Die Anfänge der Sprache C++ ereigneten sich kurz danach im Jahr 1983 'Bjare Stroustrup' arbeitete mit Klassen in der C-Sprache inklusive mit einigen zusätzlichen Funktionen wie Operatorüberladung. Die verwendeten Dateierweiterungen sind „.c“ und „.cpp“. C++ ist erweiterbar und plattformunabhängig und enthält STL, die Abkürzung für Standard Template Library. Im Grunde genommen ist die bekannte C++-Sprache eigentlich als kompilierte Sprache bekannt, bei der die Quelldatei zu Objektdateien zusammenkompiliert wird, die in Kombination mit einem Linker ein lauffähiges Programm erzeugen.
Auf der anderen Seite, wenn wir über seine Ebene sprechen, handelt es sich um eine mittlere Ebene, die den Vorteil der Programmierung auf niedriger Ebene wie Treiber oder Kernel und auch der Anwendungen auf höherer Ebene wie Spiele, GUI oder Desktop-Anwendungen interpretiert. Aber die Syntax ist für C und C++ fast gleich.
Komponenten der Sprache C++:
#include
Dieser Befehl ist eine Header-Datei, die den Befehl „cout“ enthält. Abhängig von den Bedürfnissen und Vorlieben des Benutzers kann es mehr als eine Header-Datei geben.
int Haupt()
Diese Anweisung ist die Hauptprogrammfunktion, die Voraussetzung für jedes C++-Programm ist, dh ohne diese Anweisung kann kein C++-Programm ausgeführt werden. Hier ist „int“ der Datentyp der Rückgabevariablen, der den Datentyp angibt, den die Funktion zurückgibt.
Erklärung:
Variablen werden deklariert und ihnen Namen zugewiesen.
Problemstellung:
Dies ist in einem Programm unerlässlich und kann eine „while“-Schleife, eine „for“-Schleife oder eine andere angewendete Bedingung sein.
Betreiber:
Operatoren werden in C++-Programmen verwendet und einige sind entscheidend, weil sie auf die Bedingungen angewendet werden. Einige wichtige Operatoren sind &&, ||, !, &, !=, |, &=, |=, ^, ^=.
C++ Eingabe Ausgabe:
Nun werden wir die Eingabe- und Ausgabefähigkeiten in C++ besprechen. Alle in C++ verwendeten Standardbibliotheken bieten maximale Ein- und Ausgabemöglichkeiten, die in Form einer Folge von Bytes ausgeführt werden oder sich normalerweise auf die Streams beziehen.
Eingabestrom:
Falls die Bytes vom Gerät zum Hauptspeicher gestreamt werden, handelt es sich um den Eingabestrom.
Ausgabestrom:
Wenn die Bytes in die entgegengesetzte Richtung gestreamt werden, ist es der Ausgangsstream.
Eine Header-Datei wird verwendet, um die Ein- und Ausgabe in C++ zu erleichtern. Es ist als
Beispiel:
Wir werden eine String-Nachricht mit einem Zeichentyp-String anzeigen.
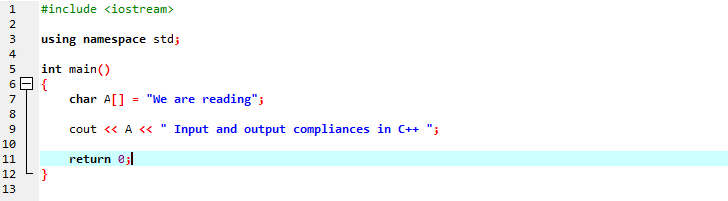
In der ersten Zeile fügen wir „iostream“ ein, das fast alle wesentlichen Bibliotheken enthält, die wir möglicherweise für die Ausführung eines C++-Programms benötigen. In der nächsten Zeile deklarieren wir einen Namensraum, der den Bereich für die Bezeichner bereitstellt. Nach dem Aufruf der Hauptfunktion initialisieren wir ein Zeichentyp-Array, das die Zeichenfolgennachricht speichert, und ‚cout‘ zeigt sie durch Verkettung an. Wir verwenden „cout“, um den Text auf dem Bildschirm anzuzeigen. Außerdem haben wir eine Variable „A“ mit einem Zeichendatentyp-Array genommen, um eine Zeichenkette zu speichern, und dann haben wir mit dem Befehl „cout“ sowohl die Array-Nachricht als auch die statische Nachricht hinzugefügt.
Die erzeugte Ausgabe ist unten dargestellt:

Beispiel:
In diesem Fall würden wir das Alter des Benutzers in einer einfachen Zeichenfolgennachricht darstellen.
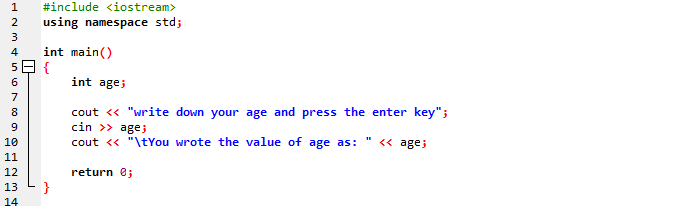
Im ersten Schritt binden wir die Bibliothek ein. Danach verwenden wir einen Namensraum, der den Bereich für die Bezeichner bereitstellt. Im nächsten Schritt rufen wir die auf hauptsächlich() Funktion. Danach initialisieren wir das Alter als „int“-Variable. Wir verwenden den Befehl „cin“ für die Eingabe und den Befehl „cout“ für die Ausgabe der einfachen Zeichenfolgennachricht. „cin“ gibt den Alterswert des Benutzers ein und „cout“ zeigt ihn in der anderen statischen Nachricht an.

Diese Meldung wird nach Ausführung des Programms auf dem Bildschirm angezeigt, damit der Benutzer das Alter abrufen und dann die EINGABETASTE drücken kann.

Beispiel:
Hier demonstrieren wir, wie man einen String mit „cout“ ausgibt.

Um einen String auszugeben, binden wir zunächst eine Bibliothek und dann den Namensraum für Bezeichner ein. Das hauptsächlich() Funktion aufgerufen wird. Außerdem drucken wir eine Zeichenfolgenausgabe mit dem Befehl „cout“ mit dem Einfügeoperator, der dann die statische Nachricht auf dem Bildschirm anzeigt.

C++-Datentypen:
Datentypen in C++ sind ein sehr wichtiges und weithin bekanntes Thema, da es die Grundlage der Programmiersprache C++ ist. Ebenso muss jede verwendete Variable einen bestimmten oder identifizierten Datentyp haben.
Wir wissen, dass wir für alle Variablen den Datentyp während der Deklaration verwenden, um den wiederherzustellenden Datentyp einzuschränken. Oder wir könnten sagen, dass die Datentypen einer Variablen immer mitteilen, welche Art von Daten sie selbst speichert. Jedes Mal, wenn wir eine Variable definieren, weist der Compiler den Speicher basierend auf dem deklarierten Datentyp zu, da jeder Datentyp eine andere Speicherkapazität hat.
Die Sprache C++ unterstützt die Vielfalt der Datentypen, sodass der Programmierer den geeigneten Datentyp auswählen kann, den er möglicherweise benötigt.
C++ erleichtert die Verwendung der unten aufgeführten Datentypen:
- Benutzerdefinierte Datentypen
- Abgeleitete Datentypen
- Eingebaute Datentypen
Zum Beispiel werden die folgenden Zeilen gegeben, um die Wichtigkeit der Datentypen zu veranschaulichen, indem einige gängige Datentypen initialisiert werden:
int a = zwei ; // Integer Wertschweben F_N = 3.66 ; // Fließkommawert
doppelt D_N = 8.87 ; // doppelter Fließkommawert
verkohlen Alpha = 'p' ; // Zeichen
bool b = Stimmt ; // Boolesch
Einige gängige Datentypen: Welche Größe sie angeben und welche Art von Informationen ihre Variablen speichern, wird unten gezeigt:
- Char: Mit der Größe von einem Byte speichert es ein einzelnes Zeichen, einen Buchstaben, eine Zahl oder ASCII-Werte.
- Boolean: Mit der Größe von 1 Byte werden Werte entweder als wahr oder falsch gespeichert und zurückgegeben.
- Int: Mit einer Größe von 2 oder 4 Bytes werden ganze Zahlen ohne Dezimalstellen gespeichert.
- Fließkomma: Mit einer Größe von 4 Bytes werden Bruchzahlen mit einer oder mehreren Dezimalstellen gespeichert. Dies ist ausreichend, um bis zu 7 Dezimalstellen zu speichern.
- Double Floating Point: Mit einer Größe von 8 Bytes werden auch die Bruchzahlen mit einer oder mehreren Dezimalstellen gespeichert. Dies ist ausreichend, um bis zu 15 Dezimalstellen zu speichern.
- Void: Ohne festgelegte Größe enthält ein Void etwas Wertloses. Daher wird es für die Funktionen verwendet, die einen Nullwert zurückgeben.
- Breites Zeichen: Bei einer Größe von mehr als 8 Bit wird das normalerweise 2 oder 4 Byte lange Zeichen durch wchar_t repräsentiert, das ähnlich wie char ist und somit auch einen Zeichenwert speichert.
Die Größe der oben genannten Variablen kann je nach Verwendung des Programms oder des Compilers unterschiedlich sein.
Beispiel:
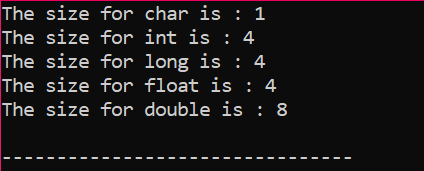
Schreiben wir einfach einen einfachen Code in C++, der die genauen Größen einiger oben beschriebener Datentypen liefert:

In diesem Code integrieren wir die Bibliothek
Die Ausgabe wird in Bytes empfangen, wie in der Abbildung gezeigt:
Beispiel:
Hier würden wir die Größe von zwei verschiedenen Datentypen hinzufügen.
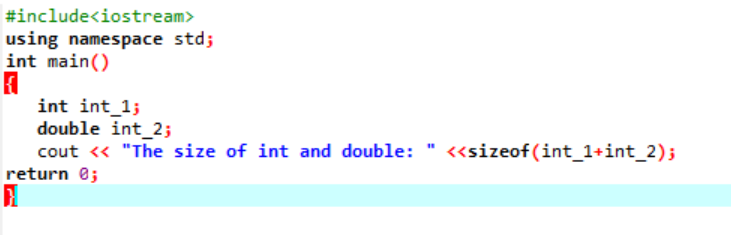
Zuerst binden wir eine Header-Datei ein, die einen „Standard-Namensraum“ für Bezeichner verwendet. Als nächstes die hauptsächlich() wird aufgerufen, in der wir zuerst die Variable „int“ und dann eine Variable „double“ initialisieren, um den Unterschied zwischen den Größen dieser beiden zu überprüfen. Dann werden ihre Größen durch die Verwendung von verkettet Größe von() Funktion. Die Ausgabe wird durch die Anweisung „cout“ angezeigt.

Es gibt noch einen weiteren Begriff, der hier erwähnt werden muss, und zwar ‘Datenmodifikatoren’ . Der Name deutet darauf hin, dass die „Datenmodifikatoren“ zusammen mit den integrierten Datentypen verwendet werden, um ihre Längen zu ändern, die ein bestimmter Datentyp durch die Notwendigkeit oder Anforderung des Compilers aufrechterhalten kann.
Im Folgenden sind die Datenmodifikatoren aufgeführt, auf die in C++ zugegriffen werden kann:
- Unterzeichnet
- Ohne Vorzeichen
- Lang
- Kurz
Die modifizierte Größe und auch der entsprechende Bereich der eingebauten Datentypen werden unten erwähnt, wenn sie mit den Datentyp-Modifikatoren kombiniert werden:
- Short int: Hat eine Größe von 2 Bytes und hat einen Bereich von Modifikationen von -32.768 bis 32.767
- Unsigned short int: Hat eine Größe von 2 Bytes und hat einen Bereich von Modifikationen von 0 bis 65.535
- Unsigned int: Mit einer Größe von 4 Bytes hat es einen Bereich von Modifikationen von 0 bis 4.294.967.295
- Int: Hat eine Größe von 4 Bytes und einen Änderungsbereich von -2.147.483.648 bis 2.147.483.647
- Lange Ganzzahl: Hat eine Größe von 4 Bytes und hat einen Änderungsbereich von -2.147.483.648 bis 2.147.483.647
- Unsigned long int: Mit einer Größe von 4 Bytes hat es einen Bereich von Modifikationen von 0 bis 4.294.967.295
- Long long int: Hat eine Größe von 8 Bytes und hat eine Reihe von Modifikationen von –(2^63) bis (2^63)-1
- Unsigned long long int: Mit einer Größe von 8 Bytes hat es einen Bereich von Modifikationen von 0 bis 18.446.744.073.709.551.615
- Zeichen mit Vorzeichen: Mit einer Größe von 1 Byte hat es eine Reihe von Modifikationen von -128 bis 127
- Unsigned char: Mit einer Größe von 1 Byte hat es einen Bereich von Modifikationen von 0 bis 255.
C++-Aufzählung:
In der Programmiersprache C++ ist „Enumeration“ ein benutzerdefinierter Datentyp. Die Aufzählung wird als „ aufzählen in C++. Es wird verwendet, um jeder im Programm verwendeten Konstante spezifische Namen zuzuweisen. Es verbessert die Lesbarkeit und Benutzerfreundlichkeit des Programms.
Syntax:
Wir deklarieren die Enumeration in C++ wie folgt:
Aufzählung enum_Name { Konstante1 , Konstante2 , Konstante3… }Vorteile der Aufzählung in C++:
Enum kann auf folgende Weise verwendet werden:
- Es kann häufig in switch case-Anweisungen verwendet werden.
- Es kann Konstruktoren, Felder und Methoden verwenden.
- Es kann nur die Klasse „enum“ erweitern, keine andere Klasse.
- Es kann die Kompilierzeit erhöhen.
- Es kann überquert werden.
Nachteile der Aufzählung in C++:
Enum hat auch einige Nachteile:
Wenn ein Name einmal aufgezählt wurde, kann er nicht erneut im selben Bereich verwendet werden.
Zum Beispiel:
Aufzählung Tage{ Sa , Sonne , Mein } ;
int Sa = 8 ; // Diese Zeile hat einen Fehler
Enum kann nicht vorwärts deklariert werden.
Zum Beispiel:
Aufzählung Formen ;Klasse Farbe
{
Leere zeichnen ( Formen aShape ) ; //Formen wurden nicht deklariert
} ;
Sie sehen aus wie Namen, sind aber ganze Zahlen. Sie können also automatisch in jeden anderen Datentyp konvertiert werden.
Zum Beispiel:
Aufzählung Formen{
Dreieck , Kreis , Quadrat
} ;
int Farbe = blau ;
Farbe = Quadrat ;
Beispiel:
In diesem Beispiel sehen wir die Verwendung der C++-Enumeration:
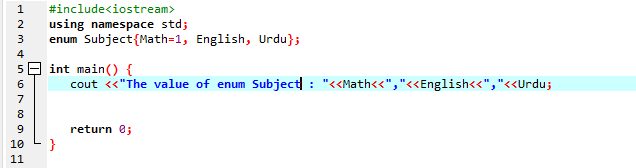
Bei dieser Codeausführung beginnen wir zunächst mit #include
Hier ist unser Ergebnis des ausgeführten Programms:

Wie Sie also sehen können, haben wir folgende Werte: Mathe, Urdu, Englisch; das ist 1,2,3.
Beispiel:
Hier ist ein weiteres Beispiel, durch das wir unsere Konzepte zu Enum klären:
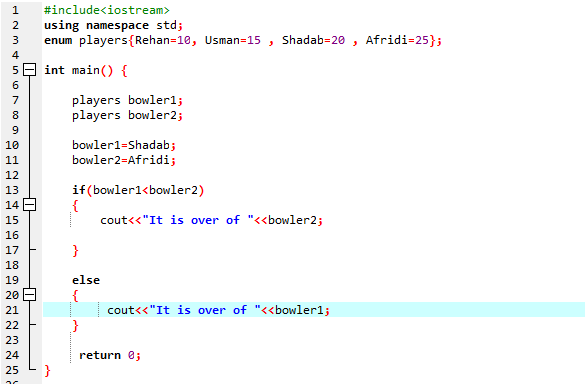
In diesem Programm binden wir zunächst die Header-Datei
Wir müssen eine if-else-Anweisung verwenden . Wir haben auch den Vergleichsoperator innerhalb der „if“-Anweisung verwendet, was bedeutet, dass wir vergleichen, ob „bowler2“ größer als „bowler1“ ist. Dann wird der „if“-Block ausgeführt, was bedeutet, dass Afridi vorbei ist. Dann haben wir „cout<<“ eingegeben, um die Ausgabe anzuzeigen. Zuerst drucken wir die Aussage „Es ist vorbei“. Dann der Wert von „Bowler2“. Wenn nicht, wird der Else-Block aufgerufen, was bedeutet, dass es das Ende von Shadab ist. Dann zeigen wir durch Anwenden des Befehls „cout<<“ die Aussage „It is over of“ an. Dann der Wert von „Bowler1“.

