Pandas Set_Option-Methode
Heute sehen wir uns an, wie Sie die Funktion „pd.set_option()“ verwenden, um alle Spalten im Pandas-Datenrahmen anzuzeigen, wenn Sie ihn in Ihrem Spyder-Tool präsentieren. Um die „pd.set_option()“ zu verwenden, folgen wir der angegebenen Syntax:

Beginnen wir mit dem Erlernen des Konzepts mit Hilfe der praktischen Implementierung des Python-Programms.
Beispiel: Verwenden der Set_Option-Methode von Pandas zum Anzeigen aller Spalten
Diese Demonstration ist eine Anleitung zum Anzeigen aller Spalten in einem DataFrame mithilfe von Pandas „set_option()“. Wir werden die Details jedes Schrittes für die Implementierung dieser Python-Methode verdeutlichen.
Die erste Voraussetzung für die praktische Umsetzung des Python-Skripts ist es, das beste Werkzeug herauszufinden, auf dem Sie Ihr Programm ausführen. Das Tool, das wir für unsere Illustration verwendet haben, ist das Tool „Spyder“. Wir haben das Tool gestartet und mit der Arbeit am Python-Skript begonnen.
Beginnend mit dem Code müssen wir zunächst die erforderlichen Bibliotheken importieren, die wir in diesem Programm benötigen. Die erste Bibliothek, die wir in unsere Python-Datei geladen haben, ist die Pandas-Bibliothek, da die Funktionen, die wir hier verwenden, von Pandas bereitgestellt werden. Wir haben diese Bibliothek als „pd“ bezeichnet. Die zweite Bibliothek, die wir geladen haben, ist die NumPy-Bibliothek. NumPy (Numerical Python) ist ein numerisches Rechenpaket, das über die Python-Programmierung entwickelt wurde. Der Abschnitt Import NumPy des Codes weist Python an, das NumPy-Modul in Ihre aktuelle Python-Datei zu integrieren. Der „as np“-Teil des Skripts weist dann Python an, NumPy die Abkürzung „np“ zuzuweisen. Es ermöglicht Ihnen, die NumPy-Methoden zu verwenden, indem Sie „np.function_name“ anstelle von NumPy eingeben.
Jetzt beginnen wir mit dem Hauptcode. Die wichtigste und grundlegende Anforderung für unser Programm ist der Pandas DataFrame. Wir zeigen also alle darin enthaltenen Spalten an. Jetzt liegt es ganz bei Ihnen, ob Sie einen DataFrame mit bestimmten Werten erstellen oder eine CSV-Datei importieren müssen. Was wir für diese Instanz gewählt haben, ist das Erstellen eines DataFrame mit NaN-Werten. Wir haben die Methode „pd.DataFrame()“ aufgerufen, um einen DataFrame zu erstellen. Hier haben wir zwei Parameter bereitgestellt – „Index“ und „Spalten“. Das Argument „index“ bezieht sich auf die Zeilen, was bedeutet, dass wir die Zeilen für den DataFrame festlegen.
Wir haben dem „index“-Parameter und der NumPy-Funktion „np.arange()“ einen Wert von „6“ zugewiesen. Es generiert sechs Zeilen für den DataFrame. Es füllt alle Einträge mit NaN-Werten, da wir es mit keinem Wert versehen haben. Das Argument „Spalten“ wird, wie der Name schon sagt, verwendet, um die Spalten für den DataFrame festzulegen. Ihm wird auch die Funktion „np.arange()“ mit „25“-Werten für die Spalten zugewiesen. Somit werden 25 Spalten für den DataFrame erstellt.
Wenn wir also die Funktion „pd.DataFrame()“ aufrufen, haben wir einen DataFrame mit 25 Spalten und 6 Zeilen, die mit Nullwerten gefüllt sind. Um diesen DataFrame beizubehalten, müssen wir ein DataFrame-Objekt erstellen, das seinen Inhalt speichert. Daher haben wir ein DataFrame-Objekt „zufällig“ erstellt und ihm das Ergebnis zugewiesen, das wir von der Methode „pd.DataFrame()“ erhalten. Jetzt möchten Sie sicherlich sehen, wie der DataFrame generiert wird. Python bietet uns eine Methode, um die Ausgabe auf dem Bildschirm anzuzeigen, nämlich die Funktion „print()“. Wir haben diese Methode aufgerufen, indem wir das DataFrame-Objekt „random“ als Parameter übergeben haben.
Wenn wir dieses Code-Snippet ausführen, bekommen wir unseren DataFrame mit NaN-Werten auf dem Terminal angezeigt. Hier können wir beobachten, dass einige der ersten Spalten und nur wenige vom Ende sichtbar sind. Alle dazwischen liegenden Spalten werden abgeschnitten. Standardmäßig werden einige der Zeilen und Spalten ausgeblendet, um den Benutzer nicht durch die Anzeige riesiger Datensätze zu frustrieren.
Sie können sogar die Anzahl der Gesamtspalten in einem DataFrame überprüfen, indem Sie die Funktion „len()“ von Pandas verwenden. Schreiben Sie die Funktion „len()“ auf die Konsole Ihres „Spyder“-Tools. Schreiben Sie den Namen des DataFrames zwischen seinen Klammern mit der Eigenschaft „.columns“. Es gibt uns die Gesamtlänge der Spalten in Ihrem DataFrame zurück.

