Amazon Redshift ist eine von AWS angebotene Cloud-Lösung, die den Zweck eines Data Warehouse erfüllt. Ein Data Warehouse ist ein großer Raum in der Cloud, der enorme Datenmengen speichert. Der Unterschied zwischen einem Data Warehouse und einer Datenbank besteht darin, dass erstere nicht nur aktuelle Daten, sondern auch den vollständigen Verlauf der Daten speichert.
In diesem Artikel erfahren Sie mehr über Amazon Redshift von AWS und die Datentypen, die dieser Dienst unterstützt.
Was ist Amazon RedShift?
Es handelt sich um eine Cloud-Lösung für Data Warehousing, die darauf basiert „PostgreSQL“ . Es verwendet eine Technologie namens „Massiv parallele Verarbeitung (MPP)“ um Petabytes an Daten blitzschnell zu verarbeiten. Dies bietet eine einfache Lösung für Echtzeitvorhersagen auf der Grundlage historischer Daten und Streaming-Lösungen.
Die folgende Abbildung zeigt den Arbeitsmechanismus von Amazon Redshift:
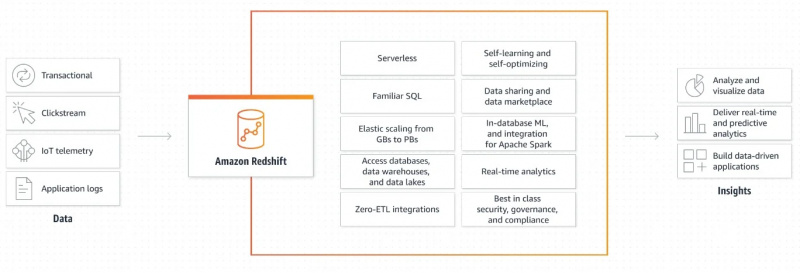
Diese grafische Erklärung der Funktionsweise von Amazon Redshift ist sehr einfach und klar. Es gibt uns Informationen darüber, wie Daten abgerufen und weiterverarbeitet werden, um Ausgaben zu generieren und datengesteuerte Anwendungen zu erstellen.
Die Data Warehouse-Architektur von Amazon Redshift ist auch in der folgenden Abbildung zu sehen:
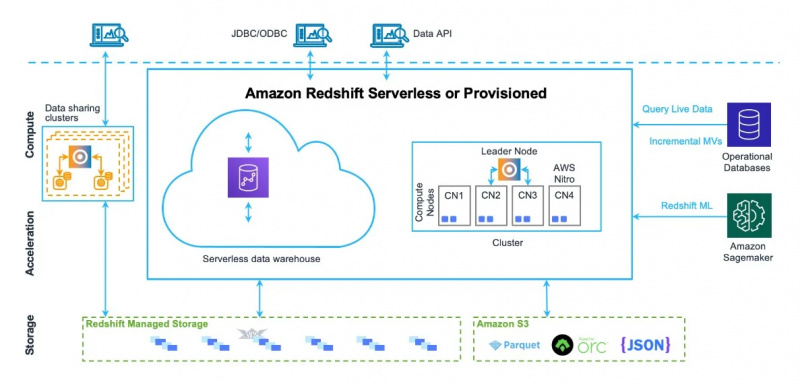
Nun wenden wir uns den Verwendungsmöglichkeiten und Funktionen dieses Dienstes zu.
Merkmale
Wie bereits erwähnt basiert Amazon Redshift auf PostgreSQL und nutzt eine Technologie namens Massively Parallel Processing, die es ermöglicht, Petabytes an Daten in kürzester Zeit zu verarbeiten. Daher bietet Redshift eine ganze Reihe von Funktionen und Einsatzmöglichkeiten. Einige dieser Funktionen sind unten aufgeführt:
- Datensicherheit und Verschlüsselung.
- Geschäftsanalysen.
- Datengesteuerter Anwendungssupport.
- Prädiktive Analyse.
- Automatisierte Aufgabenwiederholung.
- Gleichzeitige Datenskalierung.
- Datenspeicherung.