Gemäß der If-else-Anweisung haben wir über 25, was dem Wert von Afridi entspricht. Das bedeutet, dass der Wert der Aufzählungsvariable „Bowler2“ größer als „Bowler1“ ist, weshalb die „if“-Anweisung ausgeführt wird.
C++ Sonst Schalter:
In der Programmiersprache C++ verwenden wir die „if-Anweisung“ und die „switch-Anweisung“, um den Programmablauf zu ändern. Diese Anweisungen werden verwendet, um mehrere Sätze von Befehlen für die Implementierung des Programms in Abhängigkeit von dem wahren Wert der jeweils erwähnten Anweisungen bereitzustellen. In den meisten Fällen verwenden wir Operatoren als Alternative zur „if“-Anweisung. Alle diese oben erwähnten Aussagen sind Auswahlaussagen, die als Entscheidungs- oder Bedingungsaussagen bekannt sind.
Die „if“-Anweisung:
Diese Anweisung wird verwendet, um eine bestimmte Bedingung zu testen, wann immer Sie Lust haben, den Ablauf eines Programms zu ändern. Wenn hier eine Bedingung wahr ist, führt das Programm die geschriebenen Anweisungen aus, aber wenn die Bedingung falsch ist, wird es einfach beendet. Betrachten wir ein Beispiel;
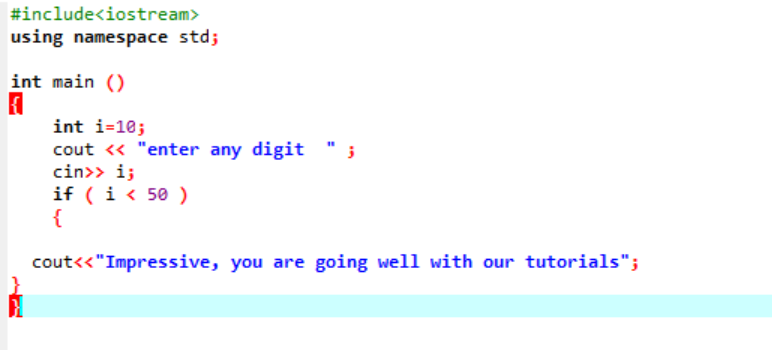
Dies ist die einfache 'if'-Anweisung, die verwendet wird, bei der wir eine 'int'-Variable mit 10 initialisieren. Dann wird ein Wert vom Benutzer genommen und in der 'if'-Anweisung gegengeprüft. Wenn es die in der 'if'-Anweisung angewendeten Bedingungen erfüllt, wird die Ausgabe angezeigt.

Da die gewählte Ziffer 40 war, ist die Ausgabe die Nachricht.
Die „If-else“-Anweisung:
In einem komplexeren Programm, bei dem die „if“-Anweisung normalerweise nicht funktioniert, verwenden wir die „if-else“-Anweisung. Im gegebenen Fall verwenden wir die „if-else“-Anweisung, um die angewendeten Bedingungen zu überprüfen.
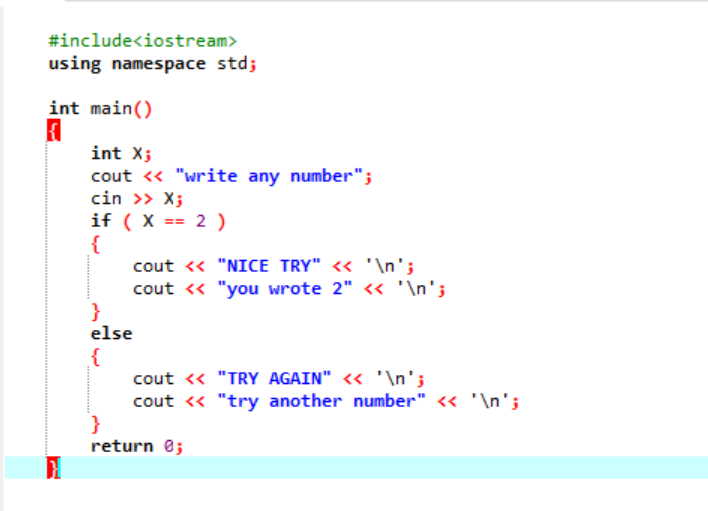
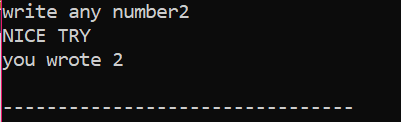
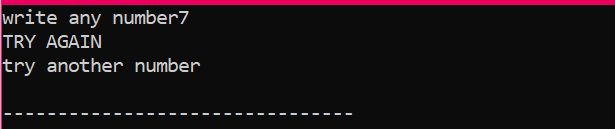
Zuerst deklarieren wir eine Variable vom Datentyp „int“ namens „x“, deren Wert vom Benutzer genommen wird. Jetzt wird die 'if'-Anweisung verwendet, bei der wir eine Bedingung angewendet haben, dass, wenn der vom Benutzer eingegebene ganzzahlige Wert 2 ist, die Ausgabe die gewünschte ist und eine einfache 'NICE TRY'-Meldung angezeigt wird. Andernfalls, wenn die eingegebene Zahl nicht 2 ist, wäre die Ausgabe anders.
Wenn der Benutzer die Zahl 2 schreibt, wird die folgende Ausgabe angezeigt.
Wenn der Benutzer eine andere Zahl außer 2 schreibt, erhalten wir folgende Ausgabe:
Die If-else-if-Anweisung:
Verschachtelte if-else-if-Anweisungen sind ziemlich komplex und werden verwendet, wenn mehrere Bedingungen im selben Code angewendet werden. Betrachten wir dies anhand eines anderen Beispiels:
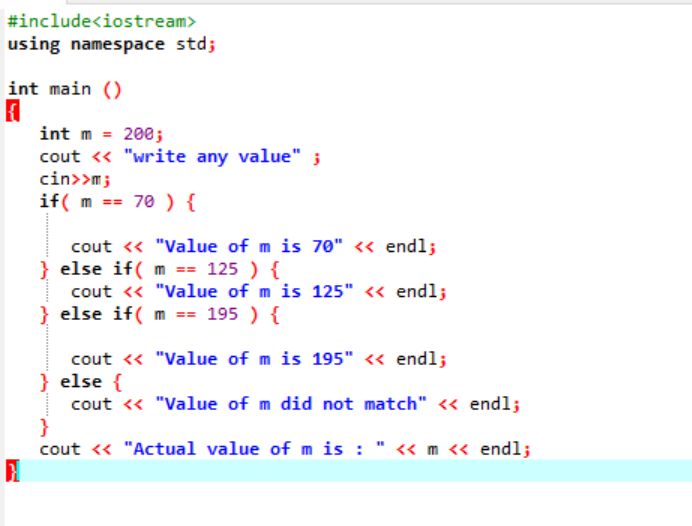
Hier haben wir nach der Integration der Header-Datei und des Namensraums einen Wert der Variablen „m“ mit 200 initialisiert. Der Wert von „m“ wird dann vom Benutzer übernommen und dann mit den im Programm angegebenen mehreren Bedingungen abgeglichen.
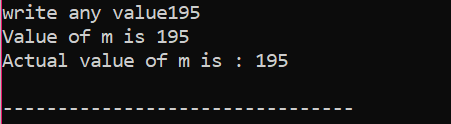
Hier hat der Benutzer den Wert 195 gewählt. Deshalb zeigt die Ausgabe, dass dies der tatsächliche Wert von „m“ ist.
Switch-Anweisung:
Eine „switch“-Anweisung wird in C++ für eine Variable verwendet, die getestet werden muss, wenn sie gleich einer Liste mit mehreren Werten ist. In der „switch“-Anweisung identifizieren wir Bedingungen in Form von unterschiedlichen Fällen, und alle Fälle haben am Ende jeder case-Anweisung eine Unterbrechung. Auf mehrere Fälle werden geeignete Bedingungen und Anweisungen mit break-Anweisungen angewendet, die die switch-Anweisung beenden und zu einer Standardanweisung wechseln, falls keine Bedingung unterstützt wird.
Stichwort „Pause“:
Die switch-Anweisung enthält das Schlüsselwort „break“. Es verhindert, dass der Code im nachfolgenden Fall ausgeführt wird. Die Ausführung der switch-Anweisung endet, wenn der C++-Compiler auf das Schlüsselwort „break“ stößt und das Steuerelement zu der Zeile wechselt, die auf die switch-Anweisung folgt. Es ist nicht notwendig, eine Break-Anweisung in einem Schalter zu verwenden. Die Ausführung fährt mit dem nächsten Fall fort, wenn er nicht verwendet wird.
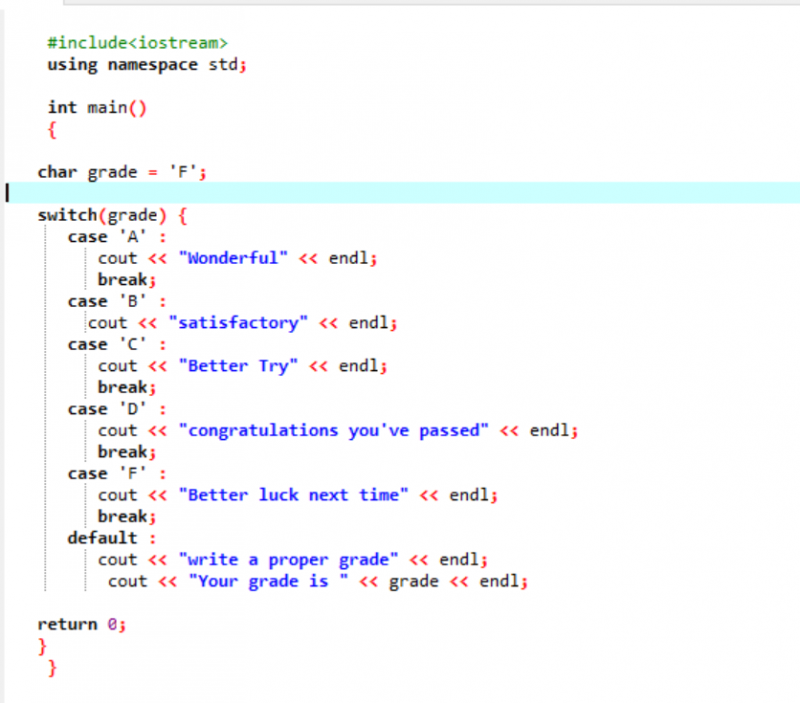
In der ersten Zeile des gemeinsam genutzten Codes schließen wir die Bibliothek ein. Danach fügen wir „Namespace“ hinzu. Wir berufen uns auf die hauptsächlich() Funktion. Dann deklarieren wir einen Zeichendatentyp als „F“. Diese Note könnte Ihr Wunsch sein und das Ergebnis wird jeweils für die ausgewählten Fälle angezeigt. Wir haben die switch-Anweisung angewendet, um das Ergebnis zu erhalten.
Wenn wir als Note „F“ wählen, lautet die Ausgabe „Viel Glück beim nächsten Mal“, da dies die Aussage ist, die wir drucken möchten, falls die Note „F“ ist.

Lassen Sie uns die Note auf X ändern und sehen, was passiert. Ich habe „X“ als Note geschrieben und die erhaltene Ausgabe ist unten dargestellt:

Der unzulässige Fall im „Schalter“ bewegt den Zeiger also automatisch direkt auf die Standardanweisung und beendet das Programm.
If-else- und switch-Anweisungen haben einige gemeinsame Merkmale:
- Diese Anweisungen werden verwendet, um zu verwalten, wie das Programm ausgeführt wird.
- Beide werten eine Bedingung aus, die bestimmt, wie das Programm abläuft.
- Trotz unterschiedlicher Darstellungsstile können sie für denselben Zweck verwendet werden.
If-else- und switch-Anweisungen unterscheiden sich in gewisser Weise:
- Während der Benutzer die Werte in „switch“-Case-Anweisungen definiert, bestimmen Einschränkungen die Werte in „if-else“-Anweisungen.
- Es braucht Zeit, um festzustellen, wo die Änderung vorgenommen werden muss, und es ist eine Herausforderung, „if-else“-Anweisungen zu ändern. Auf der anderen Seite sind „switch“-Anweisungen einfach zu aktualisieren, da sie leicht geändert werden können.
- Um viele Ausdrücke einzuschließen, können wir zahlreiche „if-else“-Anweisungen verwenden.
C++-Schleifen:
Jetzt werden wir entdecken, wie Schleifen in der C++-Programmierung verwendet werden. Die als „Schleife“ bekannte Kontrollstruktur wiederholt eine Reihe von Anweisungen. Mit anderen Worten, es wird als repetitive Struktur bezeichnet. Alle Anweisungen werden gleichzeitig in einer sequentiellen Struktur ausgeführt . Andererseits kann die Bedingungsstruktur je nach angegebener Anweisung einen Ausdruck ausführen oder auslassen. In bestimmten Situationen kann es erforderlich sein, eine Anweisung mehr als einmal auszuführen.
Arten von Schleifen:
Es gibt drei Kategorien von Schleifen:
For-Schleife:
Schleife ist etwas, das sich wie ein Zyklus wiederholt und stoppt, wenn es die angegebene Bedingung nicht validiert. Eine „for“-Schleife implementiert mehrere Male eine Folge von Anweisungen und verdichtet den Code, der mit der Schleifenvariable fertig wird. Dies zeigt, dass eine „for“-Schleife eine bestimmte Art von iterativer Kontrollstruktur ist, die es uns ermöglicht, eine Schleife zu erstellen, die eine festgelegte Anzahl von Malen wiederholt wird. Die Schleife würde es uns ermöglichen, die Anzahl „N“ von Schritten auszuführen, indem wir nur einen Code einer einfachen Zeile verwenden. Lassen Sie uns über die Syntax sprechen, die wir für eine „for“-Schleife verwenden werden, die in Ihrer Softwareanwendung ausgeführt werden soll.
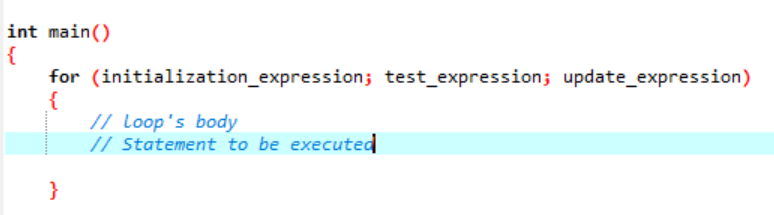
Die Syntax der ‘for’ Schleifenausführung:
Beispiel:
Hier verwenden wir eine Schleifenvariable, um diese Schleife in einer „for“-Schleife zu regulieren. Der erste Schritt wäre, dieser Variablen einen Wert zuzuweisen, den wir als Schleife angeben. Danach müssen wir definieren, ob es kleiner oder größer als der Zählerwert ist. Nun soll der Rumpf der Schleife ausgeführt werden und auch die Schleifenvariable wird aktualisiert, falls die Anweisung wahr zurückgibt. Die obigen Schritte werden häufig wiederholt, bis wir die Ausgangsbedingung erreichen.
- Initialisierungsausdruck: Zuerst müssen wir den Schleifenzähler in diesem Ausdruck auf einen beliebigen Anfangswert setzen.
- Ausdruck testen : Jetzt müssen wir die gegebene Bedingung im gegebenen Ausdruck testen. Wenn die Kriterien erfüllt sind, führen wir den Körper der „for“-Schleife aus und fahren mit der Aktualisierung des Ausdrucks fort; wenn nicht, müssen wir aufhören.
- Ausdruck aktualisieren: Dieser Ausdruck erhöht oder verringert die Schleifenvariable um einen bestimmten Wert, nachdem der Hauptteil der Schleife ausgeführt wurde.
C++-Programmbeispiele zur Validierung einer „For“-Schleife:
Beispiel:
Dieses Beispiel zeigt das Drucken ganzzahliger Werte von 0 bis 10.
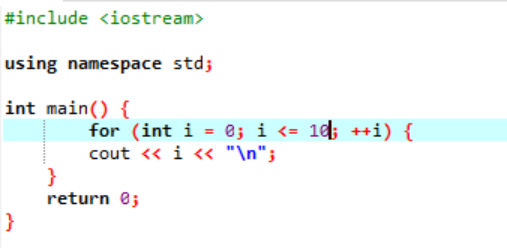
In diesem Szenario sollen wir die ganzen Zahlen von 0 bis 10 ausgeben. Zuerst haben wir eine Zufallsvariable i mit einem Wert ‚0‘ initialisiert und dann überprüft der bereits verwendete Bedingungsparameter die Bedingung, wenn i<=10. Und wenn es die Bedingung erfüllt und wahr wird, beginnt die Ausführung der „for“-Schleife. Nach der Ausführung soll unter den beiden Inkrement- oder Dekrementparametern einer ausgeführt werden, bei dem der Wert der Variablen i erhöht wird, bis die spezifizierte Bedingung i <= 10 falsch wird.

