Kurzer Überblick
Dieser Beitrag zeigt:
So implementieren Sie die ReAct-Logik mit Document Store in LangChain
- Frameworks installieren
- Bereitstellung des OpenAI-API-Schlüssels
- Bibliotheken importieren
- Verwendung des Wikipedia-Explorers
- Testen des Modells
Wie implementiert man die ReAct-Logik mit Document Store in LangChain?
Die Sprachmodelle werden anhand eines riesigen Datenpools trainiert, der in natürlichen Sprachen wie Englisch usw. geschrieben ist. Die Daten werden in den Dokumentspeichern verwaltet und gespeichert, und der Benutzer kann die Daten einfach aus dem Speicher laden und das Modell trainieren. Das Modelltraining kann mehrere Iterationen erfordern, da jede Iteration das Modell effektiver und verbessert.
Um den Prozess der Implementierung der ReAct-Logik für die Arbeit mit dem Dokumentenspeicher in LangChain zu erlernen, folgen Sie einfach dieser einfachen Anleitung:
Schritt 1: Frameworks installieren
Beginnen Sie zunächst mit der Implementierung der ReAct-Logik für die Arbeit mit dem Dokumentenspeicher, indem Sie das LangChain-Framework installieren. Durch die Installation des LangChain-Frameworks werden alle erforderlichen Abhängigkeiten abgerufen, um die Bibliotheken abzurufen oder zu importieren und den Vorgang abzuschließen:
pip langchain installieren
Installieren Sie die Wikipedia-Abhängigkeiten für dieses Handbuch, da es verwendet werden kann, um die Dokumentspeicher mit der ReAct-Logik zum Laufen zu bringen:
Pip Wikipedia installieren 
Installieren Sie die OpenAI-Module mit dem Befehl pip, um deren Bibliotheken abzurufen und Large Language Models oder LLMs zu erstellen:
pip openai installieren 
Schritt 2: Bereitstellung des OpenAI-API-Schlüssels
Nach der Installation aller erforderlichen Module einfach Umgebung einrichten Verwenden des API-Schlüssels aus dem OpenAI-Konto mit dem folgenden Code:
importieren Duimportieren getpass
Du . etwa [ „OPENAI_API_KEY“ ] = getpass . getpass ( „OpenAI-API-Schlüssel:“ )
Schritt 3: Bibliotheken importieren
Sobald die Umgebung eingerichtet ist, importieren Sie die Bibliotheken aus LangChain, die zum Konfigurieren der ReAct-Logik für die Arbeit mit den Dokumentspeichern erforderlich sind. Verwenden von LangChain-Agenten zum Abrufen des DocstoreExplaorer und Agenten mit seinen Typen zum Konfigurieren des Sprachmodells:
aus langchain. lms importieren OpenAIaus langchain. docstore importieren Wikipedia
aus langchain. Agenten importieren initialize_agent , Werkzeug
aus langchain. Agenten importieren AgentType
aus langchain. Agenten . reagieren . Base importieren DocstoreExplorer
Schritt 4: Verwenden des Wikipedia-Explorers
