Dieser Artikel bietet seinen Benutzern ein tieferes Verständnis für die Implementierung von Data Warehouse mit AWS Redshift.
Was ist AWS Redshift?
AWS Redshift ermöglicht seinen Benutzern das Abrufen und Bearbeiten der Daten ohne alle Konfigurationen einer herkömmlichen Datenbank. Es skaliert die Kapazität intelligent je nach den Anforderungen der Anwendung, liefert schnelle und genaue Antworten und wird vollständig von AWS verwaltet. AWS Redshift wird häufig für seine umfangreichen Anwendungen der Big-Data-Analyse verwendet. Darüber hinaus folgt es dem Pay-as-you-use-Modell und es fallen keine zusätzlichen Kosten an, wenn das Lager stillsteht:
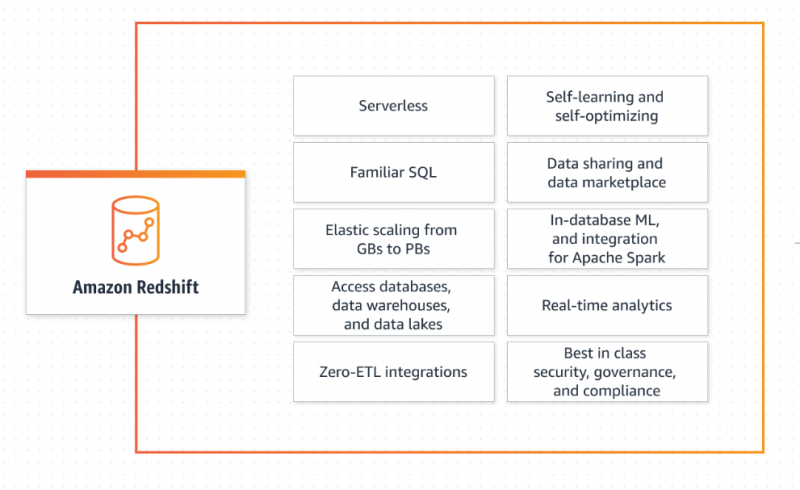
Erfahren Sie mehr über Redshift in diesem Artikel: „Was sind die Amazon-Redshift-Datentypen“ :
Wie implementiert man Data Warehousing mit Amazon Redshift?