Anzahl Iterationen mit Bedingung i<10:
| Anzahl von Iterationen |
Variablen | ich<10 | Aktion |
| Zuerst | ich=0 | Stimmt | 0 wird angezeigt und i wird um 1 erhöht. |
| Zweite | i=1 | Stimmt | 1 wird angezeigt und i wird um 2 erhöht. |
| Dritte | i=2 | Stimmt | 2 wird angezeigt und i wird um 3 erhöht. |
| Vierte | i=3 | Stimmt | 3 wird angezeigt und i wird um 4 erhöht. |
| Fünfte | i=4 | Stimmt | 4 wird angezeigt und i wird um 5 erhöht. |
| Sechste | i=5 | Stimmt | 5 wird angezeigt und i wird um 6 erhöht. |
| Siebte | i=6 | Stimmt | 6 wird angezeigt und i wird um 7 erhöht. |
| Achte | i=7 | Stimmt | 7 wird angezeigt und i wird um 8 erhöht |
| Neunte | i=8 | Stimmt | 8 wird angezeigt und i wird um 9 erhöht. |
| Zehntel | i=9 | Stimmt | 9 wird angezeigt und i wird um 10 erhöht. |
| Elfte | i=10 | Stimmt | 10 wird angezeigt und i wird um 11 erhöht. |
| Zwölftel | i=11 | FALSCH | Die Schleife wird beendet. |
Beispiel:
Die folgende Instanz zeigt den Wert der Ganzzahl an:
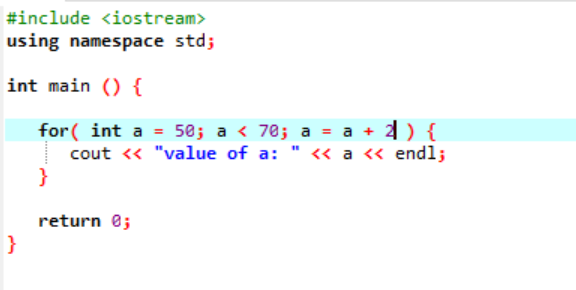
Im obigen Fall wird eine Variable namens „a“ mit einem gegebenen Wert von 50 initialisiert. Eine Bedingung wird angewendet, wenn die Variable „a“ kleiner als 70 ist. Dann wird der Wert von „a“ so aktualisiert, dass er hinzugefügt wird 2. Der Wert von 'a' wird dann von einem Anfangswert gestartet, der 50 war, und 2 wird gleichzeitig während der gesamten Schleife hinzugefügt, bis die Bedingung falsch zurückgibt und der Wert von 'a' von 70 erhöht wird und die Schleife endet.
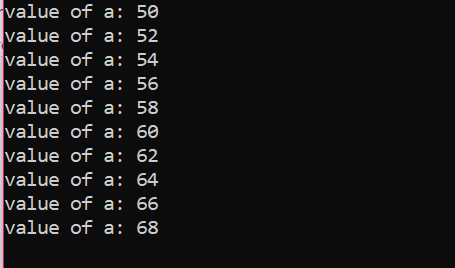
Anzahl der Iterationen:
| Anzahl von Wiederholung |
Variable | a=50 | Aktion |
| Zuerst | a=50 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 50 wird 52 |
| Zweite | a=52 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere Ganzzahlen hinzugefügt werden, und aus 52 wird 54 |
| Dritte | a=54 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 54 wird 56 |
| Vierte | a=56 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 56 wird 58 |
| Fünfte | a=58 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere Ganzzahlen hinzugefügt werden, und aus 58 wird 60 |
| Sechste | a=60 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 60 wird 62 |
| Siebte | a=62 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere Ganzzahlen hinzugefügt werden, und aus 62 wird 64 |
| Achte | a=64 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 64 wird 66 |
| Neunte | a=66 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 66 wird 68 |
| Zehntel | a=68 | Stimmt | Der Wert von a wird aktualisiert, indem zwei weitere ganze Zahlen hinzugefügt werden, und aus 68 wird 70 |
| Elfte | a=70 | FALSCH | Die Schleife wird beendet |
While-Schleife:
Bis die definierte Bedingung erfüllt ist, können eine oder mehrere Anweisungen ausgeführt werden. Wenn die Iteration im Voraus unbekannt ist, ist sie sehr nützlich. Zuerst wird die Bedingung überprüft und tritt dann in den Schleifenkörper ein, um die Anweisung auszuführen oder zu implementieren.
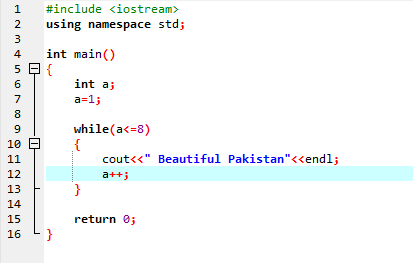
In der ersten Zeile binden wir die Header-Datei
Do-While-Schleife:
Wenn die definierte Bedingung erfüllt ist, wird eine Reihe von Anweisungen ausgeführt. Zuerst wird der Körper der Schleife ausgeführt. Danach wird die Bedingung überprüft, ob sie wahr ist oder nicht. Daher wird die Anweisung einmal ausgeführt. Der Schleifenkörper wird in einer „Do-while“-Schleife verarbeitet, bevor die Bedingung ausgewertet wird. Das Programm wird ausgeführt, wenn die erforderliche Bedingung erfüllt ist. Andernfalls, wenn die Bedingung falsch ist, wird das Programm beendet.
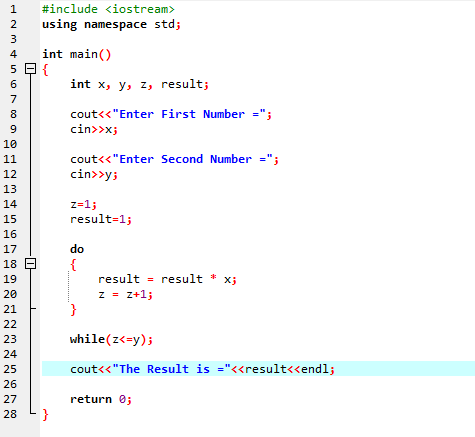
Hier binden wir die Header-Datei
C++ Fortsetzen/Pause:
C++ Continue-Anweisung:
Die Continue-Anweisung wird in der Programmiersprache C++ verwendet, um eine aktuelle Inkarnation einer Schleife zu vermeiden und die Steuerung auf die nachfolgende Iteration zu übertragen. Während der Schleife kann die Continue-Anweisung verwendet werden, um bestimmte Anweisungen zu überspringen. Es wird auch innerhalb der Schleife in Verbindung mit Executive Statements verwendet. Wenn die spezifische Bedingung wahr ist, werden alle Anweisungen nach der Continue-Anweisung nicht implementiert.
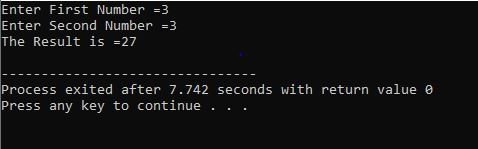
Mit for-Schleife:
In diesem Fall verwenden wir die „for-Schleife“ mit der Continue-Anweisung von C++, um das erforderliche Ergebnis zu erhalten, während einige festgelegte Anforderungen erfüllt werden.

Wir beginnen damit, die
Mit While-Schleife:
Während dieser Demonstration haben wir sowohl die „while-Schleife“ als auch die C++-Anweisung „Continue“ verwendet, einschließlich einiger Bedingungen, um zu sehen, welche Art von Ausgabe generiert werden kann.
In diesem Beispiel legen wir eine Bedingung fest, um Zahlen nur zu 40 zu addieren. Wenn die eingegebene Ganzzahl eine negative Zahl ist, wird die „while“-Schleife beendet. Wenn die Zahl andererseits größer als 40 ist, wird diese spezifische Zahl von der Iteration übersprungen.
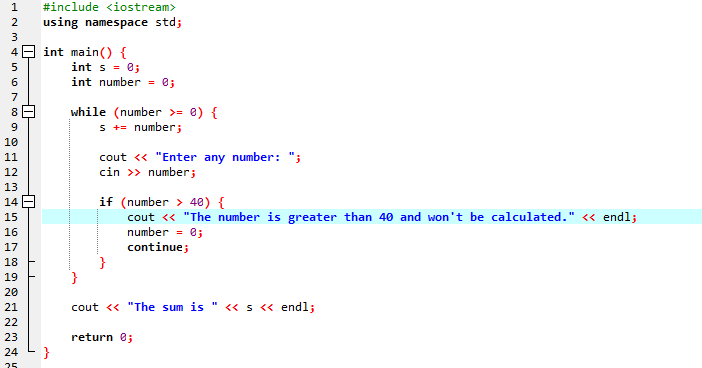
Wir werden die
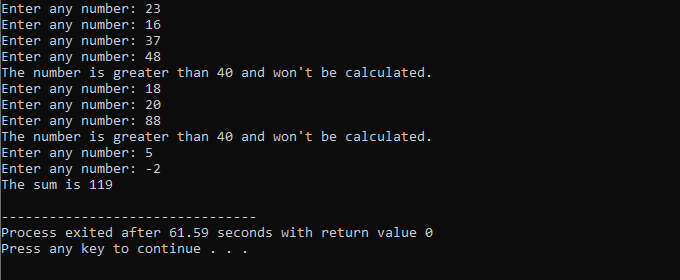
C++ break-Anweisung:
Immer wenn die break-Anweisung in einer Schleife in C++ verwendet wird, wird die Schleife sofort beendet und die Programmsteuerung startet bei der Anweisung nach der Schleife neu. Es ist auch möglich, einen Fall innerhalb einer „switch“-Anweisung zu beenden.
Mit for-Schleife:
Hier verwenden wir die „for“-Schleife mit der „break“-Anweisung, um die Ausgabe zu beobachten, indem wir über verschiedene Werte iterieren.
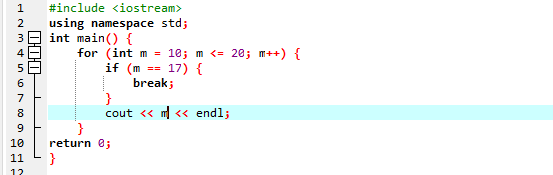
Zuerst binden wir eine
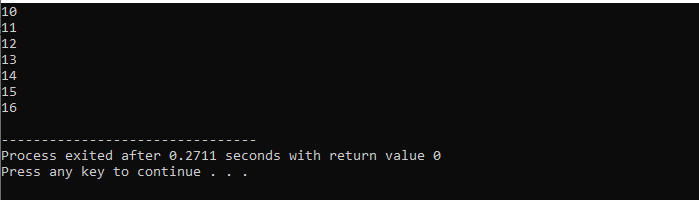
Mit While-Schleife:
Wir werden die „while“-Schleife zusammen mit der break-Anweisung verwenden.
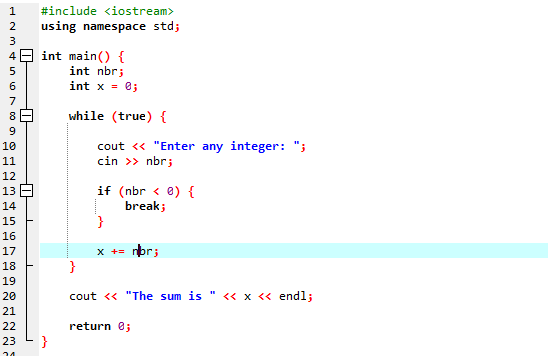
Wir beginnen mit dem Import der
C++-Funktionen:
Funktionen werden verwendet, um ein bereits bekanntes Programm in mehrere Codefragmente zu strukturieren, die nur ausgeführt werden, wenn sie aufgerufen werden. In der Programmiersprache C++ wird eine Funktion als eine Gruppe von Anweisungen definiert, die einen geeigneten Namen erhalten und von ihnen aufgerufen werden. Der Benutzer kann Daten an die Funktionen übergeben, die wir Parameter nennen. Funktionen sind dafür verantwortlich, die Aktionen zu implementieren, wenn der Code am wahrscheinlichsten wiederverwendet wird.
Erstellung einer Funktion:
Obwohl C++ viele vordefinierte Funktionen wie z hauptsächlich(), was die Ausführung des Codes erleichtert. Genauso können Sie Ihre Funktionen nach Ihren Anforderungen erstellen und definieren. Wie bei allen gewöhnlichen Funktionen benötigen Sie hier einen Namen für Ihre Funktion für eine Deklaration, die mit einer Klammer nach „()“ hinzugefügt wird.
Syntax:
Leere Arbeit ( ){
// Körper der Funktion
}
Void ist der Rückgabetyp der Funktion. Arbeit ist der Name, der ihr gegeben wurde, und die geschweiften Klammern würden den Hauptteil der Funktion einschließen, wo wir den Code für die Ausführung hinzufügen.
Aufruf einer Funktion:
Die im Code deklarierten Funktionen werden nur ausgeführt, wenn sie aufgerufen werden. Um eine Funktion aufzurufen, müssen Sie den Namen der Funktion zusammen mit der Klammer angeben, auf die ein Semikolon „;“ folgt.
Beispiel:
Lassen Sie uns in dieser Situation eine benutzerdefinierte Funktion deklarieren und konstruieren.
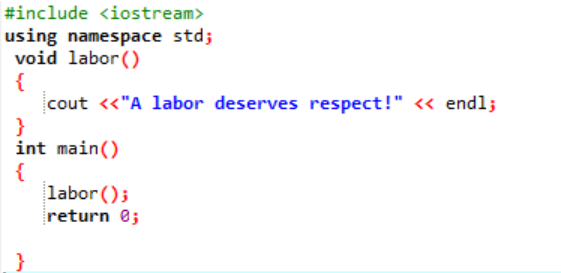
Zunächst wird uns, wie in jedem Programm beschrieben, eine Bibliothek und ein Namensraum zugewiesen, um die Ausführung des Programms zu unterstützen. Die benutzerdefinierte Funktion Arbeit() wird immer vor dem Aufschreiben der aufgerufen hauptsächlich() Funktion. Eine Funktion namens Arbeit() wird deklariert, wo die Meldung „Eine Arbeit verdient Respekt!“ angezeigt wird. In dem hauptsächlich() Funktion mit dem Integer-Rückgabetyp rufen wir die auf Arbeit() Funktion.