Einige zusätzliche Funktionen dieses Dienstes sind in der folgenden Abbildung zu sehen:
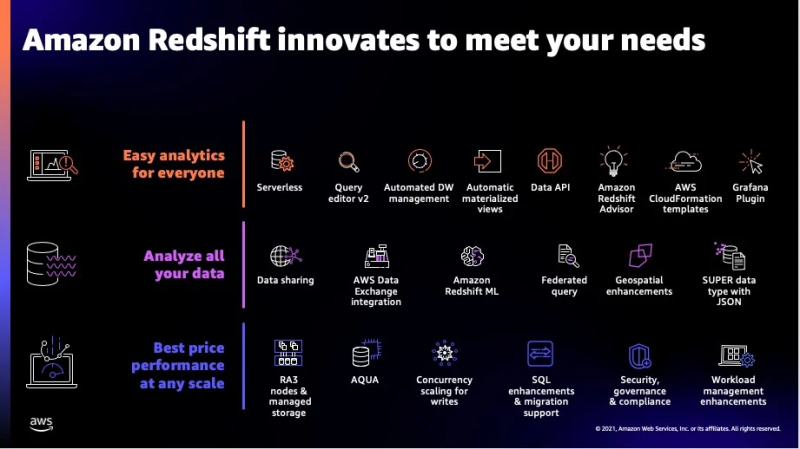
Dies waren die meisten Funktionen, die Redshift bietet, und jetzt werden wir uns den von diesem Dienst unterstützten Datentypen zuwenden.
Datentypen
Amazon Redshift ist eine Data-Warehousing-Lösung mit zahlreichen Funktionen. Es unterstützt sowohl strukturierte als auch unstrukturierte Datentypen. Da es auf PostgreSQL basiert, können die Daten durch einfache SQL-Abfragen manipuliert werden.
Nun stellt sich eine weitere Frage: Wie unterscheiden sich diese Datenformate voneinander? Lassen Sie uns diese beiden Datenformate diskutieren.
Strukturierte Daten
Ein hochformatierter Datentyp, der durch maschinelle Lernalgorithmen leicht übersetzt werden kann, wird als strukturierte Daten bezeichnet. Eine SQL-Datenbank arbeitet mit strukturierten Daten. Strukturierte Daten liegen in tabellarischer Form vor, beispielsweise Daten, die von relationalen Datenbanken verwendet werden
Eines der am weitesten verbreiteten SQL-Datenbankverwaltungssysteme ist MYSQL. Seine Architektur ist in der folgenden Abbildung zu sehen:
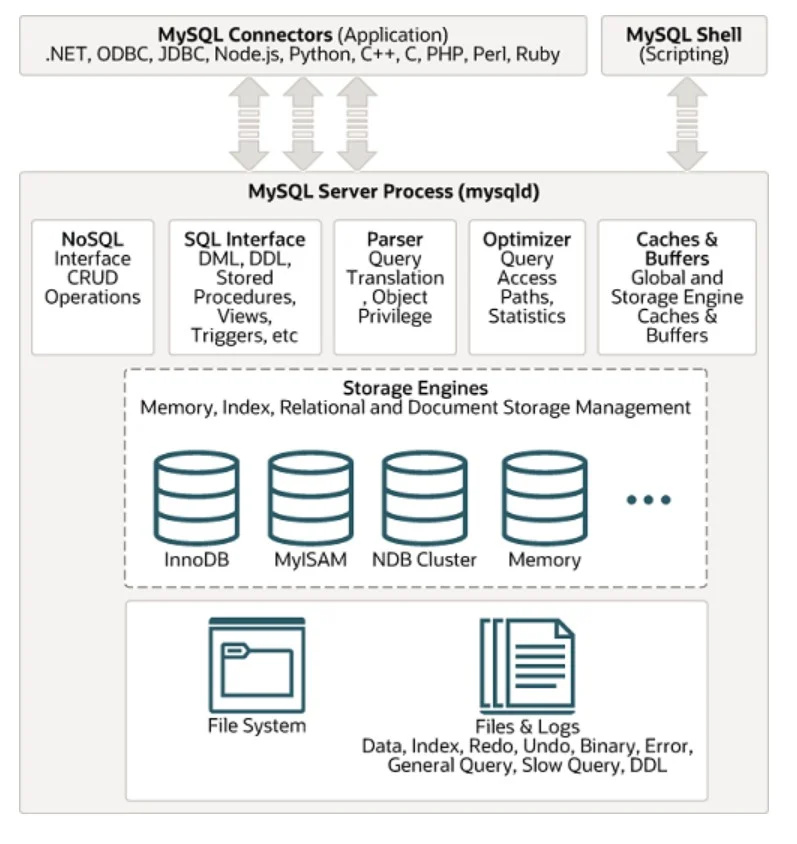
Unstrukturierte Daten
Unstrukturierte Daten sind muster- und formatlose Daten, beispielsweise Daten, die in nicht relationalen Datenbanken verwendet werden. MongoDB ist eine berühmte nicht-relationale Datenbank. SQL-Abfragen funktionieren nicht bei nicht relationalen Datenbanken, daher werden diese Datenbanken auch NoSQL-Datenbanken genannt.
