Erste Schritte mit Apache Kafka
Vor der Installation von Apache Kafka müssen Sie Java installiert und ein Benutzerkonto mit sudo-Berechtigungen haben. Darüber hinaus wird empfohlen, einen Arbeitsspeicher von 2 GB und mehr für den ordnungsgemäßen Betrieb von Kafka zu haben.
Die folgenden Schritte führen Sie durch die Installation von Apache Kafka.
Java installieren
Zur Installation von Kafka ist Java erforderlich. Überprüfen Sie, ob auf Ihrem Ubuntu Java installiert ist, indem Sie die Version mit dem folgenden Befehl überprüfen:
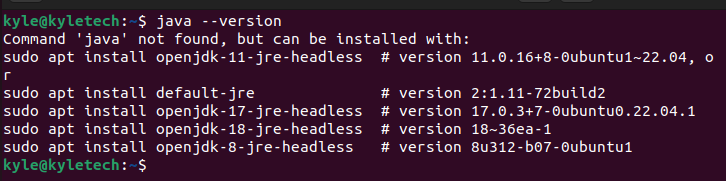
$ Java --Ausführung
Wenn Java nicht installiert ist, verwenden Sie die folgenden Befehle, um Java OpenJDK zu installieren.
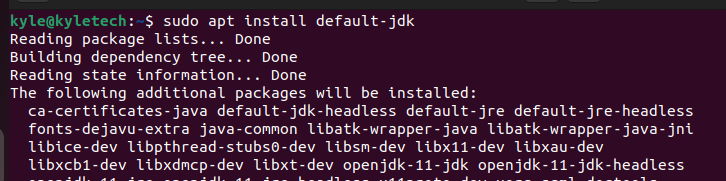
$ sudo geeignet Installieren default-jdk
Erstellen eines Benutzerkontos
Wenn Java bereits installiert ist, erstellen Sie ein Nicht-Root-Benutzerkonto. Wir müssen ihm auch einige sudo-Berechtigungen erteilen, indem wir den Benutzer mit dem folgenden Befehl zur sudo-Gruppe hinzufügen:
$ sudo adduser linuxhint
$ sudo adduser linuxhint sudo

Melden Sie sich bei dem neu erstellten Benutzerkonto an.

Kafka installieren
Sie müssen das neueste Apache Kafka von der offiziellen Download-Seite herunterladen. Laden Sie die Binärdateien mit der wget Befehl wie im Folgenden gezeigt:
$ wget https: // downloads.apache.org / Kafka / 3.2.3 / kafka_2.12-3.2.3.tgz 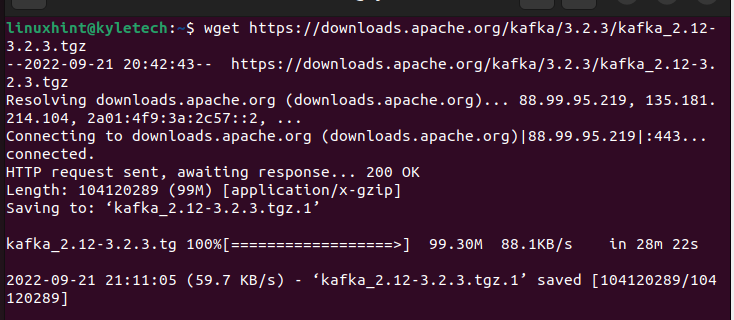
Nachdem die Binärdatei heruntergeladen wurde, extrahieren Sie sie mit der nimmt Befehl und verschieben Sie das extrahierte Verzeichnis in die /opt/kafka.
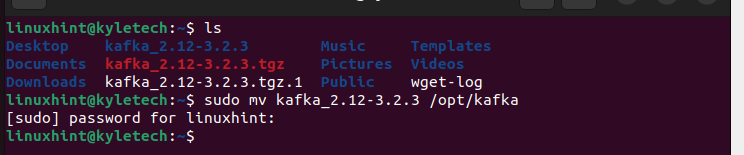
Als nächstes erstellen Sie die systemd-Skripte für die Tierpfleger und die Kafka Dienste, die beim Starten und Stoppen der Dienste helfen.
Verwenden Sie einen Editor Ihrer Wahl, um die systemd-Skripte zu erstellen, und fügen Sie die folgenden Inhalte ein. Beginnen Sie mit dem Tierpfleger:
$ sudo nano / etc / systemd / System / zookeeper.serviceFügen Sie Folgendes ein:
[ Einheit ]Beschreibung =Apache Zookeeper-Server
Dokumentation =http: // zookeeper.apache.org
Erfordert =Netzwerk.Ziel Remote-fs.Ziel
Nach =Netzwerk.Ziel Remote-fs.Ziel
[ Service ]
Typ =einfach
ExecStart = / opt / Kafka / Behälter / zookeeper-server-start.sh / opt / Kafka / Konfig / zookeeper.properties
ExecStop = / opt / Kafka / Behälter / zookeeper-server-stop.sh
Neu starten =on-abnormal
[ Installieren ]
Gesucht von =multi-user.ziel
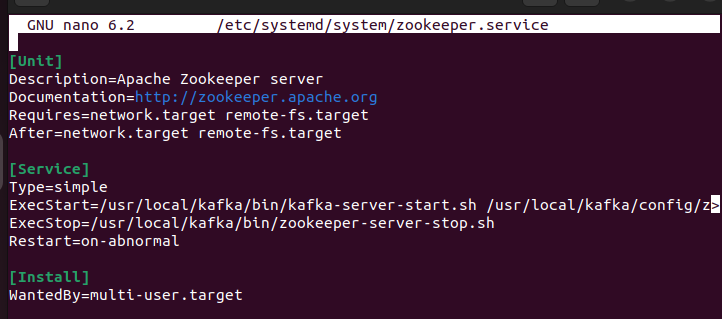
Speicher die Datei. Erstellen Sie die systemd-Datei für Kafka und fügen Sie den folgenden Inhalt ein:
Achten Sie beim Einfügen darauf, dass Sie den richtigen Pfad für das Java setzen, das Sie in Ihrem System installiert haben.
[ Einheit ]Beschreibung =Apache Kafka-Server
Dokumentation =http: // kafka.apache.org / Dokumentation.html
Erfordert =zookeeper.service
[ Service ]
Typ =einfach
Umfeld = 'JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64'
ExecStart = / opt / Kafka / Behälter / kafka-server-start.sh / opt / Kafka / Konfig / server.properties
ExecStop = / opt / Kafka / Behälter / kafka-server-stop.sh
Neu starten =on-abnormal
[ Installieren ]
Gesucht von =multi-user.ziel
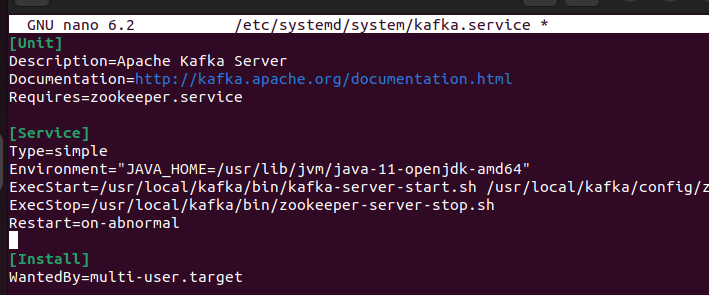
Wenn Sie fertig sind, wenden Sie die Änderungen an, indem Sie den systemd-Daemon neu laden:

Aktivieren Sie als Nächstes den Zookeeper-Dienst und starten Sie ihn mit den folgenden Befehlen:
$ sudo systemctl zookeepe starten < stark > r stark >

Dasselbe müssen Sie auch für Kafka tun:
$ sudo systemctl startet kafka

Sobald Sie die Dienste starten, können Sie ihren Status überprüfen, bevor wir ein Thema in Kafka erstellen.


Das Gute an Kafka ist, dass es mehrere Skripte gibt, die Sie verwenden können.
Lassen Sie uns ein neues Thema mit dem Namen erstellen linuxhint1 Verwendung der kafka-topics.sh Skript mit einer Partition und einer Replikation. Verwenden Sie den folgenden Befehl:
$ sudo -in Linuxhint / opt / Kafka / Behälter / kafka-topics.sh --schaffen --bootstrap-server lokaler Host: 9092 --replication-factor 1 --Partitionen 1 --Thema linuxhint1 
Beachten Sie, dass unser Thema erstellt wird. Wir können die vorherige Nachricht sehen, um dies zu überprüfen.
Alternativ können Sie die verfügbaren Themen auch über auflisten -aufführen Option im folgenden Befehl. Es sollte das von uns erstellte Thema zurückgeben:S
$ sudo -in Linuxhint / opt / Kafka / Behälter / kafka-topics.sh --aufführen --bootstrap-server lokaler Host: 9092 
Nachdem das Kafka-Thema erstellt wurde, können Sie damit beginnen, die Streams-Daten in die zu schreiben Kafka-console-producer.sh und prüfen Sie, ob es sich in Ihrem widerspiegelt verbraucher.sh.
Öffnen Sie Ihre Shell und greifen Sie auf das Thema zu, das wir mit der producer.sh erstellt haben, wie im Folgenden gezeigt:
$ sudo -in Linuxhint / opt / Kafka / Behälter / kafka-console-producer.sh --Broker-Liste lokaler Host: 9092 --Thema linuxhint1 
Öffnen Sie als Nächstes eine andere Shell und greifen Sie mit der Datei „consumer.sh“ auf das Kafka-Thema zu.

Wenn die beiden Shells geöffnet sind, können Sie auf der Produzentenkonsole Nachrichten senden. Was auch immer Sie eingeben, wird in der Verbraucherkonsole angezeigt und bestätigt, dass unser Apache Kafka betriebsbereit ist.
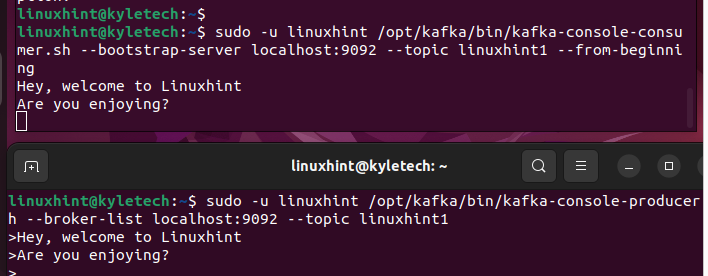
Fazit
Mit dieser Anleitung haben Sie jetzt alle Schritte, die Sie befolgen können, um Apache Kafka in Ihrem Ubuntu 22.04 zu installieren. Hoffentlich haben Sie es geschafft, jeden Schritt zu befolgen und Ihren Apache Kafka zu installieren und Themen zu erstellen, um eine einfache Verbraucher- und Produzentenproduktion auszuführen. Sie können dasselbe in einer großen Produktion implementieren.