Dies ist die einfache Nachricht, die in der hier angezeigten benutzerdefinierten Funktion mit Hilfe von definiert wurde hauptsächlich() Funktion.
Leere:
Im oben genannten Fall haben wir festgestellt, dass der Rückgabetyp der benutzerdefinierten Funktion ungültig ist. Dies zeigt an, dass von der Funktion kein Wert zurückgegeben wird. Dies bedeutet, dass der Wert nicht vorhanden oder wahrscheinlich null ist. Denn wann immer eine Funktion nur die Nachrichten druckt, benötigt sie keinen Rückgabewert.
Diese Leerstelle wird in ähnlicher Weise im Parameterraum der Funktion verwendet, um deutlich zu machen, dass diese Funktion keinen tatsächlichen Wert annimmt, während sie aufgerufen wird. In der obigen Situation würden wir auch die anrufen Arbeit() funktionieren als:
Nichtige Arbeit ( Leere ){
Cout << „Eine Arbeit verdient Respekt ! ” ;
}
Die eigentlichen Parameter:
Man kann Parameter für die Funktion definieren. Die Parameter einer Funktion werden in der Argumentliste der Funktion definiert, die zum Namen der Funktion hinzugefügt wird. Immer wenn wir die Funktion aufrufen, müssen wir die echten Werte der Parameter übergeben, um die Ausführung abzuschließen. Diese werden als Ist-Parameter abgeschlossen. Während die Parameter, die definiert werden, während die Funktion definiert wurde, als formale Parameter bekannt sind.
Beispiel:
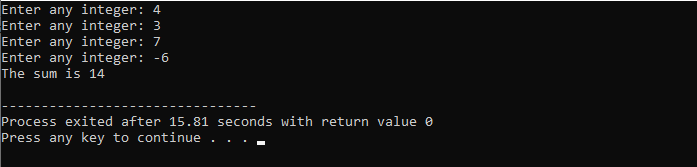
In diesem Beispiel sind wir dabei, die beiden ganzzahligen Werte durch eine Funktion auszutauschen oder zu ersetzen.
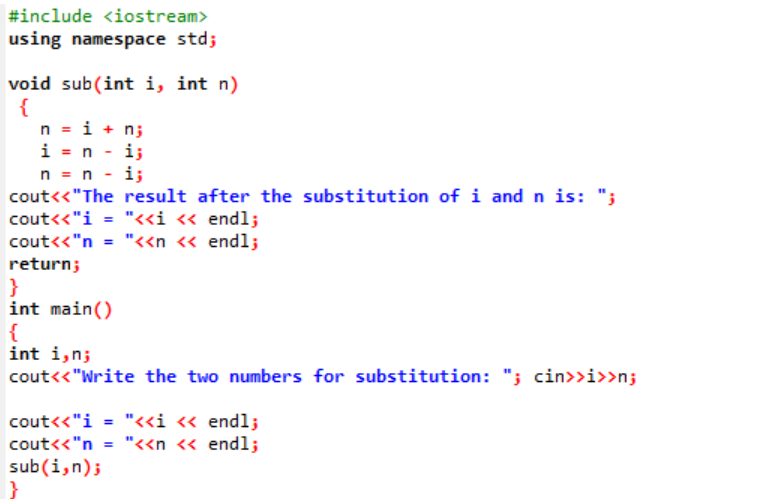
Am Anfang nehmen wir die Header-Datei auf. Die benutzerdefinierte Funktion ist der deklarierte und definierte Name sub(). Diese Funktion wird für die Substitution der beiden ganzzahligen Werte i und n verwendet. Als nächstes werden die arithmetischen Operatoren für den Austausch dieser beiden ganzen Zahlen verwendet. Der Wert der ersten ganzen Zahl „i“ wird anstelle des Werts „n“ gespeichert, und der Wert von n wird anstelle des Werts von „i“ gespeichert. Dann wird das Ergebnis nach dem Umschalten der Werte gedruckt. Wenn wir über die sprechen hauptsächlich() Funktion nehmen wir die Werte der beiden Ganzzahlen vom Benutzer entgegen und zeigen sie an. Im letzten Schritt die benutzerdefinierte Funktion sub() aufgerufen und die beiden Werte vertauscht werden.
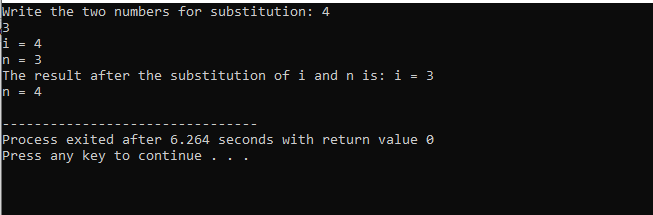
In diesem Fall der Ersetzung der beiden Zahlen können wir deutlich sehen, dass bei der Verwendung von die sub() Funktion sind die Werte von „i“ und „n“ in der Parameterliste die formalen Parameter. Die eigentlichen Parameter sind die Parameter, die am Ende übergeben werden hauptsächlich() Funktion, in der die Substitutionsfunktion aufgerufen wird.
C++-Zeiger:
Pointer in C++ ist viel einfacher zu erlernen und großartig zu verwenden. In der Sprache C++ werden Zeiger verwendet, weil sie unsere Arbeit erleichtern und alle Operationen mit großer Effizienz ablaufen, wenn Zeiger involviert sind. Außerdem gibt es einige Aufgaben, die nicht ausgeführt werden, wenn nicht Zeiger wie die dynamische Speicherzuweisung verwendet werden. Wenn wir über Zeiger sprechen, ist die Hauptidee, die man begreifen muss, dass der Zeiger nur eine Variable ist, die die genaue Speicheradresse als ihren Wert speichert. Die umfangreiche Verwendung von Zeigern in C++ hat folgende Gründe:
- Um eine Funktion an eine andere zu übergeben.
- Um die neuen Objekte auf dem Heap zuzuordnen.
- Für die Iteration von Elementen in einem Array
Normalerweise wird der Operator „&“ (kaufmännisches Und) verwendet, um auf die Adresse eines beliebigen Objekts im Speicher zuzugreifen.
Zeiger und ihre Typen:
Pointer hat folgende verschiedene Typen:
- Nullzeiger: Dies sind Zeiger mit einem Wert von Null, die in den C++-Bibliotheken gespeichert sind.
- Arithmetischer Zeiger: Es enthält vier wichtige arithmetische Operatoren, auf die zugegriffen werden kann: ++, –, +, -.
- Ein Array von Zeigern: Sie sind Arrays, die verwendet werden, um einige Zeiger zu speichern.
- Zeiger auf Zeiger: Hier wird ein Zeiger über einem Zeiger verwendet.
Beispiel:
Denken Sie über das folgende Beispiel nach, in dem die Adressen einiger Variablen gedruckt werden.
Nachdem wir die Header-Datei und den Standard-Namespace eingefügt haben, initialisieren wir zwei Variablen. Einer ist ein ganzzahliger Wert, der durch „i“ dargestellt wird, und ein anderer ist ein Zeichentyp-Array „I“ mit der Größe von 10 Zeichen. Die Adressen beider Variablen werden dann mit dem Befehl „cout“ angezeigt.
Die Ausgabe, die wir erhalten haben, ist unten dargestellt:
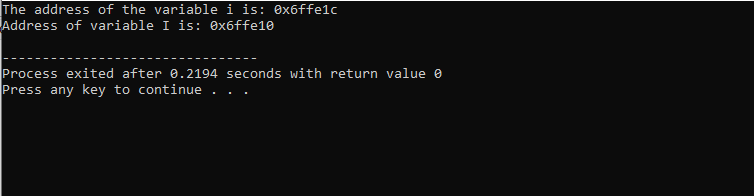
Dieses Ergebnis zeigt die Adresse für beide Variablen.
Andererseits wird ein Zeiger als Variable betrachtet, deren Wert selbst die Adresse einer anderen Variablen ist. Ein Zeiger zeigt immer auf einen Datentyp, der denselben Typ hat, der mit einem (*)-Operator erzeugt wird.
Deklaration eines Zeigers:
Der Zeiger wird so deklariert:
Typ * war - Name ;Der Basistyp des Zeigers wird durch „Typ“ angegeben, während der Name des Zeigers durch „Var-Name“ ausgedrückt wird. Und um eine Variable auf den Zeiger Asterisk (*) zu berechtigen, wird verwendet.
Möglichkeiten, den Variablen Pointer zuzuweisen:
Int * Pi ; //Zeiger eines Integer-DatentypsDoppelt * pd ; //Zeiger eines doppelten Datentyps
Schweben * pf ; //Zeiger eines Float-Datentyps
Verkohlen * Stk ; //Zeiger eines char-Datentyps
Fast immer gibt es eine lange Hexadezimalzahl, die die Speicheradresse darstellt, die anfänglich für alle Zeiger unabhängig von ihren Datentypen gleich ist.
Beispiel:
Das folgende Beispiel würde zeigen, wie Zeiger den Operator „&“ ersetzen und die Adresse von Variablen speichern.
Wir werden die Unterstützung für Bibliotheken und Verzeichnisse integrieren. Dann würden wir die aufrufen hauptsächlich() Funktion, in der wir zuerst eine Variable „n“ vom Typ „int“ mit dem Wert 55 deklarieren und initialisieren. In der nächsten Zeile initialisieren wir eine Zeigervariable namens „p1“. Danach weisen wir dem Zeiger „p1“ die Adresse der Variablen „n“ zu und zeigen dann den Wert der Variablen „n“. Die Adresse von „n“, die im Zeiger „p1“ gespeichert ist, wird angezeigt. Anschließend wird der Wert von „*p1“ mit dem Befehl „cout“ auf dem Bildschirm ausgegeben. Die Ausgabe ist wie folgt:
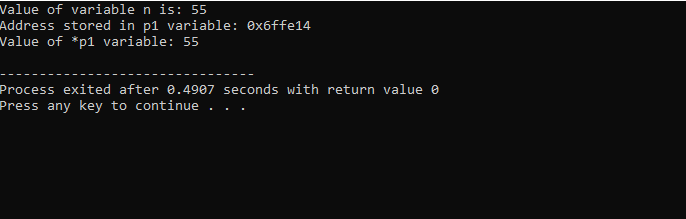
Hier sehen wir, dass der Wert von „n“ 55 ist und die Adresse von „n“, die im Zeiger „p1“ gespeichert wurde, als 0x6ffe14 angezeigt wird. Der Wert der Zeigervariablen wird gefunden und ist 55, was dem Wert der Integer-Variablen entspricht. Daher speichert ein Zeiger die Adresse der Variablen, und auch der *-Zeiger hat den Wert der gespeicherten Ganzzahl, die als Ergebnis den Wert der anfänglich gespeicherten Variablen zurückgibt.
Beispiel:
Betrachten wir ein weiteres Beispiel, bei dem wir einen Zeiger verwenden, der die Adresse einer Zeichenfolge speichert.
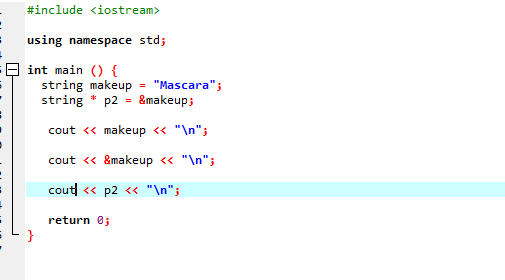
In diesem Code fügen wir zuerst Bibliotheken und Namensräume hinzu. In dem hauptsächlich() Funktion müssen wir einen String namens ‚makeup‘ deklarieren, der den Wert ‚Mascara‘ enthält. Ein String-Zeiger „*p2“ wird verwendet, um die Adresse der Make-up-Variablen zu speichern. Der Wert der Variablen „makeup“ wird dann mit der „cout“-Anweisung auf dem Bildschirm angezeigt. Danach wird die Adresse der Variablen „makeup“ gedruckt und am Ende wird die Zeigervariable „p2“ angezeigt, die die Speicheradresse der Variable „makeup“ mit dem Zeiger anzeigt.
Die vom obigen Code erhaltene Ausgabe lautet wie folgt:
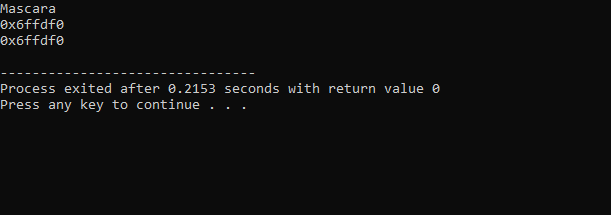
In der ersten Zeile wird der Wert der Variable „makeup“ angezeigt. Die zweite Zeile zeigt die Adresse der Variable ‚makeup‘. In der letzten Zeile wird die Speicheradresse der ‚Makeup‘-Variablen mit Verwendung des Zeigers angezeigt.
C++ Speicherverwaltung:
Für eine effektive Speicherverwaltung in C++ sind viele Operationen für die Speicherverwaltung während der Arbeit in C++ hilfreich. Wenn wir C++ verwenden, ist das am häufigsten verwendete Speicherzuweisungsverfahren die dynamische Speicherzuweisung, bei der den Variablen während der Laufzeit Speicher zugewiesen werden; nicht wie bei anderen Programmiersprachen, bei denen der Compiler den Variablen den Speicher zuweisen könnte. In C++ ist die Freigabe der dynamisch zugewiesenen Variablen notwendig, damit der Speicher freigegeben wird, wenn die Variable nicht mehr verwendet wird.
Für die dynamische Zuweisung und Freigabe des Speichers in C++ führen wir die ‘ Neu' und 'löschen' Operationen. Es ist wichtig, den Speicher so zu verwalten, dass kein Speicher verschwendet wird. Die Zuweisung des Speichers wird einfach und effektiv. In jedem C++-Programm wird der Speicher in einem von zwei Aspekten verwendet: entweder als Heap oder als Stack.
- Stapel : Alle Variablen, die innerhalb der Funktion deklariert sind, und alle anderen Details, die mit der Funktion zusammenhängen, werden im Stack gespeichert.
- Haufen : Jede Art von ungenutztem Speicher oder der Teil, aus dem wir den dynamischen Speicher während der Ausführung eines Programms zuweisen oder zuweisen, wird als Heap bezeichnet.
Bei der Verwendung von Arrays ist die Speicherzuweisung eine Aufgabe, bei der wir den Speicher nur zur Laufzeit bestimmen können. Also weisen wir dem Array den maximalen Speicher zu, aber das ist auch keine gute Praxis, da der Speicher in den meisten Fällen ungenutzt bleibt und irgendwie verschwendet wird, was einfach keine gute Option oder Praxis für Ihren PC ist. Aus diesem Grund haben wir einige Operatoren, die verwendet werden, um während der Laufzeit Speicher aus dem Heap zuzuweisen. Die beiden Hauptoperatoren „new“ und „delete“ werden für eine effiziente Speicherzuordnung und -freigabe verwendet.
Neuer C++-Operator:
Der neue Operator ist für die Allokation des Speichers zuständig und wird wie folgt verwendet:
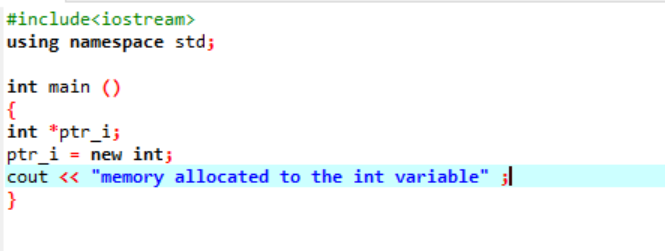
In diesen Code schließen wir die Bibliothek