Wie bereits erwähnt, ist MongoDB ein nicht strukturiertes Datenbankverwaltungssystem und seine Architektur ist in der folgenden Abbildung zu sehen:
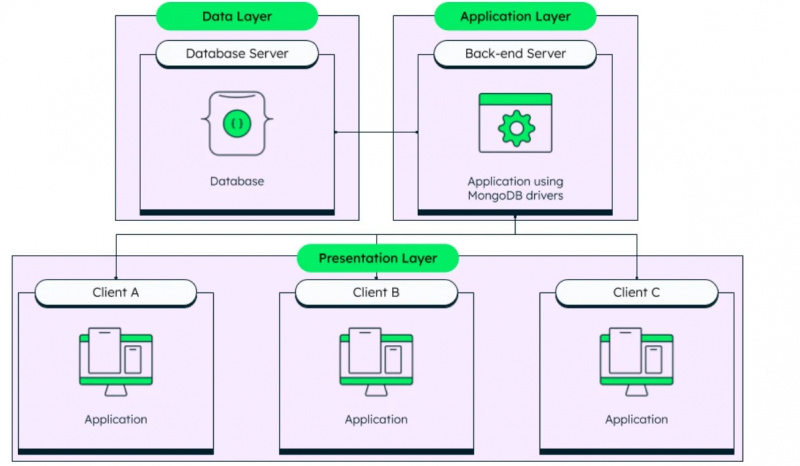
Wir haben die beiden grundlegenden Datentypen durchgegangen, die in Datenbanken verwendet werden, und wenden uns nun den tatsächlichen Datentypen zu, die von Amazon Redshift unterstützt werden. Diese Datentypen sind:
- Numerische Daten
- Charakterdaten
- Datetime-Daten
- Boolesche Daten
- HLLSKETCH-Daten
- SUPER-Daten
- ERSATZ-Daten
Lassen Sie uns diese Datentypen besprechen:
Numerische Daten
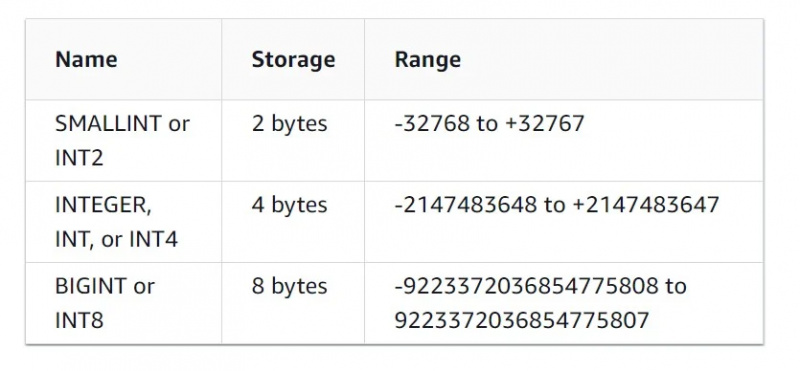
Dieser Datentyp ist selbsterklärend. Es unterstützt Daten in Form von Ganzzahlen, Dezimalzahlen, Gleitkommazahlen und anderen numerischen Datentypen.