Amazon Redshift verwendet die Standard Query Language (SQL) in verschiedenen Warehouses zum Ausführen von Abfragen. Das Extrahieren von Maximalwerten bei gleichzeitiger Überwachung der Kosten für die manuelle Einrichtung eines Data Warehouse ist mühsam. Daher beschleunigt AWS Redshift Ihre datenbezogenen Geschäftsaufgaben genau und intelligent und hilft Ihnen, Ihre Zeit zu verkürzen, um schnell, einfach, zuverlässig und sicher Einblicke in Daten zu gewinnen. Die Implementierung von Data Warehousing mit Amazon Redshift bietet viele Vorteile:
- Datenverschlüsselung
- Intelligente Optimierung
- Kostenoptimal
- Automatisieren Sie sich wiederholende Aufgaben
- Automatische Skalierungskapazität
- Unterstützung für verschiedene AWS-Ressourcen
Nachfolgend finden Sie einige Schritte, in denen wir das Data Warehousing mit Amazon Redshift implementieren können:
Schritt 1: Erstellen Sie eine IAM-Rolle
Der erste Schritt bei der Implementierung eines Data Warehouse AWS Redshift beginnt mit der Erstellung einer IAM-Rolle. Suchen Sie dazu die IAM-Rolle auf der Seite und wählen Sie sie aus AWS-Managementkonsole :