Der Variable „int“ wurde mithilfe eines Zeigers erfolgreich Speicher zugewiesen.
C++-Löschoperator:
Immer wenn wir mit der Verwendung einer Variablen fertig sind, müssen wir den Speicher, den wir ihr einmal zugewiesen haben, freigeben, da er nicht mehr verwendet wird. Dazu verwenden wir den „delete“-Operator, um den Speicher freizugeben.
Das Beispiel, das wir uns jetzt ansehen werden, enthält beide Operatoren.
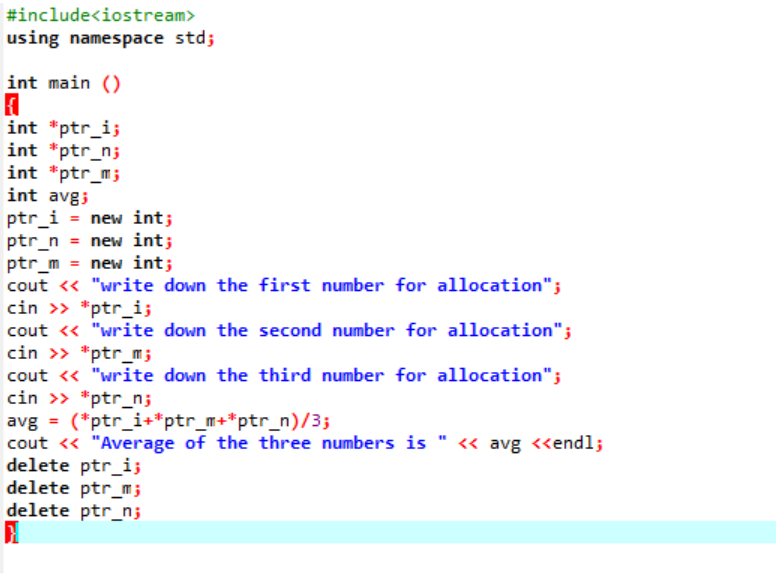
Wir berechnen den Durchschnitt für drei verschiedene Werte, die dem Benutzer entnommen wurden. Den Pointer-Variablen wird der Operator „new“ zugewiesen, um die Werte zu speichern. Die Durchschnittsformel wird implementiert. Danach wird der „delete“-Operator verwendet, der die Werte löscht, die mit dem „new“-Operator in den Pointer-Variablen gespeichert wurden. Dies ist die dynamische Zuordnung, bei der die Zuordnung während der Laufzeit erfolgt und die Freigabe kurz nach Beendigung des Programms erfolgt.
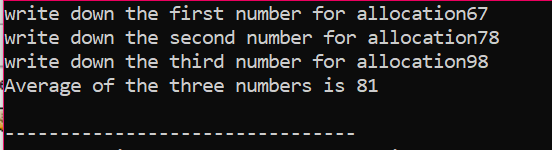
Verwendung des Arrays für die Speicherzuweisung:
Jetzt werden wir sehen, wie die Operatoren „new“ und „delete“ bei der Verwendung von Arrays verwendet werden. Die dynamische Zuordnung erfolgt auf die gleiche Weise wie bei den Variablen, da die Syntax fast gleich ist.
Im gegebenen Fall betrachten wir das Array von Elementen, deren Wert vom Benutzer übernommen wird. Die Elemente des Arrays werden genommen und die Zeigervariable deklariert und dann der Speicher zugewiesen. Kurz nach der Speicherallokation wird die Eingabeprozedur der Array-Elemente gestartet. Als nächstes wird die Ausgabe für die Array-Elemente mithilfe einer „for“-Schleife angezeigt. Diese Schleife hat die Iterationsbedingung von Elementen mit einer Größe, die kleiner ist als die tatsächliche Größe des Arrays, das durch n dargestellt wird.
Wenn alle Elemente verwendet werden und keine weitere Anforderung besteht, sie erneut zu verwenden, wird der den Elementen zugewiesene Speicher mit dem Operator „delete“ freigegeben.
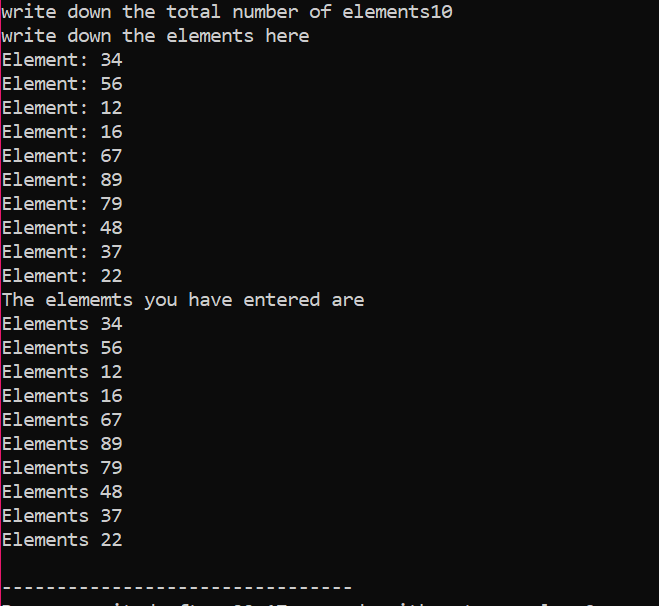
In der Ausgabe konnten wir doppelt gedruckte Wertesätze sehen. Die erste „for“-Schleife wurde zum Aufschreiben der Werte für Elemente verwendet, und die andere „for“-Schleife wird zum Drucken der bereits geschriebenen Werte verwendet, die zeigen, dass der Benutzer diese Werte zur Verdeutlichung geschrieben hat.
Vorteile:
Die Operatoren „new“ und „delete“ haben in der Programmiersprache C++ immer Priorität und werden häufig verwendet. Bei gründlicher Diskussion und Verständnis wird festgestellt, dass der „neue“ Operator zu viele Vorteile hat. Die Vorteile des „neuen“ Operators für die Allokation des Speichers sind folgende:
- Der neue Operator kann einfacher überladen werden.
- Beim Zuweisen von Speicher während der Laufzeit wird immer dann, wenn nicht genügend Speicher vorhanden ist, eine automatische Ausnahme ausgelöst, anstatt nur das Programm zu beenden.
- Die Hektik der Verwendung des Typecasting-Verfahrens entfällt hier, da der „neue“ Operator genau denselben Typ hat wie der Speicher, den wir zugewiesen haben.
- Der „new“-Operator verwirft auch die Idee, den sizeof()-Operator zu verwenden, da „new“ zwangsläufig die Größe der Objekte berechnet.
- Der „new“-Operator ermöglicht es uns, die Objekte zu initialisieren und zu deklarieren, obwohl er den Platz für sie spontan generiert.
C++-Arrays:
Wir werden eine gründliche Diskussion darüber führen, was Arrays sind und wie sie in einem C++-Programm deklariert und implementiert werden. Das Array ist eine Datenstruktur, die zum Speichern mehrerer Werte in nur einer Variablen verwendet wird, wodurch die Hektik reduziert wird, viele Variablen unabhängig voneinander zu deklarieren.
Deklaration von Arrays:
Um ein Array zu deklarieren, muss man zuerst den Variablentyp definieren und dem Array einen passenden Namen geben, der dann entlang der eckigen Klammern hinzugefügt wird. Diese enthält die Anzahl der Elemente, die die Größe eines bestimmten Arrays anzeigen.
Zum Beispiel:
String-Make-up [ 5 ] ;Diese Variable wird deklariert und zeigt, dass sie fünf Strings in einem Array namens „makeup“ enthält. Um die Werte für dieses Array zu identifizieren und zu veranschaulichen, müssen wir die geschweiften Klammern verwenden, wobei jedes Element separat in doppelte Anführungszeichen eingeschlossen ist, die jeweils durch ein einzelnes Komma dazwischen getrennt sind.
Zum Beispiel:
String-Make-up [ 5 ] = { 'Maskara' , 'Farbton' , 'Lippenstift' , 'Stiftung' , 'Zuerst' } ;Wenn Sie Lust haben, ein weiteres Array mit einem anderen Datentyp zu erstellen, der „int“ sein soll, dann wäre die Vorgehensweise dieselbe, Sie müssen nur den Datentyp der Variablen wie unten gezeigt ändern:
int Vielfache [ 5 ] = { zwei , 4 , 6 , 8 , 10 } ;Bei der Zuweisung von Integer-Werten an das Array darf man diese nicht in Anführungszeichen setzen, was nur für die String-Variable funktionieren würde. Ein Array ist also eine Sammlung zusammenhängender Datenelemente mit darin gespeicherten abgeleiteten Datentypen.
Wie greifen Sie auf Elemente im Array zu?
Allen im Array enthaltenen Elementen wird eine eindeutige Nummer zugewiesen, die ihre Indexnummer ist, die für den Zugriff auf ein Element aus dem Array verwendet wird. Der Indexwert beginnt mit 0 bis eins weniger als die Größe des Arrays. Der allererste Wert hat den Indexwert 0.
Beispiel:
Betrachten Sie ein sehr einfaches und einfaches Beispiel, in dem wir Variablen in einem Array initialisieren.
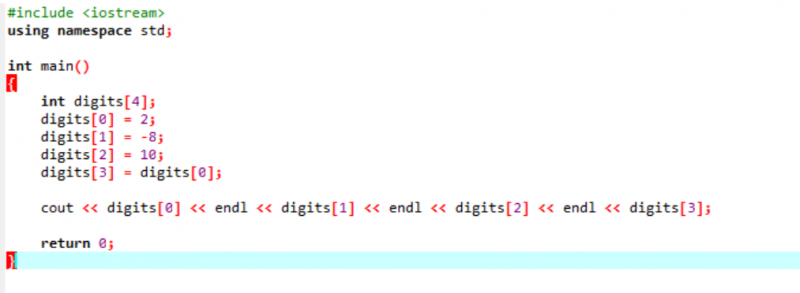
Im allerersten Schritt binden wir die Header-Datei
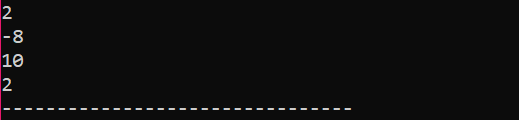
Dies ist das vom obigen Code erhaltene Ergebnis. Das Schlüsselwort „endl“ verschiebt das andere Element automatisch in die nächste Zeile.
Beispiel:
In diesem Code verwenden wir eine „for“-Schleife zum Drucken der Elemente eines Arrays.