Die Merkmale des Integer-Datentyps sind in der folgenden Abbildung dargestellt:
Der Datentyp „Dezimal“ speichert die Daten basierend auf der Genauigkeit des Benutzers. Seine Eigenschaften sind wie folgt:

Charakterdaten
Die Datentypen CHAR und VARCHAR fallen in die Kategorie der zeichenbasierten Datentypen. NCHAR und NVARCHAR sind ebenfalls Datentypen vom Typ Zeichen. Im Gegensatz zu CHAR und VARCHAR speichern diese beiden Datentypen Unicode-Zeichen fester Länge. Schauen wir uns die Eigenschaften dieser Datentypen an, wie zum Beispiel:
- CHAR, CHARACTER, NCHAR haben einen Bereich von 4 KB.
- VARCHAR, NVARCHAR hat einen Bereich von 64 KB.
- BPCHAR hat einen Bereich von 256 Bytes.
- TEXT hat einen Bereich von 260 Bytes.
Datetime-Daten
Datetime-Datentypen sind DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ. Die funktionalen Fähigkeiten dieser Datentypen sind wie folgt:
- DATE speichert einfach Kalenderdaten.
- TIME speichert die Zeit ohne Bezug zu einer Zeitzone. Standardmäßig ist UTC.
- TIMETZ speichert die Zeit in Bezug auf die Zeitzone. Sowohl in den Benutzertabellen als auch in den Systemtabellen ist standardmäßig UTC angegeben.
- TIMESTAMP umfasst nicht nur die Uhrzeit, sondern auch das Datum. Sowohl in den Benutzertabellen als auch in den Systemtabellen ist es standardmäßig UTC.
- TIMESTAMPTZ umfasst nicht nur die Uhrzeit, sondern auch das Datum. Standardmäßig ist UTC nur in Benutzertabellen angegeben.
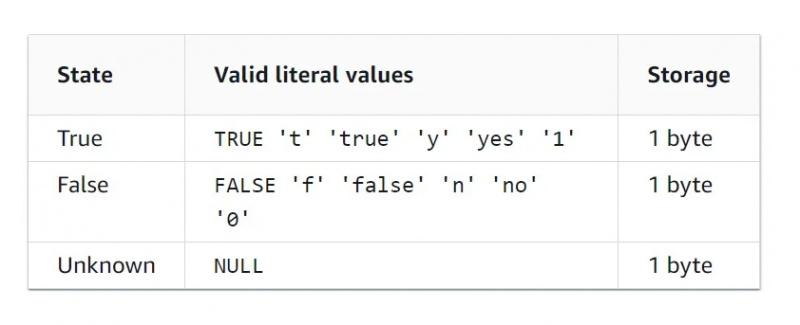
Boolesche Daten
Der boolesche Datentyp ist ein binärer Datentyp, was bedeutet, dass es nur zwei Werte gibt. Die Merkmalstabelle für den booleschen Datentyp ist unten in der Abbildung dargestellt:
HLLSKETCH-Daten
Dieser Datentyp wird zum Speichern von Skizzen verwendet. Redshift kann die Skizzen entweder in spärlicher oder dichter Form darstellen. Skizzen beginnen spärlich und werden allmählich dichter, wenn ein dichtes Format mehr Effizienz bietet, wenn Sie dem Link folgen.
SUPER-Daten
Dieser Datentyp befasst sich mit unstrukturierten Daten, die in Form von Arrays, verschachtelten Strukturen oder JSON vorliegen können. Es gibt kein Modell oder Format der Daten. Benutzer können weitere Informationen erkunden, indem sie auf den Link klicken.
ERSATZ-Daten
Dieser Datentyp speichert auch Zeichen. Allerdings ist die Länge begrenzt. Amazon Redshift ermöglicht die Umwandlung von VARBYTE-Daten in beliebige Ganzzahl- oder Zeichentypdaten. Um weitere Informationen zu diesem Datentyp zu erhalten, folgen Sie dem folgenden Link.
Das ist alles, was Amazon Redshift und die von ihm unterstützten Datentypen zu bieten haben.
Abschluss
Amazon Redshift ist ein AWS-Dienst, der in seiner Grundform den Zweck eines Data Warehouse erfüllt, aber eine sehr leistungsstarke und funktionsreiche Lösung für Analysen und Vorhersagen darstellt. In diesem Artikel wurden Redshift und die von ihm unterstützten Datentypen besprochen. Diese Datentypen wurden zusammen mit ihren Eigenschaften kurz erläutert.