren
Um mit dem Prozess zu beginnen, installieren Sie einfach das LangChain-Modul, um dessen Bibliotheken für die Verwendung des Parsers in LangChain zu nutzen:
Pip Installieren langchain
Benutzen Sie nun die „ Pip-Installation ”-Befehl, um das OpenAI-Framework abzurufen und seine Ressourcen zu nutzen:
Pip Installieren openai
Stellen Sie nach der Installation der Module einfach eine Verbindung zur OpenAI-Umgebung her, indem Sie deren API-Schlüssel mit dem Befehl „ Du ' Und ' getpass ”Bibliotheken:
Importieren Sie unsgetpass importieren
os.environ [ 'OPENAI_API_KEY' ] = getpass.getpass ( „OpenAI-API-Schlüssel:“ )

Schritt 2: Bibliotheken importieren
Verwenden Sie das LangChain-Modul, um die erforderlichen Bibliotheken zu importieren, die zum Erstellen einer Vorlage für die Eingabeaufforderung verwendet werden können. Die Vorlage für die Eingabeaufforderung beschreibt die Methode zum Stellen von Fragen in natürlicher Sprache, damit das Modell die Eingabeaufforderung effektiv verstehen kann. Importieren Sie außerdem Bibliotheken wie OpenAI und ChatOpenAI, um mithilfe von LLMs Ketten zum Erstellen eines Chatbots zu erstellen:
aus langchain.prompts importieren (PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
aus langchain.llms OpenAI importieren
aus langchain.chat_models ChatOpenAI importieren
Anschließend importieren Sie pydantische Bibliotheken wie BaseModel, Field und Validator, um den JSON-Parser in LangChain zu verwenden:
aus langchain.output_parsers importieren Sie PydanticOutputParseraus pydantic import BaseModel, Field, validator
von der Eingabe von Import List
Schritt 3: Erstellen eines Modells
Nachdem Sie alle Bibliotheken für die Verwendung des pydantischen JSON-Parsers erhalten haben, holen Sie sich einfach das vorgefertigte getestete Modell mit der OpenAI()-Methode:
Modellname = „text-davinci-003“Temperatur = 0,0
Modell = OpenAI ( Modellname =Modellname, Temperatur =Temperatur )
Schritt 4: Actor BaseModel konfigurieren
Erstellen Sie ein weiteres Modell, um Antworten zu Schauspielern wie ihren Namen und Filmen zu erhalten, indem Sie nach der Filmografie des Schauspielers fragen:
Klasse Schauspieler ( Basismodell ) :Name: str = Feld ( Beschreibung = „Name des Hauptdarstellers“ )
film_names: Liste [ str ] = Feld ( Beschreibung = „Filme, in denen der Schauspieler die Hauptrolle spielte“ )
Actor_query = „Ich möchte die Filmografie jedes Schauspielers sehen“
parser = PydanticOutputParser ( pydantic_object =Schauspieler )
prompt = PromptTemplate (
Vorlage = „Beantworten Sie die Aufforderung des Benutzers. \N {format_instructions} \N {Abfrage} \N ' ,
Eingabevariablen = [ 'Abfrage' ] ,
Teilvariablen = { „format_instructions“ : parser.get_format_instructions ( ) } ,
)
Schritt 5: Testen des Basismodells
Rufen Sie einfach die Ausgabe mit der Funktion parse() ab, wobei die Ausgabevariable die für die Eingabeaufforderung generierten Ergebnisse enthält:
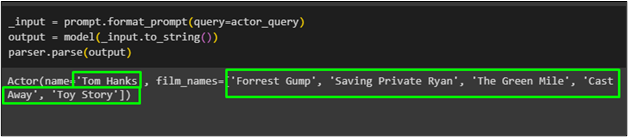
_input = prompt.format_prompt ( Abfrage =actor_query )Ausgabe = Modell ( _input.to_string ( ) )
parser.parse ( Ausgabe )
Der Schauspieler namens „ Tom Hanks ” mit der Liste seiner Filme wurde mit der Pydantic-Funktion aus dem Modell geholt:
Dabei geht es um die Verwendung des pydantischen JSON-Parsers in LangChain.
Abschluss
Um den pydantic JSON-Parser in LangChain zu verwenden, installieren Sie einfach LangChain- und OpenAI-Module, um eine Verbindung zu ihren Ressourcen und Bibliotheken herzustellen. Anschließend importieren Sie Bibliotheken wie OpenAI und Pydantic, um ein Basismodell zu erstellen und die Daten in Form von JSON zu überprüfen. Führen Sie nach dem Erstellen des Basismodells die Funktion parse() aus und sie gibt die Antworten für die Eingabeaufforderung zurück. Dieser Beitrag demonstrierte den Prozess der Verwendung des pydantischen JSON-Parsers in LangChain.