Im obigen Fall fügen wir die wesentliche Bibliothek hinzu. Der Standard-Namespace wird hinzugefügt. Das hauptsächlich() Funktion ist die Funktion, bei der wir alle Funktionalitäten für die Ausführung eines bestimmten Programms ausführen werden. Als nächstes deklarieren wir ein Array vom Typ Int mit dem Namen „Num“, das eine Größe von 10 hat. Der Wert dieser zehn Variablen wird dem Benutzer mit der Verwendung der „for“-Schleife entnommen. Für die Darstellung dieses Arrays wird wieder eine ‚for‘-Schleife verwendet. Die im Array gespeicherten 10 Integer werden mit Hilfe der ‚cout‘-Anweisung angezeigt.
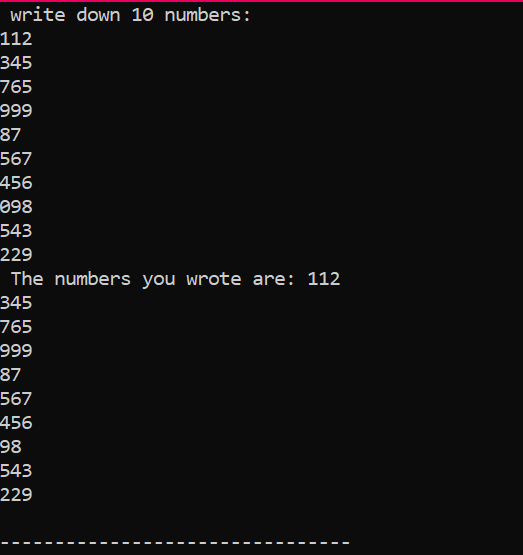
Dies ist die Ausgabe, die wir bei der Ausführung des obigen Codes erhalten haben und die 10 Ganzzahlen mit unterschiedlichen Werten zeigt.
Beispiel:
In diesem Szenario ermitteln wir die durchschnittliche Punktzahl eines Schülers und den Prozentsatz, den er in der Klasse erzielt hat.
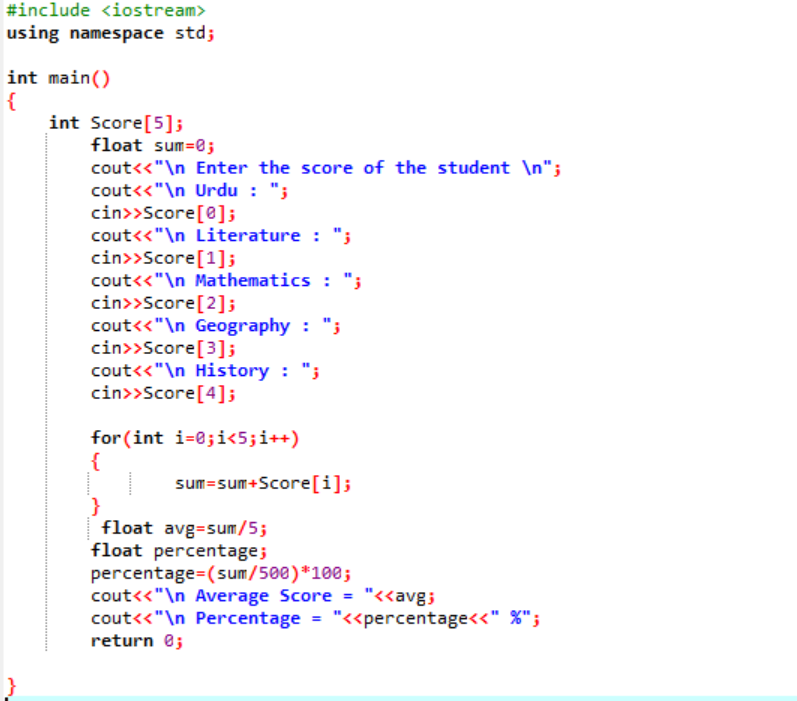
Zunächst müssen Sie eine Bibliothek hinzufügen, die das C++-Programm anfänglich unterstützt. Als nächstes geben wir die Größe 5 des Arrays mit dem Namen „Score“ an. Dann haben wir eine Variable „sum“ vom Datentyp Float initialisiert. Die Punktzahlen der einzelnen Fächer werden vom Benutzer manuell übernommen. Dann wird eine „for“-Schleife verwendet, um den Durchschnitt und den Prozentsatz aller eingeschlossenen Probanden zu ermitteln. Die Summe wird durch die Verwendung des Arrays und der „for“-Schleife erhalten. Dann wird der Durchschnitt unter Verwendung der Durchschnittsformel gefunden. Nachdem wir den Durchschnitt ermittelt haben, übergeben wir seinen Wert an den Prozentsatz, der zur Formel hinzugefügt wird, um den Prozentsatz zu erhalten. Der Durchschnitt und der Prozentsatz werden dann berechnet und angezeigt.
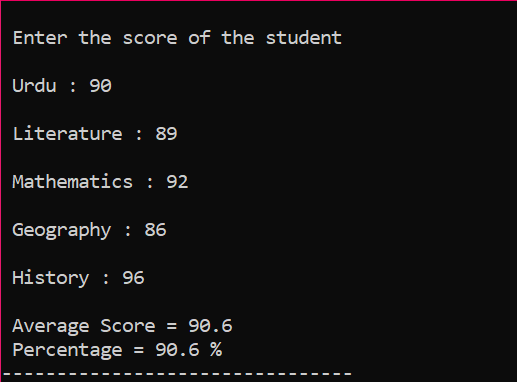
Dies ist die endgültige Ausgabe, bei der die Punktzahlen vom Benutzer für jedes Fach einzeln übernommen und der Durchschnitt bzw. der Prozentsatz berechnet werden.
Vorteile der Verwendung von Arrays:
- Auf die Elemente im Array kann aufgrund der ihnen zugewiesenen Indexnummer leicht zugegriffen werden.
- Wir können die Suchoperation einfach über ein Array ausführen.
- Falls Sie Komplexität in der Programmierung wünschen, können Sie ein zweidimensionales Array verwenden, das auch die Matrizen charakterisiert.
- Um mehrere Werte zu speichern, die einen ähnlichen Datentyp haben, könnte ein Array einfach verwendet werden.
Nachteile der Verwendung von Arrays:
- Arrays haben eine feste Größe.
- Arrays sind homogen, was bedeutet, dass nur ein einziger Werttyp gespeichert wird.
- Arrays speichern Daten einzeln im physischen Speicher.
- Der Einfüge- und Löschvorgang ist für Arrays nicht einfach.
C++-Objekte und -Klassen:
C++ ist eine objektorientierte Programmiersprache, was bedeutet, dass Objekte in C++ eine wichtige Rolle spielen. Wenn man über Objekte spricht, muss man zuerst überlegen, was Objekte sind, also ist ein Objekt jede Instanz der Klasse. Da sich C++ mit den Konzepten von OOP befasst, sind die wichtigsten zu diskutierenden Dinge die Objekte und die Klassen. Klassen sind in der Tat Datentypen, die vom Benutzer selbst definiert werden und dazu bestimmt sind, die Datenelemente und Funktionen zu kapseln, auf die nur zugegriffen werden kann, wenn die Instanz für die bestimmte Klasse erstellt wird. Datenmember sind die Variablen, die innerhalb der Klasse definiert sind.
Klasse ist mit anderen Worten eine Gliederung oder ein Design, das für die Definition und Deklaration der Datenelemente und die diesen Datenelementen zugewiesenen Funktionen verantwortlich ist. Jedes der in der Klasse deklarierten Objekte wäre in der Lage, alle von der Klasse demonstrierten Eigenschaften oder Funktionen gemeinsam zu nutzen.
Angenommen, es gibt eine Klasse namens Vögel, dann könnten zunächst alle Vögel fliegen und Flügel haben. Daher ist das Fliegen ein Verhalten, das diese Vögel annehmen, und die Flügel sind Teil ihres Körpers oder ein grundlegendes Merkmal.
Klasse definieren:
Um eine Klasse zu definieren, müssen Sie die Syntax nachverfolgen und entsprechend Ihrer Klasse zurücksetzen. Das Schlüsselwort „class“ wird zum Definieren der Klasse verwendet, und alle anderen Datenelemente und Funktionen werden innerhalb der geschweiften Klammern definiert, gefolgt von der Definition der Klasse.
KlassennameDerKlasse
{
Zugriffsbezeichner :
Datenmitglieder ;
Datenelementfunktionen ( ) ;
} ;
Objekte deklarieren:
Kurz nach der Definition einer Klasse müssen wir die Objekte für den Zugriff erstellen und die Funktionen definieren, die von der Klasse angegeben wurden. Dazu müssen wir den Namen der Klasse und dann den Namen des zu deklarierenden Objekts schreiben.
Zugriff auf Datenmitglieder:
Auf die Funktionen und Datenelemente wird mit Hilfe eines einfachen Punktoperators zugegriffen. Auf die öffentlichen Datenelemente wird auch mit diesem Operator zugegriffen, aber im Fall der privaten Datenelemente können Sie einfach nicht direkt darauf zugreifen. Der Zugriff der Datenmitglieder hängt von den Zugriffskontrollen ab, die ihnen von den Zugriffsmodifikatoren gegeben werden, die entweder privat, öffentlich oder geschützt sind. Hier ist ein Szenario, das zeigt, wie die einfache Klasse, Datenmember und Funktionen deklariert werden.
Beispiel:
In diesem Beispiel werden wir einige Funktionen definieren und mit Hilfe der Objekte auf die Klassenfunktionen und Datenelemente zugreifen.
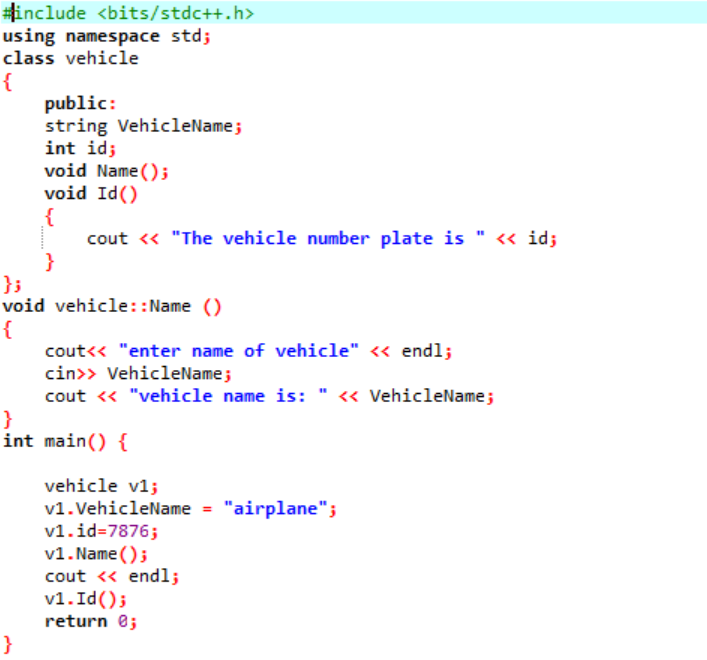
Im ersten Schritt integrieren wir die Bibliothek, danach müssen wir die unterstützenden Verzeichnisse einbinden. Die Klasse wird explizit definiert, bevor die aufgerufen wird hauptsächlich() Funktion. Diese Klasse wird als „Fahrzeug“ bezeichnet. Die Datenelemente waren der „Name des Fahrzeugs“ und die „ID“ dieses Fahrzeugs, bei dem es sich um das Kennzeichen dieses Fahrzeugs mit einer Zeichenfolge bzw. einem int-Datentyp handelt. Die beiden Funktionen werden für diese beiden Datenmember deklariert. Das Ich würde() Funktion zeigt die ID des Fahrzeugs an. Da die Datenmitglieder der Klasse öffentlich sind, können wir auch außerhalb der Klasse darauf zugreifen. Deshalb rufen wir die Name() Funktion außerhalb der Klasse und dann den Wert für den ‚VehicleName‘ vom Benutzer übernehmen und im nächsten Schritt ausdrucken. In dem hauptsächlich() function deklarieren wir ein Objekt der erforderlichen Klasse, das beim Zugriff auf die Datenelemente und Funktionen der Klasse hilft. Außerdem initialisieren wir die Werte für den Namen und die ID des Fahrzeugs nur dann, wenn der Benutzer den Wert für den Namen des Fahrzeugs nicht angibt.
Dies ist die Ausgabe, die der Benutzer erhält, wenn er den Namen für das Fahrzeug selbst eingibt und die Nummernschilder der ihm zugewiesene statische Wert sind.
Wenn man über die Definition der Elementfunktionen spricht, muss man verstehen, dass es nicht immer zwingend erforderlich ist, die Funktion innerhalb der Klasse zu definieren. Wie Sie im obigen Beispiel sehen können, definieren wir die Funktion der Klasse außerhalb der Klasse, da die Datenmitglieder öffentlich deklariert werden, und dies geschieht mit Hilfe des Bereichsauflösungsoperators, der als „::“ zusammen mit dem Namen von angezeigt wird die Klasse und den Namen der Funktion.
C++ Konstruktoren und Destruktoren:
Wir werden dieses Thema anhand von Beispielen ausführlich behandeln. Das Löschen und Erstellen der Objekte in der C++-Programmierung sind sehr wichtig. Aus diesem Grund rufen wir in einigen Fällen automatisch die Konstruktormethoden auf, wenn wir eine Instanz für eine Klasse erstellen.
Konstrukteure:
Wie der Name schon sagt, leitet sich ein Konstruktor vom Wort „Konstrukt“ ab, das die Erstellung von etwas angibt. Ein Konstruktor ist also als abgeleitete Funktion der neu erstellten Klasse definiert, die den Namen der Klasse teilt. Und es wird für die Initialisierung der in der Klasse enthaltenen Objekte verwendet. Außerdem hat ein Konstruktor keinen Rückgabewert für sich selbst, was bedeutet, dass sein Rückgabetyp auch nicht ungültig ist. Es ist nicht zwingend, die Argumente zu akzeptieren, aber man kann sie bei Bedarf hinzufügen. Konstruktoren sind nützlich, um dem Objekt einer Klasse Speicher zuzuweisen und den Anfangswert für die Mitgliedsvariablen festzulegen. Der Anfangswert könnte in Form von Argumenten an die Konstruktorfunktion übergeben werden, sobald das Objekt initialisiert ist.
Syntax:
NameDerKlasse ( ){
// Körper des Konstruktors
}
Arten von Konstruktoren:
Parametrisierter Konstruktor:
Wie bereits erwähnt, hat ein Konstruktor keinen Parameter, aber man kann einen Parameter seiner Wahl hinzufügen. Dadurch wird der Wert des Objekts initialisiert, während es erstellt wird. Um dieses Konzept besser zu verstehen, betrachten Sie das folgende Beispiel:
Beispiel:
In diesem Fall würden wir einen Konstruktor der Klasse erstellen und Parameter deklarieren.
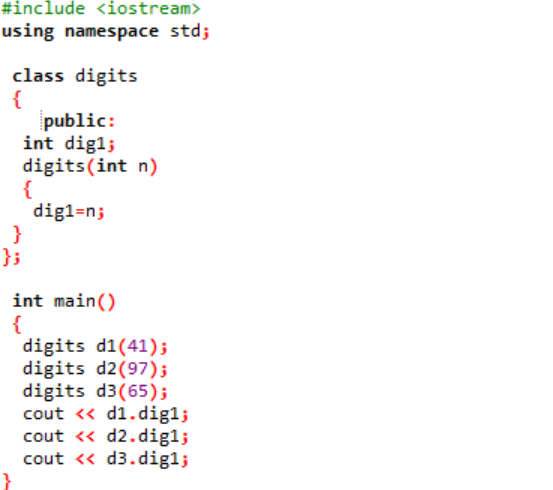
Wir binden die Header-Datei im allerersten Schritt ein. Der nächste Schritt bei der Verwendung eines Namensraums ist die Unterstützung von Verzeichnissen für das Programm. Eine Klasse namens „Ziffern“ wird deklariert, wo zunächst die Variablen öffentlich initialisiert werden, damit sie im gesamten Programm zugänglich sind. Eine Variable namens „dig1“ mit dem Datentyp Integer wird deklariert. Als nächstes haben wir einen Konstruktor deklariert, dessen Name dem Namen der Klasse ähnelt. Diesem Konstruktor wird eine Integer-Variable als „n“ übergeben, und die Klassenvariable „dig1“ wird gleich n gesetzt. In dem hauptsächlich() Funktion des Programms werden drei Objekte für die Klasse „Ziffern“ erstellt und einigen zufälligen Werten zugewiesen. Diese Objekte werden dann verwendet, um die Klassenvariablen aufzurufen, denen automatisch dieselben Werte zugewiesen werden.
Die ganzzahligen Werte werden auf dem Bildschirm als Ausgabe dargestellt.

Konstruktor kopieren:
Es ist die Art von Konstruktor, der die Objekte als Argumente betrachtet und die Werte der Datenelemente eines Objekts auf das andere dupliziert. Daher werden diese Konstruktoren verwendet, um ein Objekt vom anderen zu deklarieren und zu initialisieren. Dieser Vorgang wird als Kopierinitialisierung bezeichnet.
Beispiel:
In diesem Fall wird der Kopierkonstruktor deklariert.

Zuerst integrieren wir die Bibliothek und das Verzeichnis. Eine Klasse namens „New“ wird deklariert, in der die Integer als „e“ und „o“ initialisiert werden. Der Konstruktor wird öffentlich gemacht, wo den beiden Variablen die Werte zugewiesen werden und diese Variablen in der Klasse deklariert werden. Anschließend werden diese Werte mit Hilfe des angezeigt hauptsächlich() Funktion mit „int“ als Rückgabetyp. Das Anzeige() Funktion wird aufgerufen und danach definiert, wo die Zahlen auf dem Bildschirm angezeigt werden. Im Inneren des hauptsächlich() Funktion werden die Objekte erstellt und diese zugewiesenen Objekte werden mit zufälligen Werten initialisiert und dann die Anzeige() Methode verwendet wird.
Die Ausgabe, die durch die Verwendung des Kopierkonstruktors empfangen wird, wird unten gezeigt.

Zerstörer:
Wie der Name schon sagt, werden die Destruktoren verwendet, um die vom Konstruktor erstellten Objekte zu zerstören. Vergleichbar mit den Konstruktoren haben die Destruktoren den gleichen Namen wie die Klasse, jedoch mit einer zusätzlichen Tilde (~) gefolgt.
Syntax:
~Neu ( ){
}
Der Destruktor nimmt keine Argumente entgegen und hat nicht einmal einen Rückgabewert. Der Compiler appelliert implizit an das Verlassen des Programms, um Speicher zu bereinigen, auf den nicht mehr zugegriffen werden kann.
Beispiel:
In diesem Szenario verwenden wir einen Destruktor zum Löschen eines Objekts.
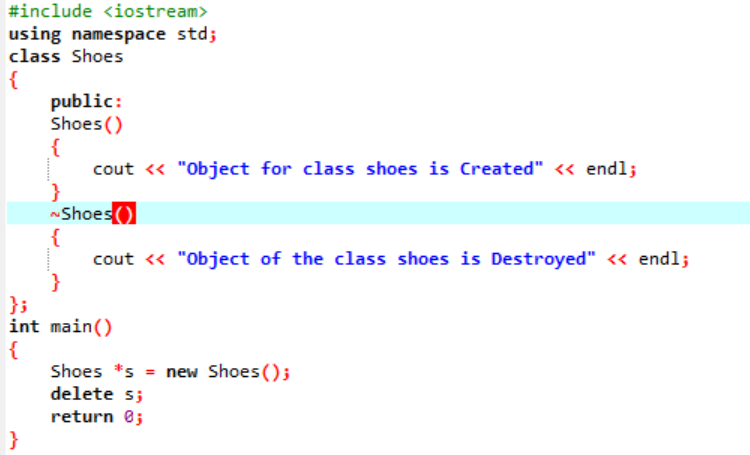
Hier wird eine ‚Schuhe‘-Klasse gemacht. Es wird ein Konstruktor erstellt, der einen ähnlichen Namen wie die Klasse hat. Im Konstruktor wird eine Meldung angezeigt, wo das Objekt erstellt wird. Nach dem Konstruktor wird der Destruktor erstellt, der die mit dem Konstruktor erstellten Objekte löscht. In dem hauptsächlich() Funktion wird ein Zeigerobjekt mit dem Namen „s“ erstellt und ein Schlüsselwort „delete“ wird verwendet, um dieses Objekt zu löschen.

