Kiel (Knowledge Extraction based on Evolutionary Learning) ist ein Java-basiertes Softwaretool, das sich auf die Implementierung evolutionärer Algorithmen spezialisiert hat. Da es sich um eine Open Source handelt, bietet es eine Vielzahl von Wissensentdeckungsalgorithmen, die in Experimenten verwendet werden können, die die Data-Mining- und Analyse-Community antreiben. Es bietet eine einfache und benutzerfreundliche grafische Benutzeroberfläche, die die Gesamtkomplexität dieses Tools erheblich verringert. Bei den meisten ähnlichen Tools auf dem Markt müssen die Benutzer mit ihnen interagieren, indem sie den Code schreiben, während Keel diese Anforderung beseitigt, indem es eine intuitive GUI bereitstellt, die von Anfängern und Experten gleichermaßen verwendet werden kann.
Keel bietet eine große Auswahl an verschiedenen auf Computerintelligenz basierenden Algorithmen, darunter Klassifizierung, Regression, Merkmalsextraktion, Musteranalyse, Clustering und mehr. Mit Mainstream-Modellen, die direkt in die Anwendung selbst integriert sind, ist Keel ein sehr nützliches Werkzeug, wenn es darum geht, explorative Datenanalysen an Rohdatensätzen durchzuführen. Die einfache Drag-and-Drop-Oberfläche gepaart mit der einfachen Nutzung der Funktionen ermöglicht schnelle und effiziente Data-Mining-Experimente sowohl für Bildungs- als auch für Forschungszwecke. Tools wie Keel erfreuen sich aufgrund ihres vereinfachten Ansatzes für ansonsten komplexe algorithmische Praktiken zunehmender Beliebtheit.
Installation
Es gibt zwei Möglichkeiten, wie wir installieren können Kiel auf jedem Linux-Rechner. Der erste beinhaltet den Gang zum Keel-Webseite und die Software von dort herunterzuladen. Der zweite, dem wir in dieser Installationsanleitung folgen werden, erfordert, dass wir Keel mit herunterladen wget Download-Tool für Linux-Benutzer verfügbar.
1. Wir beginnen mit dem Erhalten wget auf unserer Linux-Maschine.
Führen Sie den folgenden Befehl aus, um das wget mit dem herunterzuladen geeignet Paket-Manager:
$ sudo apt-get installieren wget
Sie sehen eine ähnliche Terminalausgabe:
2. Jetzt, wo wir die haben wget Tool, das auf unserem Linux-Rechner installiert ist, verwenden wir es, um das herunterzuladen Kiel Werkzeug.
Dies ist das Verknüpfung dass wir an wget übergeben.
Führen Sie den folgenden Befehl in Ihrem Terminal aus:
$ wget http: // sci2s.ugr.es / Kiel / Software / Prototypen / openVersion / Software- 2018 -04-09.zip
Sie sollten eine ähnliche Ausgabe auf Ihrem Terminal sehen:
Sobald Keel mit dem Herunterladen fertig ist, können wir mit dem Rest der Installation fortfahren.
3. Wir extrahieren nun die komprimierte Datei, die wir im vorherigen Schritt heruntergeladen haben, mit dem Linux Unzip-Tool.
Führen Sie den folgenden Befehl aus:
$ entpacken Software- 2018 -04-09.zip
Sie sollten eine ähnliche Ausgabe im Terminal sehen:
4. Navigieren Sie in den Keel-Ordner, indem Sie den folgenden Befehl ausführen:
$ CD Software- 2018 -04-09 / Unterlagen / Experimente / KIEL / Abstand /
5. Führen Sie den folgenden Befehl aus, um mit der Installation zu beginnen:
$ Java -Krug . / GraphInterKeel.jar
Damit sollte Keel für Sie zur Verwendung auf Ihrem Linux-Rechner verfügbar sein.
Benutzerhandbuch
Interaktion mit dem Kiel Die Anwendung ist wirklich einfach und unkompliziert. Beginnen wir mit dem Importieren der Iris-Datensatz in unseren Arbeitsbereich.
Während wir die Daten importieren, zeigt uns das Tool die Gesamtclusterung des Datenpunkts im Datensatz. Es zeigt uns auch die verschiedenen Klassen, die im Datensatz vorhanden sind, zusammen mit den grundlegenden Informationen wie den numerischen Bereichen, die diese Datenpunkte umfassen, und der Gesamtvarianz und den darin enthaltenen Mittelwerten. Diese Informationen ermöglichen es den Benutzern, besser zu verstehen, wie sie mit der Datenvorbereitung für jede Art von Datenanalyseaufgabe fortfahren.