Es gibt die Länge unseres DataFrame zurück, die 25 ist.
Die nächste und wichtigste Aufgabe besteht nun darin, die Standardoption zum Anzeigen der Ausgabe zu ändern. Es kann Situationen geben, in denen Sie den gesamten DataFrame auf dem Terminal anzeigen möchten. Aufgrund der Standardwerte werden viele Einträge abgeschnitten, was den Benutzer enttäuscht. Hier erfahren Sie, wie Sie dieses Problem lösen können. Pandas stellt uns eine „pd.set_option()“-Funktion zur Verfügung, um die Standardanzeigeeinstellungen zu ändern. Unmittelbar nach der Anzeige des DataFrame auf der Konsole rufen wir die Methode „pd.set_option()“ auf. Wir geben den Parameter zwischen den Klammern dieser Funktion an, den wir verwenden müssen, um alle Spalten des DataFrame anzuzeigen.
Hier haben wir „display.max_columns“ verwendet, um die maximalen Spalten in unserem DataFrame anzuzeigen. Wir können auch den Wert für diesen Parameter definieren, dh die maximalen Spalten, die Sie anzeigen möchten. Wir hingegen setzen „display.max_columns“ auf „None“, was alle Spalten aus dem DataFrame mit maximaler Länge anzeigt. Schließlich haben wir die Funktion „print()“ verwendet, um den resultierenden DataFrame mit allen auf dem Terminal sichtbaren Spalten anzuzeigen.
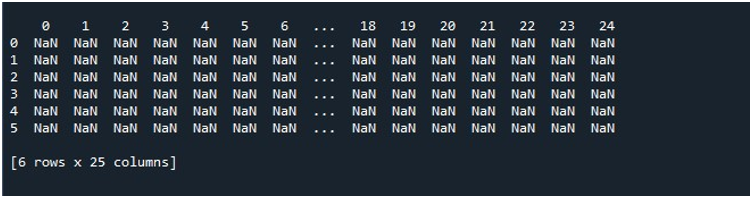
Wenn wir im Tool „Spyder“ auf die Option „Datei ausführen“ klicken, können wir einen angezeigten DataFrame anzeigen. Dieser DataFrame hat sechs Zeilen und die Anzahl der darin enthaltenen Spalten beträgt 25. Es gibt keine abgeschnittenen Spalten, da die Funktion „pd.set_option()“ mit maximaler Spaltenlänge jetzt aktiviert ist.
Wir können sogar die Anzeigeoption zurücksetzen, denn sobald wir die Anzeigelänge auf das Maximum gesetzt haben, werden weiterhin die DataFrames mit allen Spalten in dieser bestimmten Python-Datei angezeigt. Dazu verwenden wir die Pandas „pd.reset_option()“. Wir rufen diese Funktion auf und stellen die „display.max_columns“ als Parameter dieser Funktion bereit.

Dadurch erhalten wir die anfänglichen Anzeigeeinstellungen für den bereitgestellten DataFrame.
Fazit
Die vollständige Ausgabe auf dem Terminal mit einem riesigen Datensatz anzuzeigen, bringt uns manchmal in Schwierigkeiten, wenn die Standardeinstellungen des Tools im Widerspruch zu den Anforderungen des Benutzers stehen. Um diesen Rückschlag zu beheben, gibt uns Pandas die Methode „pd.set_option()“. In diesem Lernleitfaden haben wir Ihnen diese Methode und die Notwendigkeit ihrer Anwendung vorgestellt. Wir demonstrierten das Thema mit den praktisch kompilierten und ausgeführten Python-Beispielcodes. Wir haben die Ergebnisse der auf „Spyder“ durchgeführten Illustration gerendert. Wir haben erklärt, wie Sie alle Spalten des DataFrame auf der Konsole anzeigen können, indem Sie die Standardeinstellungen ändern und alle Einstellungen auf initial zurücksetzen. Wenn Sie der praktischen Umsetzung des Moduls volle Aufmerksamkeit schenken, können Sie es verwenden, wann immer Sie auf solche Probleme stoßen.