Dies ist die Ausgabe, die wir von dem Programm erhalten haben, in dem der Destruktor das erstellte Objekt löscht und zerstört.
Unterschied zwischen Konstruktoren und Destruktoren:
| Konstrukteure | Zerstörer |
| Erstellt die Instanz der Klasse. | Zerstört die Instanz der Klasse. |
| Es hat Argumente entlang des Klassennamens. | Es hat keine Argumente oder Parameter |
| Wird aufgerufen, wenn das Objekt erstellt wird. | Wird aufgerufen, wenn das Objekt zerstört wird. |
| Weist Objekten den Speicher zu. | Gibt den Speicher von Objekten frei. |
| Kann überladen werden. | Kann nicht überladen werden. |
C++-Vererbung:
Jetzt lernen wir etwas über die C++-Vererbung und ihren Geltungsbereich.
Vererbung ist die Methode, durch die eine neue Klasse generiert oder von einer bestehenden Klasse abgeleitet wird. Die aktuelle Klasse wird als 'Basisklasse' oder auch als 'Elternklasse' und die neu geschaffene Klasse als 'abgeleitete Klasse' bezeichnet. Wenn wir sagen, dass eine Kindklasse von einer Elternklasse geerbt wird, bedeutet das, dass das Kind alle Eigenschaften der Elternklasse besitzt.
Vererbung bezieht sich auf eine (ist eine) Beziehung. Wir nennen jede Beziehung eine Vererbung, wenn „ist-ein“ zwischen zwei Klassen verwendet wird.
Zum Beispiel:
- Ein Papagei ist ein Vogel.
- Ein Computer ist eine Maschine.
Syntax:
In der C++-Programmierung verwenden oder schreiben wir Vererbung wie folgt:
Klasse < abgeleitet - Klasse >: < Zugang - Bezeichner >< Base - Klasse >Modi der C++-Vererbung:
Die Vererbung umfasst 3 Modi zum Vererben von Klassen:
- Öffentlichkeit: Wenn in diesem Modus eine untergeordnete Klasse deklariert wird, werden Elemente einer übergeordneten Klasse von der untergeordneten Klasse als dieselben in einer übergeordneten Klasse geerbt.
- Geschützt: I In diesem Modus werden die öffentlichen Mitglieder der Elternklasse zu geschützten Mitgliedern in der Kindklasse.
- Privatgelände : In diesem Modus werden alle Mitglieder einer übergeordneten Klasse privat in der untergeordneten Klasse.
Arten der C++-Vererbung:
Im Folgenden sind die Arten der C++-Vererbung aufgeführt:
1. Einfache Vererbung:
Bei dieser Art der Vererbung gehen Klassen von einer Basisklasse aus.
Syntax:
Klasse M{
Körper
} ;
Klasse n : öffentlich m
{
Körper
} ;
2. Mehrfachvererbung:
Bei dieser Art der Vererbung kann eine Klasse von verschiedenen Basisklassen abstammen.
Syntax:
Klasse M{
Körper
} ;
Klasse n
{
Körper
} ;
Klasse o : öffentlich m , öffentlich n
{
Körper
} ;
3. Mehrstufige Vererbung:
Bei dieser Form der Vererbung ist eine Kindklasse von einer anderen Kindklasse abgeleitet.
Syntax:
Klasse M{
Körper
} ;
Klasse n : öffentlich m
{
Körper
} ;
Klasse o : öffentlich n
{
Körper
} ;
4. Hierarchische Vererbung:
Bei dieser Vererbungsmethode werden aus einer Basisklasse mehrere Unterklassen gebildet.
Syntax:
Klasse M{
Körper
} ;
Klasse n : öffentlich m
{
Körper
} ;
Klasse o : öffentlich m
{
} ;
5. Hybride Vererbung:
Bei dieser Art der Vererbung werden mehrere Vererbungen zusammengefasst.
Syntax:
Klasse M{
Körper
} ;
Klasse n : öffentlich m
{
Körper
} ;
Klasse o
{
Körper
} ;
Klasse p : öffentlich n , öffentlich o
{
Körper
} ;
Beispiel:
Wir werden den Code ausführen, um das Konzept der Mehrfachvererbung in der C++-Programmierung zu demonstrieren.
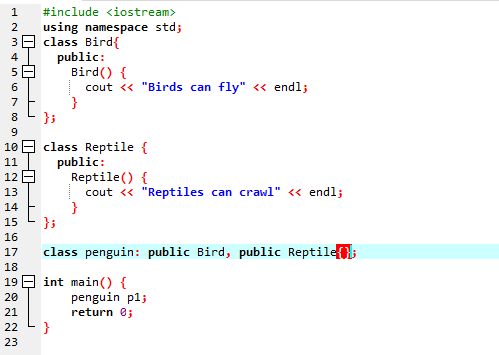
Da wir mit einer Standard-Eingabe-Ausgabe-Bibliothek begonnen haben, haben wir der Basisklasse den Namen „Bird“ gegeben und sie öffentlich gemacht, damit ihre Mitglieder zugänglich sind. Dann haben wir die Basisklasse „Reptile“ und wir haben sie auch veröffentlicht. Dann haben wir 'cout', um die Ausgabe zu drucken. Danach haben wir einen „Pinguin“ der Kinderklasse erstellt. In dem hauptsächlich() Funktion haben wir zum Objekt der Klasse Pinguin „p1“ gemacht. Zuerst wird die Klasse „Bird“ ausgeführt und dann die Klasse „Reptile“.
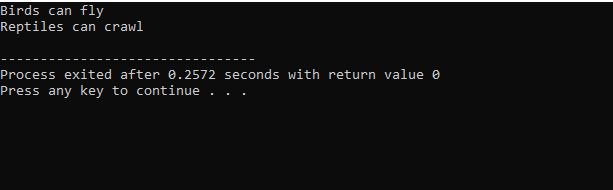
Nach der Ausführung des Codes in C++ erhalten wir die Ausgabeanweisungen der Basisklassen „Bird“ und „Reptile“. Das bedeutet, dass eine Klasse „Pinguin“ von den Basisklassen „Vogel“ und „Reptil“ abgeleitet wird, da ein Pinguin sowohl ein Vogel als auch ein Reptil ist. Es kann sowohl fliegen als auch kriechen. Daher bewiesen Mehrfachvererbungen, dass eine untergeordnete Klasse von vielen Basisklassen abgeleitet werden kann.
Beispiel:
Hier führen wir ein Programm aus, um zu zeigen, wie Multilevel-Vererbung genutzt wird.
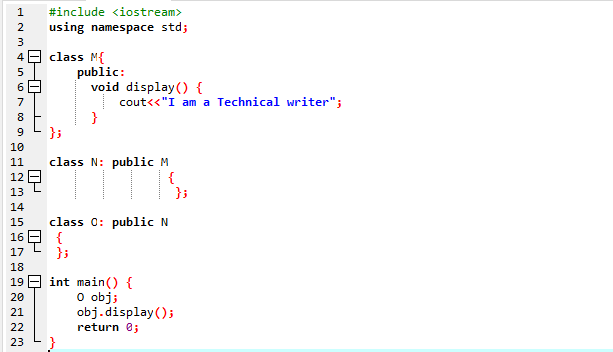
Wir haben unser Programm mit Input-Output-Streams gestartet. Dann haben wir eine Elternklasse „M“ deklariert, die öffentlich ist. Wir haben die angerufen Anzeige() Funktion und den Befehl „cout“, um die Anweisung anzuzeigen. Als Nächstes haben wir eine untergeordnete Klasse „N“ erstellt, die von der übergeordneten Klasse „M“ abgeleitet ist. Wir haben eine neue untergeordnete Klasse „O“, die von der untergeordneten Klasse „N“ abgeleitet ist, und der Körper beider abgeleiteter Klassen ist leer. Am Ende berufen wir uns auf die hauptsächlich() Funktion, in der wir das Objekt der Klasse ‚O‘ initialisieren müssen. Das Anzeige() Die Funktion des Objekts wird verwendet, um das Ergebnis zu demonstrieren.
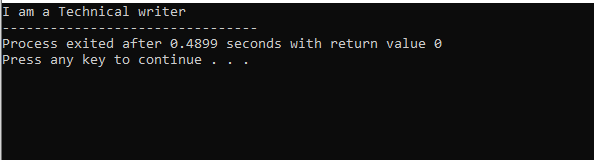
In dieser Abbildung haben wir das Ergebnis der Klasse „M“, die die Elternklasse ist, weil wir a hatten Anzeige() Funktion darin. Die Klasse „N“ wird also von der Elternklasse „M“ und die Klasse „O“ von der Elternklasse „N“ abgeleitet, was sich auf die mehrstufige Vererbung bezieht.
C++ Polymorphismus:
Der Begriff „Polymorphismus“ steht für eine Sammlung von zwei Wörtern 'poly' und ' Morphismus . Das Wort „Poly“ steht für „viele“ und „Morphismus“ steht für „Formen“. Polymorphismus bedeutet, dass sich ein Objekt unter verschiedenen Bedingungen unterschiedlich verhalten kann. Es ermöglicht einem Programmierer, den Code wiederzuverwenden und zu erweitern. Derselbe Code verhält sich je nach Bedingung unterschiedlich. Die Ausführung eines Objekts kann zur Laufzeit verwendet werden.
Kategorien von Polymorphismus:
Polymorphismus tritt hauptsächlich auf zwei Arten auf:
- Kompilierzeit-Polymorphismus
- Laufzeitpolymorphismus
Lassen Sie uns erklären.
6. Kompilierzeit-Polymorphismus:
Während dieser Zeit wird das eingegebene Programm in ein ausführbares Programm geändert. Vor der Bereitstellung des Codes werden die Fehler erkannt. Es gibt hauptsächlich zwei Kategorien davon.
- Funktionsüberlastung
- Bedienerüberladung
Schauen wir uns an, wie wir diese beiden Kategorien verwenden.
7. Funktionsüberladung:
Dies bedeutet, dass eine Funktion verschiedene Aufgaben ausführen kann. Die Funktionen werden als überladen bezeichnet, wenn es mehrere Funktionen mit einem ähnlichen Namen, aber unterschiedlichen Argumenten gibt.
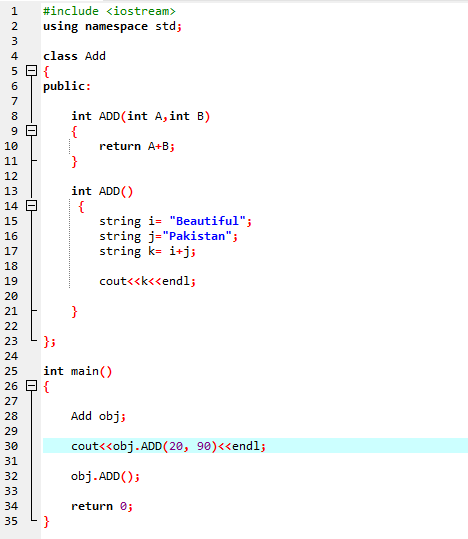
Zunächst verwenden wir die Bibliothek
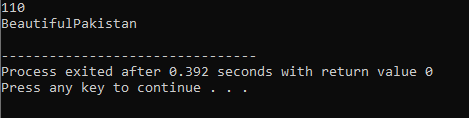
Operatorüberladung:
Der Vorgang des Definierens mehrerer Funktionalitäten eines Operators wird als Überladen von Operatoren bezeichnet.
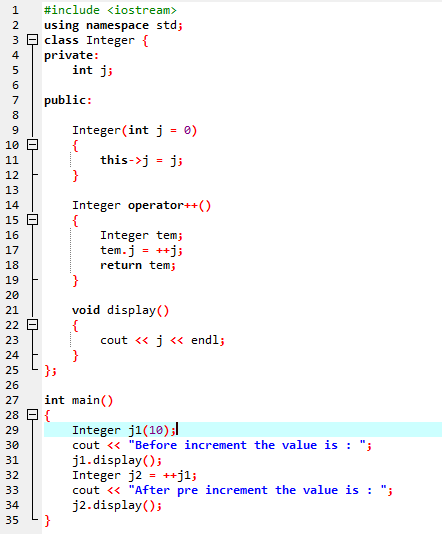
Das obige Beispiel enthält die Header-Datei
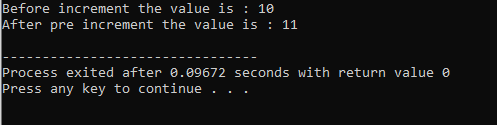
8. Laufzeitpolymorphismus:
Es ist die Zeitspanne, in der der Code ausgeführt wird. Nach dem Einsatz des Codes können Fehler erkannt werden.
Funktionsüberschreibung:
Dies geschieht, wenn eine abgeleitete Klasse eine ähnliche Funktionsdefinition wie eine der Elementfunktionen der Basisklasse verwendet.
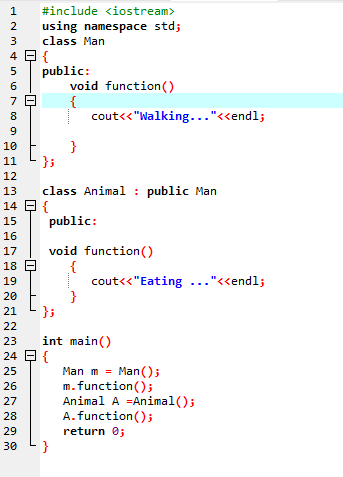
In der ersten Zeile binden wir die Bibliothek
C++-Strings:
Jetzt werden wir entdecken, wie man den String in C++ deklariert und initialisiert. Der String wird verwendet, um eine Gruppe von Zeichen im Programm zu speichern. Es speichert alphabetische Werte, Ziffern und spezielle Typensymbole im Programm. Es reservierte Zeichen als Array im C++-Programm. Arrays werden verwendet, um eine Sammlung oder Kombination von Zeichen in der C++-Programmierung zu reservieren. Ein spezielles Symbol, das als Nullzeichen bekannt ist, wird verwendet, um das Array zu beenden. Sie wird durch die Escape-Sequenz (\0) dargestellt und wird verwendet, um das Ende der Zeichenfolge anzugeben.
Holen Sie sich die Zeichenfolge mit dem Befehl „cin“:
Es wird verwendet, um eine Zeichenfolgenvariable ohne Leerzeichen einzugeben. Im gegebenen Fall implementieren wir ein C++-Programm, das den Namen des Benutzers mit dem Befehl „cin“ erhält.
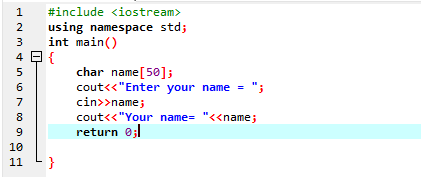
Im ersten Schritt verwenden wir die Bibliothek
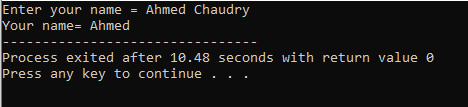
Der Benutzer gibt den Namen „Ahmed Chaudry“ ein. Als Ausgabe erhalten wir aber nur „Ahmed“ und nicht das komplette „Ahmed Chaudry“, da der „cin“-Befehl keinen String mit Leerzeichen speichern kann. Es speichert nur den Wert vor dem Leerzeichen.
Rufen Sie die Zeichenfolge mit der Funktion cin.get() ab:
Das erhalten() Die Funktion des Befehls cin wird verwendet, um die Zeichenfolge von der Tastatur abzurufen, die Leerzeichen enthalten kann.
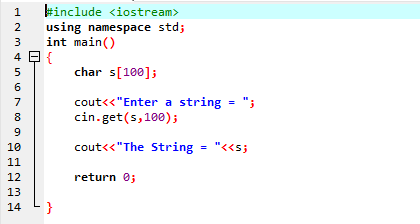
Das obige Beispiel enthält die Bibliothek
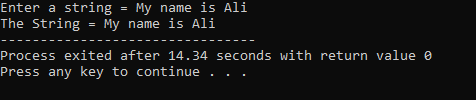
Eine Zeichenfolge „Mein Name ist Ali“ wird vom Benutzer eingegeben. Als Ergebnis erhalten wir den kompletten String „My name is Ali“, weil die Funktion cin.get() die Strings akzeptiert, die die Leerzeichen enthalten.
Verwenden eines 2D (zweidimensionalen) Arrays von Zeichenfolgen:
In diesem Fall nehmen wir Eingaben (Name von drei Städten) vom Benutzer entgegen, indem wir ein 2D-Array von Zeichenfolgen verwenden.
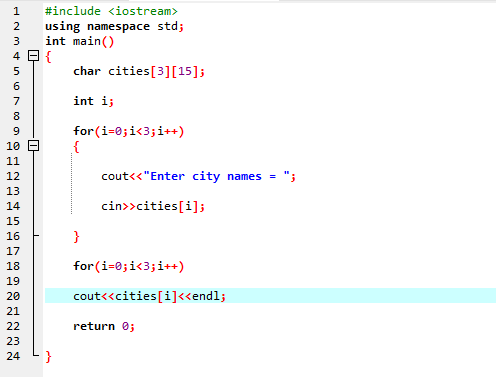
Zuerst integrieren wir die Header-Datei
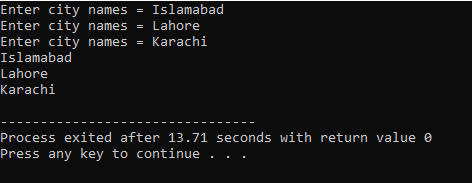
Hier gibt der Benutzer den Namen von drei verschiedenen Städten ein. Das Programm verwendet einen Zeilenindex, um drei Zeichenfolgenwerte zu erhalten. Jeder Wert bleibt in einer eigenen Zeile erhalten. Die erste Zeichenfolge wird in der ersten Zeile gespeichert und so weiter. Jeder Zeichenfolgenwert wird auf die gleiche Weise angezeigt, indem der Zeilenindex verwendet wird.
C++-Standardbibliothek:
Die C++-Bibliothek ist ein Cluster oder eine Gruppierung vieler Funktionen, Klassen, Konstanten und aller verwandten Elemente, die fast in einem richtigen Satz eingeschlossen sind und immer die standardisierten Header-Dateien definieren und deklarieren. Die Implementierung dieser enthält zwei neue Header-Dateien namens
Die Standardbibliothek beseitigt die Hektik des Neuschreibens der Anweisungen während der Programmierung. Darin befinden sich viele Bibliotheken, die Code für viele Funktionen gespeichert haben. Um diese Bibliotheken sinnvoll nutzen zu können, ist es zwingend erforderlich, sie mit Hilfe von Header-Dateien einzubinden. Wenn wir die Eingabe- oder Ausgabebibliothek importieren, bedeutet dies, dass wir den gesamten Code importieren, der in dieser Bibliothek gespeichert wurde, und so können wir auch die darin enthaltenen Funktionen verwenden, indem wir den gesamten zugrunde liegenden Code ausblenden, den Sie möglicherweise nicht benötigen sehen.
Die C++-Standardbibliothek unterstützt die folgenden zwei Typen:
- Eine gehostete Implementierung, die alle wesentlichen Kopfzeilendateien der Standardbibliothek bereitstellt, die vom C++-ISO-Standard beschrieben werden.
- Eine eigenständige Implementierung, die nur einen Teil der Header-Dateien aus der Standardbibliothek benötigt. Die passende Teilmenge ist:
| Atomic_signed_lock_free und Atomic-unsigned_lock_free) |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
| |
| |
|
|
Einige der Header-Dateien wurden beklagt, seit die letzten 11 C++ kamen: Das sind
Die Unterschiede zwischen gehosteten und freistehenden Implementierungen sind wie folgt dargestellt:
- In der gehosteten Implementierung müssen wir eine globale Funktion verwenden, die die Hauptfunktion ist. In einer freistehenden Implementierung kann der Benutzer Start- und Endfunktionen selbst deklarieren und definieren.
- Bei einer Hosting-Implementierung muss zum Zeitpunkt des Abgleichs ein Thread ausgeführt werden. Während bei der freistehenden Implementierung die Implementierer selbst entscheiden, ob sie die Unterstützung des nebenläufigen Threads in ihrer Bibliothek benötigen.
Typen:
Sowohl die freistehende als auch die gehostete Version werden von C++ unterstützt. Die Header-Dateien sind in die folgenden zwei unterteilt:
- Iostream-Teile
- C++ STL-Teile (Standardbibliothek)
Wann immer wir ein Programm zur Ausführung in C++ schreiben, rufen wir immer die Funktionen auf, die bereits in der STL implementiert sind. Diese bekannten Funktionen nehmen Eingaben auf und zeigen Ausgaben unter Verwendung identifizierter Operatoren mit Effizienz an.
In Anbetracht der Geschichte wurde die STL ursprünglich als Standard-Vorlagenbibliothek bezeichnet. Dann wurden die Teile der STL-Bibliothek in der heute verwendeten Standardbibliothek von C++ standardisiert. Dazu gehören die ISO-C++-Laufzeitbibliothek und einige Fragmente aus der Boost-Bibliothek, einschließlich einiger anderer wichtiger Funktionen. Gelegentlich bezeichnet die STL die Container oder häufiger die Algorithmen der C++ Standard Library. Nun, diese STL- oder Standard-Vorlagenbibliothek spricht vollständig über die bekannte C++-Standardbibliothek.
Der std-Namespace und die Header-Dateien:
Alle Deklarationen von Funktionen oder Variablen erfolgen innerhalb der Standardbibliothek mit Hilfe von gleichmäßig verteilten Header-Dateien. Die Deklaration würde nur erfolgen, wenn Sie die Header-Dateien nicht einschließen.
Nehmen wir an, jemand verwendet Listen und Strings, er muss die folgenden Header-Dateien hinzufügen:
#include#include
Diese spitzen Klammern „<>“ bedeuten, dass man diese bestimmte Header-Datei in dem Verzeichnis suchen muss, das definiert und eingebunden wird. Man kann dieser Bibliothek auch eine Erweiterung „.h“ hinzufügen, was bei Bedarf oder Wunsch erfolgt. Wenn wir die ‚.h‘-Bibliothek ausschließen, brauchen wir einen Zusatz ‚c‘ direkt vor dem Anfang des Dateinamens, nur als Hinweis darauf, dass diese Header-Datei zu einer C-Bibliothek gehört. Sie können beispielsweise entweder schreiben (#include
Apropos Namensraum: Die gesamte C++-Standardbibliothek liegt in diesem als std bezeichneten Namensraum. Aus diesem Grund müssen die standardisierten Bibliotheksnamen von den Benutzern kompetent definiert werden. Zum Beispiel:
Std :: cout << „Das wird vorübergehen !/ n' ;C++-Vektoren:
Es gibt viele Möglichkeiten, Daten oder Werte in C++ zu speichern. Aber jetzt suchen wir nach der einfachsten und flexibelsten Möglichkeit, die Werte zu speichern, während wir die Programme in der Sprache C++ schreiben. Vektoren sind also Container, die in einem Serienmuster richtig sequenziert sind, dessen Größe zum Zeitpunkt der Ausführung je nach Einfügung und Abzug der Elemente variiert. Das bedeutet, dass der Programmierer während der Ausführung des Programms die Größe des Vektors nach seinen Wünschen ändern könnte. Sie ähneln den Arrays derart, dass sie auch über kommunizierbare Speicherplätze für ihre enthaltenen Elemente verfügen. Für die Überprüfung der Anzahl der in den Vektoren vorhandenen Werte oder Elemente müssen wir ein ‘ std::count’ Funktion. Vektoren sind in der Standard-Vorlagenbibliothek von C++ enthalten, daher gibt es eine bestimmte Header-Datei, die zuerst eingefügt werden muss, nämlich:
#einschließenErklärung:
Die Deklaration eines Vektors ist unten dargestellt.
Std :: Vektor < DT > NameVector ;Hier ist der Vektor das verwendete Schlüsselwort, das DT zeigt den Datentyp des Vektors, der durch int, float, char oder andere verwandte Datentypen ersetzt werden kann. Die obige Erklärung kann umgeschrieben werden als:
Vektor < schweben > Prozentsatz ;Die Größe für den Vektor wird nicht angegeben, da die Größe während der Ausführung zunehmen oder abnehmen kann.
Initialisierung von Vektoren:
Für die Initialisierung der Vektoren gibt es in C++ mehr als einen Weg.
Technik Nummer 1:
Vektor < int > v1 = { 71 , 98 , 3. 4 , 65 } ;Vektor < int > v2 = { 71 , 98 , 3. 4 , 65 } ;
In diesem Verfahren weisen wir die Werte für beide Vektoren direkt zu. Die beiden zugewiesenen Werte sind genau gleich.
Technik Nummer 2:
Vektor < int > v3 ( 3 , fünfzehn ) ;Bei diesem Initialisierungsprozess bestimmt 3 die Größe des Vektors und 15 sind die darin gespeicherten Daten oder Werte. Ein Vektor vom Datentyp „int“ mit der gegebenen Größe 3, der den Wert 15 speichert, wird erstellt, was bedeutet, dass der Vektor „v3“ Folgendes speichert:
Vektor < int > v3 = { fünfzehn , fünfzehn , fünfzehn } ;Hauptoperationen:
Die wichtigsten Operationen, die wir für die Vektoren innerhalb der Vektorklasse implementieren werden, sind:
- Einen Wert hinzufügen
- Zugriff auf einen Wert
- Ändern eines Wertes
- Löschen eines Werts
Ergänzung und Löschung:
Das Hinzufügen und Löschen der Elemente innerhalb des Vektors erfolgt systematisch. In den meisten Fällen werden Elemente am Ende der Vektorcontainer eingefügt, aber Sie können auch Werte an der gewünschten Stelle hinzufügen, wodurch die anderen Elemente schließlich an ihre neuen Positionen verschoben werden. Während beim Löschen, wenn die Werte von der letzten Position gelöscht werden, die Größe des Containers automatisch reduziert wird. Aber wenn die Werte innerhalb des Containers zufällig von einem bestimmten Ort gelöscht werden, werden die neuen Orte automatisch den anderen Werten zugewiesen.
Verwendete Funktionen:
Um die im Vektor gespeicherten Werte zu ändern oder zu ändern, gibt es einige vordefinierte Funktionen, die als Modifikatoren bekannt sind. Sie sind wie folgt:
- Insert(): Es wird zum Hinzufügen eines Werts innerhalb eines Vektorcontainers an einer bestimmten Stelle verwendet.
- Erase(): Es wird zum Entfernen oder Löschen eines Werts innerhalb eines Vektorcontainers an einer bestimmten Stelle verwendet.
- Swap(): Wird für den Austausch der Werte innerhalb eines Vektorcontainers verwendet, der zum gleichen Datentyp gehört.
- Assign(): Wird für die Zuordnung eines neuen Werts zu dem zuvor gespeicherten Wert innerhalb des Vektorcontainers verwendet.
- Begin(): Es wird verwendet, um einen Iterator innerhalb einer Schleife zurückzugeben, die den ersten Wert des Vektors innerhalb des ersten Elements adressiert.
- Clear(): Wird zum Löschen aller in einem Vektorcontainer gespeicherten Werte verwendet.
- Push_back(): Es wird zum Hinzufügen eines Werts am Ende des Vektorcontainers verwendet.
- Pop_back(): Wird zum Löschen eines Werts beim Beenden des Vektorcontainers verwendet.
Beispiel:
In diesem Beispiel werden Modifikatoren entlang der Vektoren verwendet.
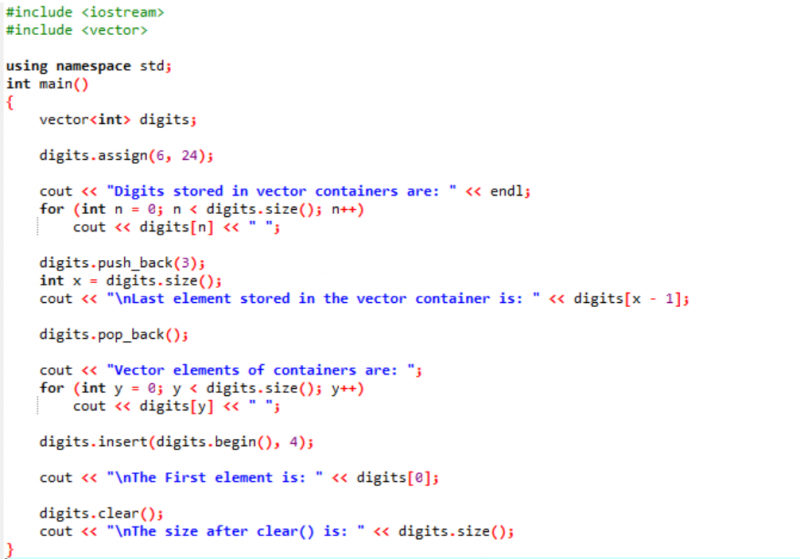
Zuerst binden wir die Header-Dateien
Die Ausgabe ist unten gezeigt.