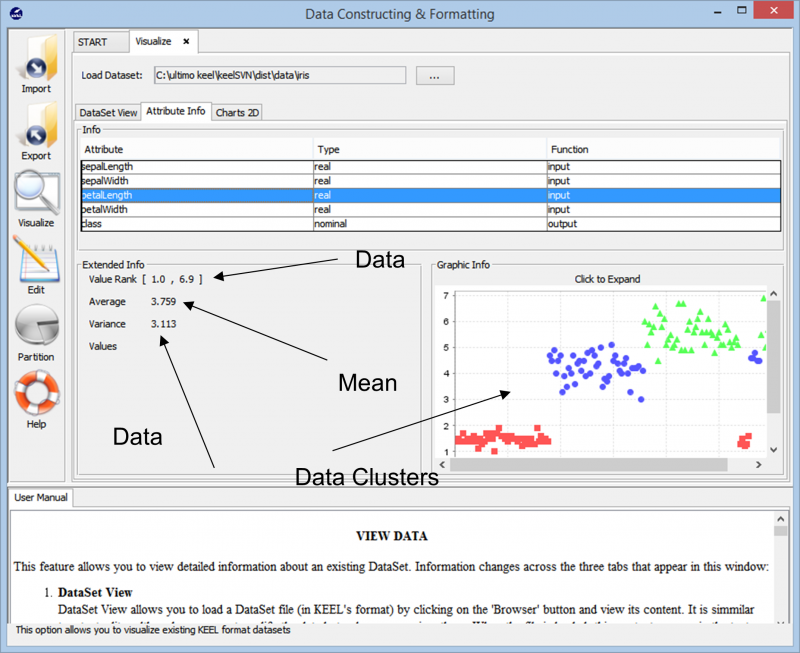
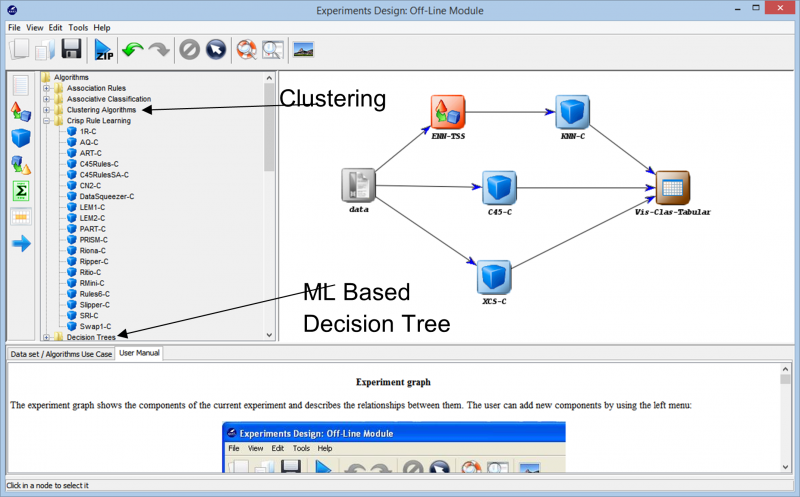
Wenn wir weiter in das Experiment gehen, stoßen wir auf die verschiedenen Techniken, die verwendet werden können, um unser Experiment mit jedem Datensatz zu erstellen. Die verschiedenen Lernalgorithmen, die auf unsere Daten angewendet werden können, sind im folgenden Bild zu sehen. Je nach Art des Datensatzes und den Anforderungen des Experiments kann mit verschiedenen Algorithmen experimentiert werden.
Wenn Sie beispielsweise mit unbeschrifteten Daten arbeiten und Ähnlichkeiten zwischen den verschiedenen Datenpunkten in Ihrem Datensatz finden müssen, kann Ihnen die Verwendung eines Clustering-Algorithmus aus den verschiedenen verfügbaren Optionen dabei helfen, die Datenpunkte besser zu verstehen. Dies hilft Ihnen schließlich dabei, die Datenpunkte zu kennzeichnen und zu klassifizieren, sodass das Experiment mit umfassenderen überwachten Lernalgorithmen aufgebaut werden kann.
Fazit
Das Kiel Plattform für Datenanalyse ist eine gute Ressource sowohl für Forschungs- als auch für Bildungszwecke. Die benutzerfreundliche grafische Benutzeroberfläche hilft den Benutzern, die Anforderungen der Daten besser zu verstehen, und bietet logische Verweise auf hilfreiche Techniken und Algorithmen, die die Benutzer bei ihren Arbeitsabläufen weiter unterstützen. Eine breite Palette verschiedener Algorithmen, die unter die verschiedenen Kategorien und algorithmischen Techniken fallen, ermöglicht es den Benutzern, mit zahlreichen logischen Richtungen zu experimentieren und diese Ergebnisse zu vergleichen, so dass die optimalste Lösung für jedes Problem erreicht werden kann.
Keels codefreier Drag-and-Drop-Ansatz für Data Mining hilft selbst Anfängern, mühelos mit umfassenden Computational Intelligence-Modellen zu arbeiten. Dies bietet Einblicke in komplexe Datensätze und leitet daraus nützliche Schlussfolgerungen ab, die zur Lösung der Probleme der realen Welt beitragen.