Klick auf das „Rollen“ Option aus der Seitenleiste der IAM-Rolle:
Klick auf das „Rolle erstellen“ Schaltfläche weiter:
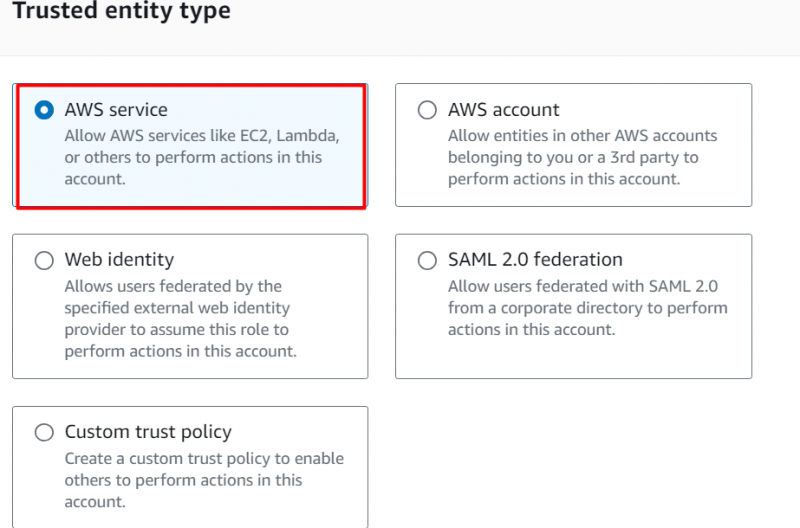
Im Vertrauenswürdiger Entitätstyp Klicken Sie im Abschnitt auf „AWS-Dienst“ während wir diese IAM-Rolle für Redshift erstellen:
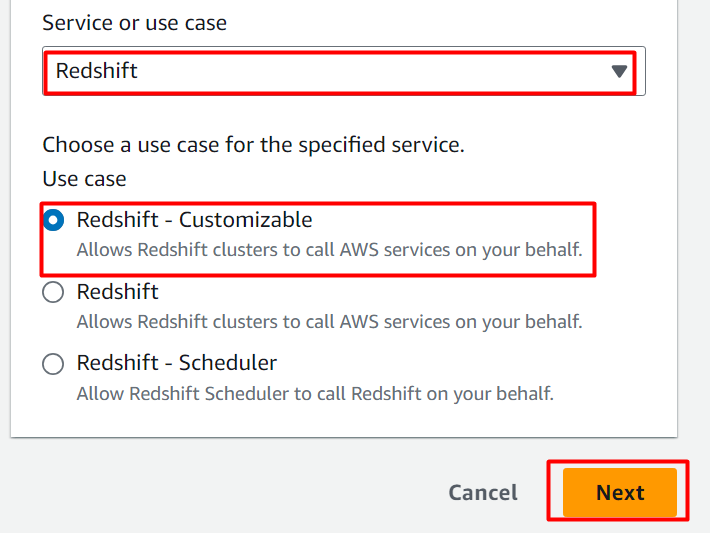
Im Anwendungsfall Abschnitt , wählen „Rotverschiebung“ Klicken Sie in das hervorgehobene Feld und fahren Sie mit der Auswahl der folgenden hervorgehobenen Option fort. Klick auf das 'Nächste' Schaltfläche danach:
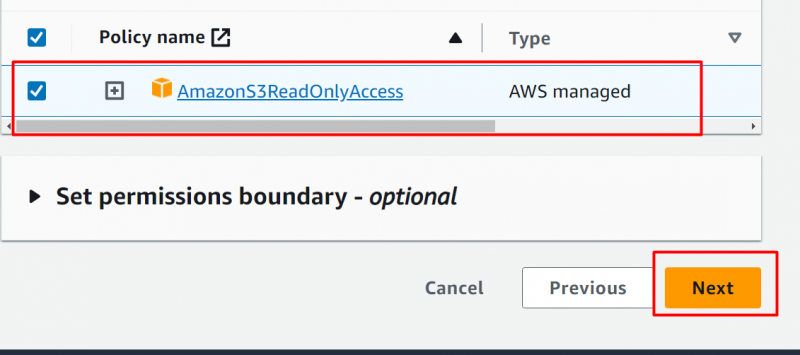
Im Berechtigungsrichtlinie Abschnitt , Suchen und wählen Sie die aus „AmazonS3ReadOnlyAccess“ Möglichkeit. Und dann klicken Sie auf 'Nächste' Schaltfläche danach:
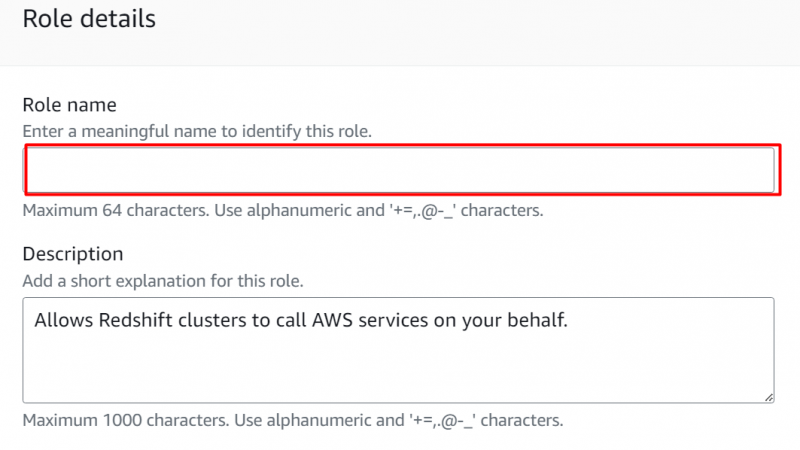
Im Rollendetails Abschnitt , Geben Sie den Namen für die Rolle an:
Den Rest behalte ich Einstellungen als Standard, Klick auf das „Rolle erstellen“ Schaltfläche am unteren Rand der Benutzeroberfläche:
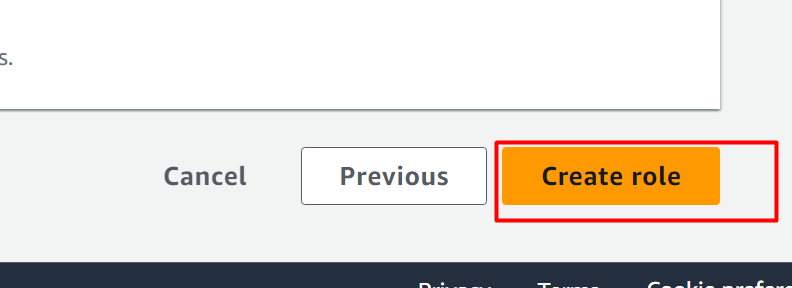
Die Rolle war erfolgreich erstellt. Klick auf das „Rolle ansehen“ Taste:
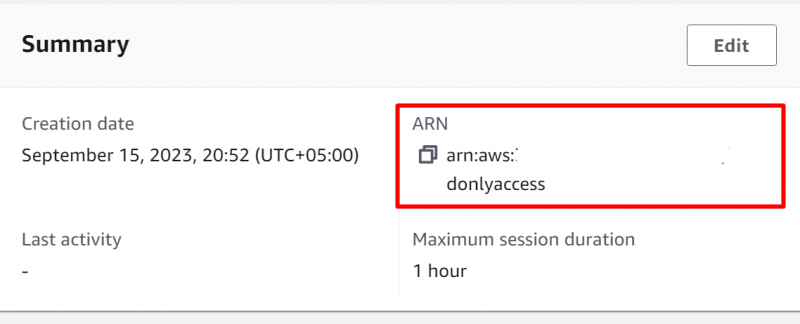
Im Rolle anzeigen Abschnitt, kopieren Sie die RNA und speichern Sie es zur späteren Verwendung im Editor:
Schritt 2: Redshift-Cluster erstellen
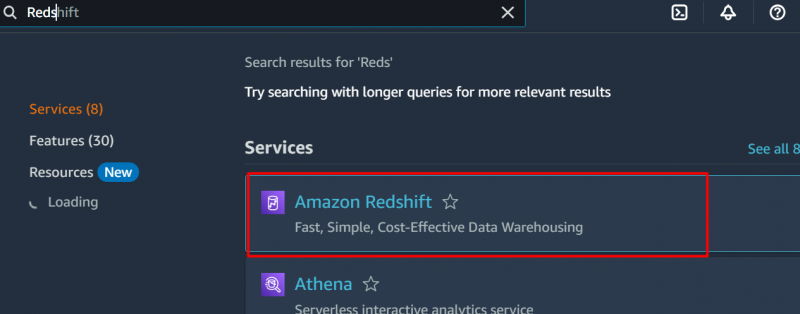
Suchen Sie in der AWS-Managementkonsole nach und wählen Sie dann aus „Rotverschiebung“ Service:
Scrollen Sie nach unten „Rotverschiebung“ Hauptkonsole und klicken Sie auf „Cluster erstellen“ Taste:
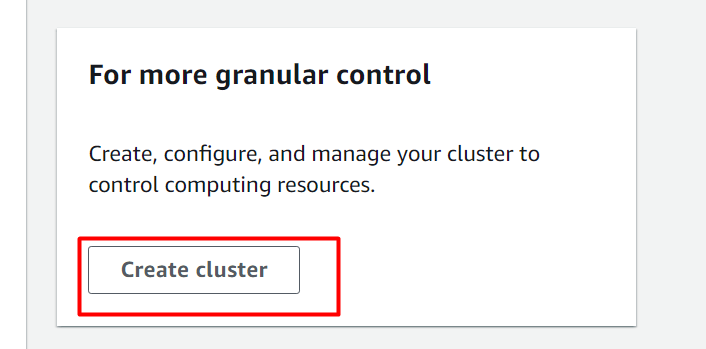
Dadurch wird der Benutzer zum weitergeleitet „Cluster erstellen“ Schnittstelle. Geben Sie hier auf dieser Schnittstelle einen Namen für den Cluster ein und wählen Sie den aus „dc.2 groß“ für den Clustertyp:
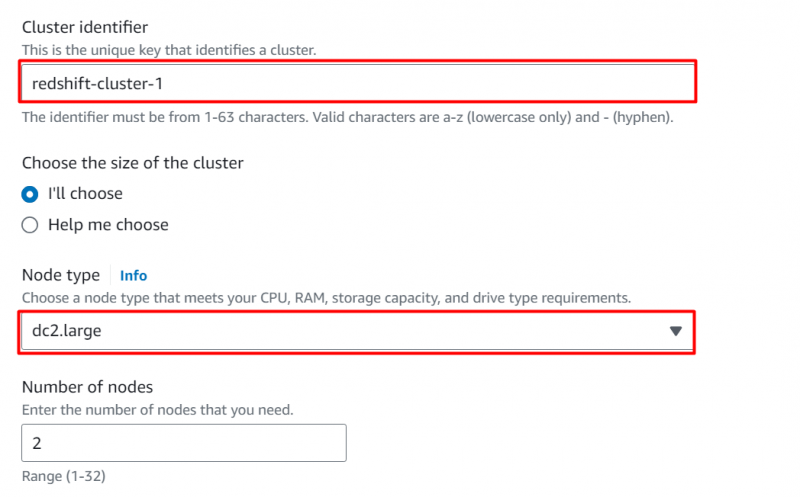
Im Datenbankkonfigurationen Abschnitte, bieten a Nutzername Und Passwort für den Cluster:
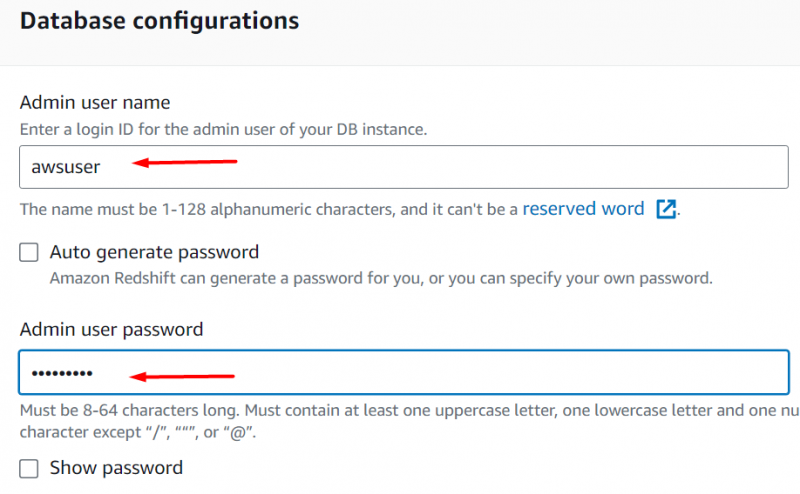