C++-Dateien Eingabe Ausgabe:
Eine Datei ist eine Ansammlung zusammenhängender Daten. In C++ ist eine Datei eine Folge von Bytes, die in chronologischer Reihenfolge gesammelt werden. Die meisten Dateien befinden sich auf der Festplatte. Aber auch Hardwaregeräte wie Magnetbänder, Drucker und Kommunikationsleitungen sind in den Dateien enthalten.
Die Ein- und Ausgabe in Dateien wird durch die drei Hauptklassen charakterisiert:
- Die Klasse „istream“ wird zum Entgegennehmen von Eingaben verwendet.
- Die Klasse „ostream“ wird zum Anzeigen von Ausgaben verwendet.
- Verwenden Sie für Ein- und Ausgabe die Klasse „iostream“.
Dateien werden in C++ als Streams behandelt. Wenn wir Eingaben und Ausgaben in eine Datei oder aus einer Datei übernehmen, werden die folgenden Klassen verwendet:
- Offstream: Es ist eine Stream-Klasse, die zum Schreiben in eine Datei verwendet wird.
- Ifstream: Es ist eine Stream-Klasse, die zum Lesen von Inhalten aus einer Datei verwendet wird.
- Strom: Es ist eine Stream-Klasse, die sowohl zum Lesen als auch zum Schreiben in einer Datei oder aus einer Datei verwendet wird.
Die Klassen „istream“ und „ostream“ sind die Vorfahren aller oben erwähnten Klassen. Die Dateistreams sind so einfach zu verwenden wie die Befehle „cin“ und „cout“, mit dem Unterschied, dass diese Dateistreams anderen Dateien zugeordnet werden. Sehen wir uns ein Beispiel an, um die Klasse „fstream“ kurz zu studieren:
Beispiel:
In diesem Fall schreiben wir Daten in eine Datei.
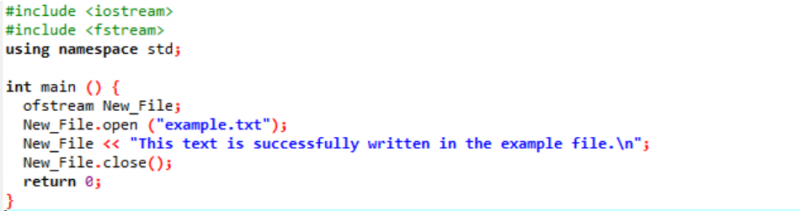
Wir integrieren im ersten Schritt den Input- und Output-Stream. Die Header-Datei

Die Datei „Beispiel“ wird vom PC aus geöffnet und der in der Datei geschriebene Text wird wie oben gezeigt in diese Textdatei eingeprägt.
Öffnen einer Datei:
Wenn eine Datei geöffnet wird, wird sie durch einen Stream dargestellt. Für die Datei wird ein Objekt erstellt, so wie New_File im vorherigen Beispiel erstellt wurde. Alle Eingabe- und Ausgabeoperationen, die für den Stream durchgeführt wurden, werden automatisch auf die Datei selbst angewendet. Zum Öffnen einer Datei wird die Funktion open() verwendet als:
Offen ( Dateiname , Modus ) ;Hier ist der Modus nicht obligatorisch.
Schließen einer Datei:
Sobald alle Eingabe- und Ausgabevorgänge abgeschlossen sind, müssen wir die Datei schließen, die zum Bearbeiten geöffnet wurde. Wir sind verpflichtet, a nah dran() funktionieren in dieser Situation.
Neue Datei. nah dran ( ) ;Danach ist die Datei nicht mehr verfügbar. Wenn das Objekt unter irgendwelchen Umständen zerstört wird, selbst wenn es mit der Datei verknüpft ist, ruft der Destruktor spontan die Funktion close() auf.
Textdateien:
Textdateien werden verwendet, um den Text zu speichern. Wenn der Text entweder eingegeben oder angezeigt wird, muss er daher einige Formatierungsänderungen aufweisen. Der Schreibvorgang innerhalb der Textdatei ist derselbe wie beim Ausführen des Befehls „cout“.
Beispiel:
In diesem Szenario schreiben wir Daten in die Textdatei, die bereits in der vorherigen Abbildung erstellt wurde.
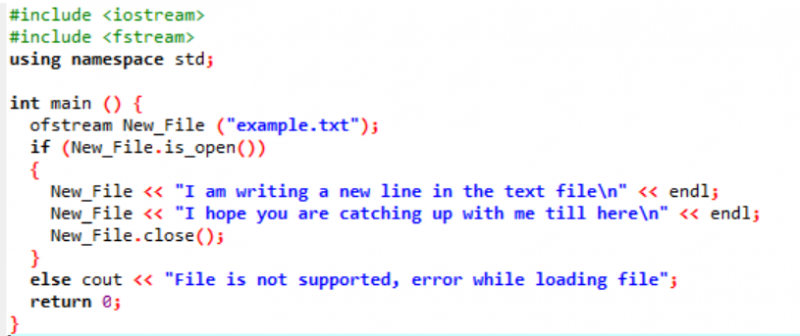
Hier schreiben wir Daten in die Datei mit dem Namen „Beispiel“, indem wir die Funktion New_File() verwenden. Wir öffnen die Datei ‚example‘ mit der offen() Methode. Der „ofstream“ wird verwendet, um die Daten der Datei hinzuzufügen. Nachdem die gesamte Arbeit in der Datei erledigt ist, wird die erforderliche Datei durch die Verwendung von geschlossen nah dran() Funktion. Wenn die Datei nicht geöffnet wird, wird die Fehlermeldung „Datei wird nicht unterstützt, Fehler beim Laden der Datei“ angezeigt.

Die Datei wird geöffnet und der Text wird auf der Konsole angezeigt.
Lesen einer Textdatei:
Das Einlesen einer Datei wird anhand des nachfolgenden Beispiels gezeigt.
Beispiel:
Der „ifstream“ wird zum Lesen der in der Datei gespeicherten Daten verwendet.
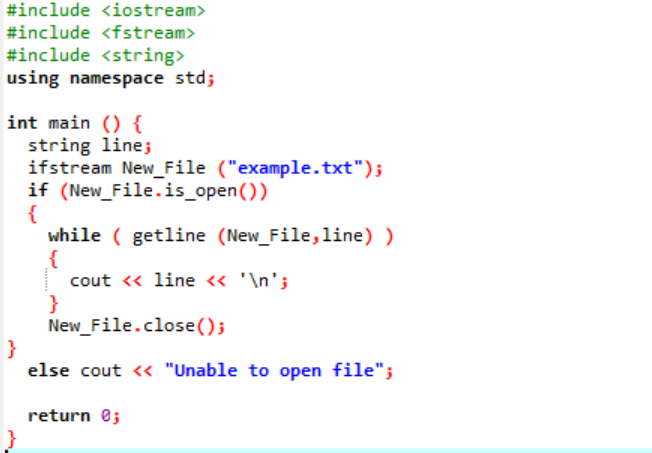
Das Beispiel enthält die wichtigsten Header-Dateien
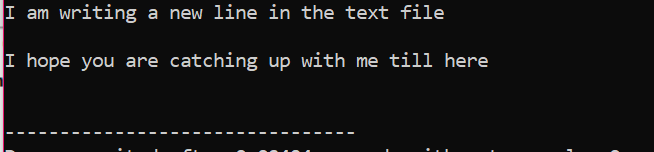
Alle in der Textdatei gespeicherten Informationen werden wie abgebildet auf dem Bildschirm angezeigt.
Fazit
In der obigen Anleitung haben wir die Sprache C++ im Detail kennengelernt. Zusammen mit den Beispielen wird jedes Thema demonstriert und erklärt, und jede Aktion wird ausgearbeitet.