Konfigurieren Sie die „ docstore ”-Variable mit der DocstoreExplorer()-Methode und rufen Sie die Wikipedia()-Methode in ihrem Argument auf. Erstellen Sie das Large Language Model mit der OpenAI-Methode mit dem „ text-davinci-002 ”-Modell nach dem Festlegen der Tools für den Agenten:
docstore = DocstoreExplorer ( Wikipedia ( ) )Werkzeuge = [
Werkzeug (
Name = 'Suchen' ,
Funktion = docstore. suchen ,
Beschreibung = „Es wird verwendet, um bei der Suche Fragen/Eingabeaufforderungen zu stellen.“ ,
) ,
Werkzeug (
Name = 'Nachschlagen' ,
Funktion = docstore. Nachschlagen ,
Beschreibung = „Es wird zum Stellen von Abfragen/Eingabeaufforderungen mit Suche verwendet“ ,
) ,
]
llm = OpenAI ( Temperatur = 0 , Modellname = „text-davinci-002“ )
#Definieren der Variablen durch Konfigurieren des Modells mit dem Agenten
reagieren = initialize_agent ( Werkzeuge , llm , Agent = AgentType. REACT_DOCSTORE , ausführlich = WAHR )
Schritt 5: Testen des Modells
Sobald das Modell erstellt und konfiguriert ist, legen Sie die Fragezeichenfolge fest und führen Sie die Methode mit der Fragevariablen in ihrem Argument aus:
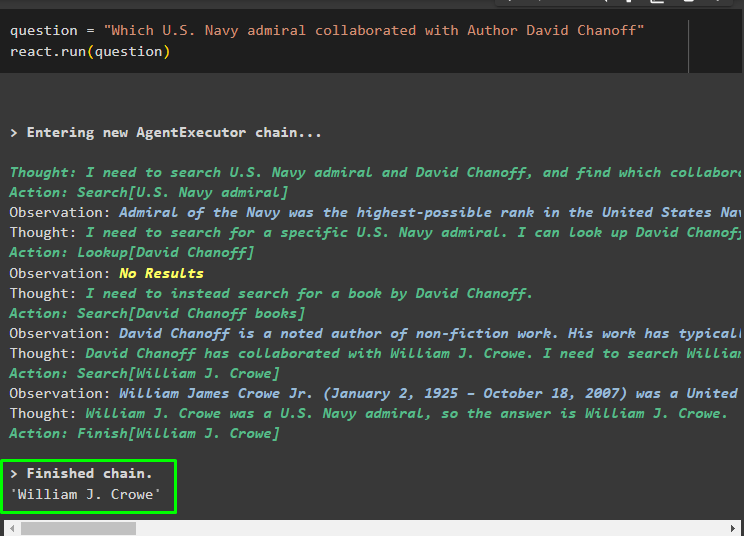
Frage = „Welcher Admiral der US-Marine hat mit dem Autor David Chanoff zusammengearbeitet?“reagieren. laufen ( Frage )
Sobald die Fragevariable ausgeführt wird, hat das Modell die Frage ohne externe Eingabeaufforderungsvorlage oder Schulung verstanden. Das Modell wird automatisch trainiert, indem das im vorherigen Schritt hochgeladene Modell verwendet und entsprechend Text generiert wird. Die ReAct-Logik arbeitet mit den Dokumentspeichern zusammen, um Informationen basierend auf der Frage zu extrahieren:
Stellen Sie eine weitere Frage anhand der Daten, die dem Modell aus den Dokumentenspeichern bereitgestellt werden, und das Modell extrahiert die Antwort aus dem Speicher:
Frage = „Der Autor David Chanoff hat mit William J. Crowe zusammengearbeitet, der unter welchem Präsidenten gedient hat?“reagieren. laufen ( Frage )
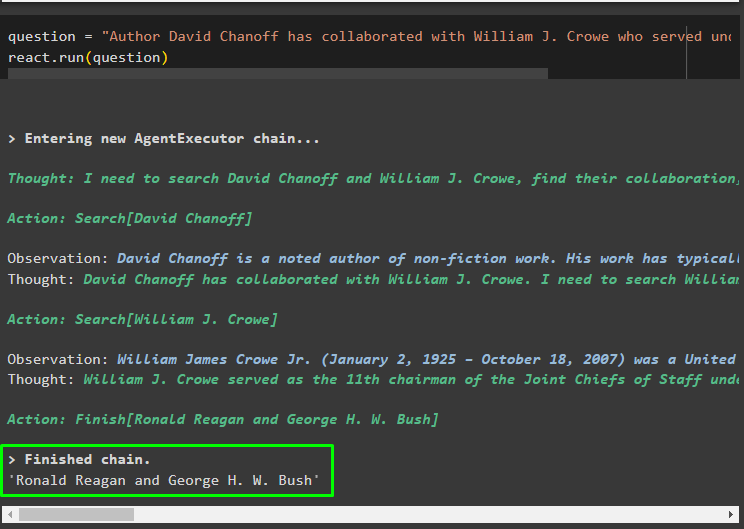
Dabei geht es darum, die ReAct-Logik für die Arbeit mit dem Dokumentenspeicher in LangChain zu implementieren.
Abschluss
Um die ReAct-Logik für die Arbeit mit dem Dokumentenspeicher in LangChain zu implementieren, installieren Sie die Module oder Frameworks zum Aufbau des Sprachmodells. Anschließend richten Sie die Umgebung für OpenAI ein, um das LLM zu konfigurieren und das Modell aus dem Dokumentenspeicher zu laden, um die ReAct-Logik zu implementieren. In diesem Leitfaden wurde die Implementierung der ReAct-Logik für die Arbeit mit dem Dokumentenspeicher erläutert.