Scrollen Sie nach unten zum IAM-Rollen Abschnitt. Wir werden hier die IAM-Rolle anhängen, die wir zuvor in diesem Tutorial erstellt haben. Klicken Sie dazu auf „IAM-Rolle zuordnen“ Taste:
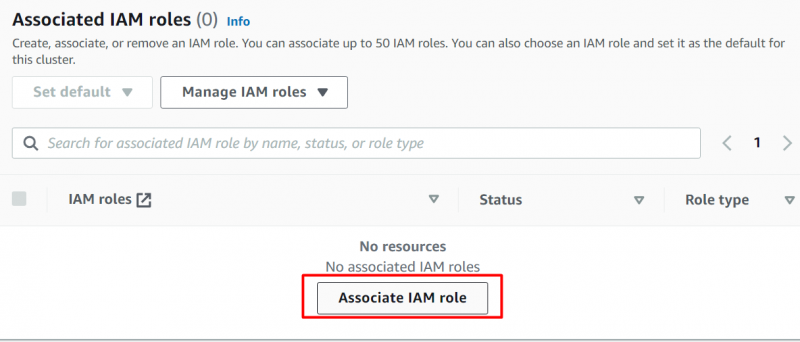
In diesem Abschnitt haben wir die erstellte Rolle ausgewählt und auf geklickt „IAM-Rollen zuordnen“ Schaltfläche zum Anhängen der Rolle:
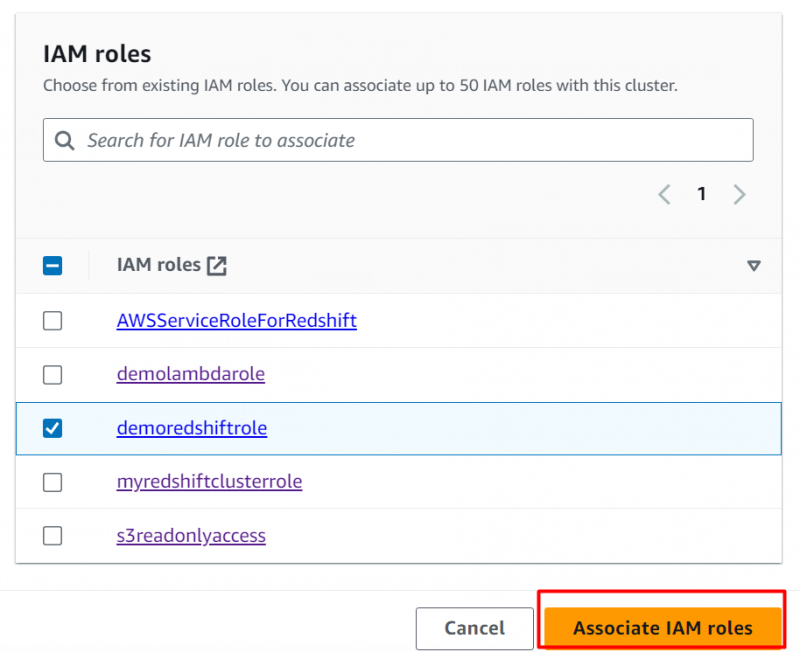
Behalten Sie die Standardeinstellungen bei und klicken Sie auf „Cluster erstellen“ Schaltfläche am unteren Rand der Benutzeroberfläche:
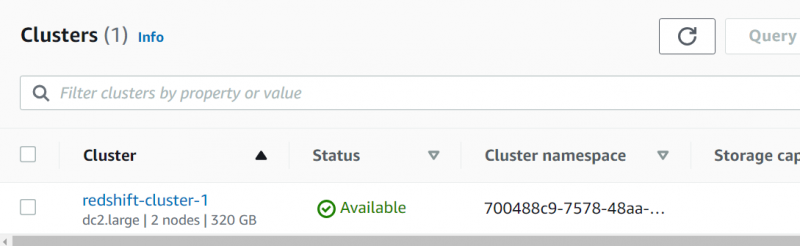
Es wird einige Zeit dauern, bis der Cluster verfügbar ist. Klick auf das Clustername aus dem RDS-Dashboard, nachdem der Status angezeigt wird 'Aktiv':
Schritt 3: Berechtigungen hinzufügen
Greife auf ... zu IAM-Dienst von der AWS-Managementkonsole zu Konfigurieren Sie eine neue Richtlinie im Root-Benutzerkonto:
Von dem IAM-Dashboard, Klick auf das „Benutzer“ Option aus der linken Seitenleiste:
Klick auf das Rollenname das hat das Administratorzugriff zum Konto:
Tippen Sie auf die „Berechtigungen hinzufügen“ Schaltfläche auf der Benutzeroberfläche:
Klick auf das „Richtlinien direkt anhängen“ Option unter der Berechtigungsoptionen Abschnitt:
Fügen Sie Ihrem Konto die folgenden Berechtigungen hinzu:
- AmazonRedshiftQueryEditor
- AmazonRedshiftQueryEditorV2FullAccess
- AmazonRedshiftReadOnlyAccess
Nachdem Sie die folgenden Berechtigungen hinzugefügt haben, klicken Sie auf 'Nächste' Taste:
Im Zusammenfassung der Berechtigungen Klicken Sie im Abschnitt auf „Berechtigungen hinzufügen“ Taste:
Hier sind die Berechtigungen erfolgreich konfiguriert:
Schritt 4: Abfrageeditor
Auf der AWS RDS-Dashboard , Klick auf das „Abfrageeditor v2“ Option aus der Seitenleiste:
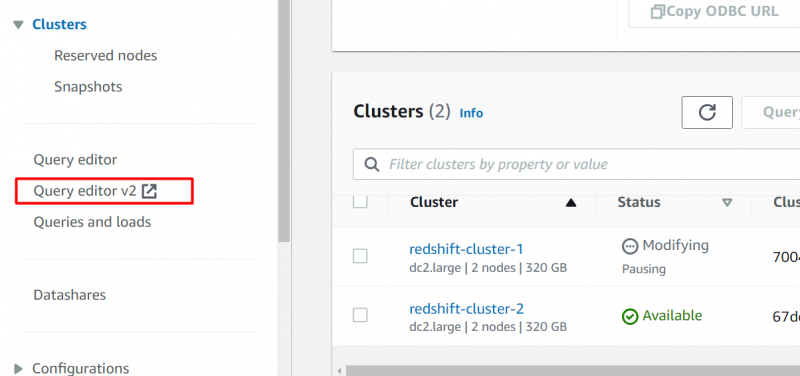
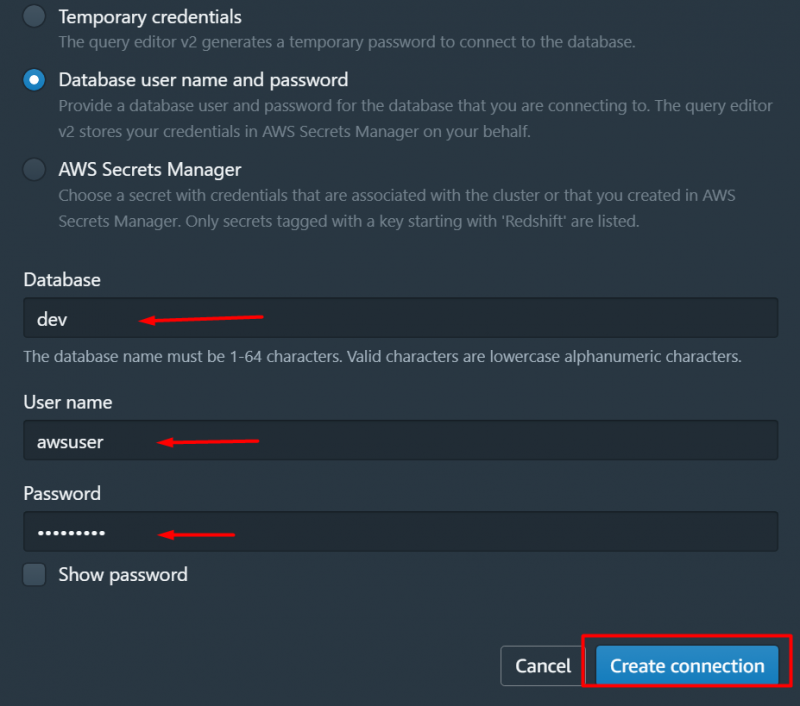
Dadurch wird die folgende Oberfläche angezeigt. Wählen Sie auf dieser Schnittstelle den Namen Ihres Clusters aus und geben Sie die folgenden Details für die Verbindung an. Nachdem Sie die Details angegeben haben, klicken Sie auf „Verbindung herstellen“ Taste:
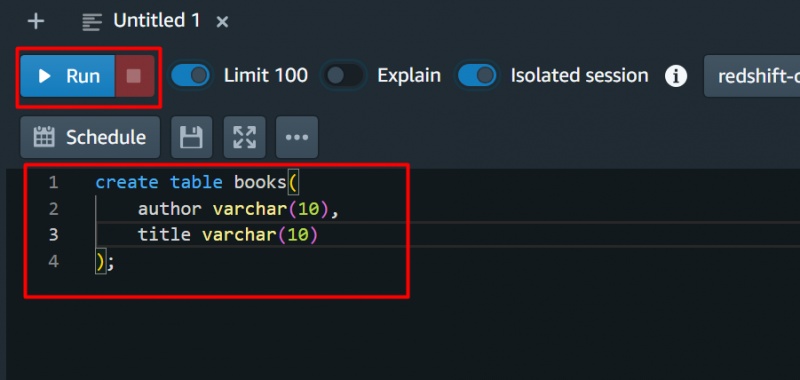
Zu Testzwecken stellen wir die folgende Abfrage bereit und klicken auf 'Laufen' Taste:
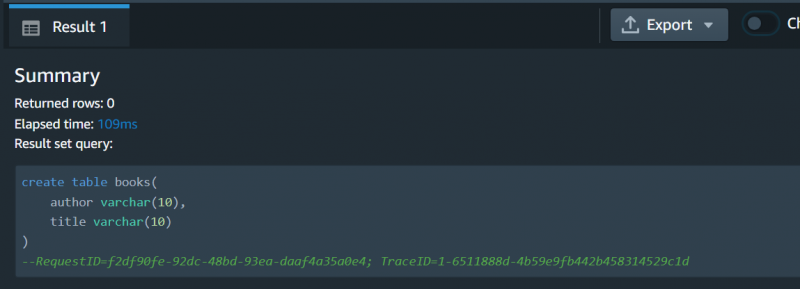
Die Abfrage wurde ausgeführt erfolgreich:
Das ist alles aus diesem Leitfaden. Jetzt kann der Benutzer in dieser Konsole verschiedene Abfragen ausführen, z. B. Erstellen, Einfügen, Löschen, usw.
Abschluss
Um Data Warehousing mit Redshift zu erstellen, konfigurieren Sie eine IAM-Rolle und -Berechtigung mit dem RDS-Cluster und klicken Sie auf „ Abfrageeditor ” Option zum Ausführen von Abfragen. AWS Redshift ist eine cloudbasierte Datenbank, die der Syntax von SQL folgt und Abfragen für große Datensätze effizient und für eine hohe Leistung ausführt. Dieser Artikel enthält Anweisungen zur Implementierung von Data Warehousing mit Amazon Redshift.