Multiprocessing ist vergleichbar mit Multithreading. Es unterscheidet sich jedoch dadurch, dass wir aufgrund der für das Threading verwendeten GIL nur einen Thread gleichzeitig ausführen können. Multiprocessing ist der Prozess, bei dem Vorgänge nacheinander über mehrere CPU-Kerne ausgeführt werden. Threads können nicht parallel betrieben werden. Multiprocessing ermöglicht es uns jedoch, die Prozesse einzurichten und sie gleichzeitig auf verschiedenen CPU-Kernen auszuführen. Die Schleife, wie die for-Schleife, ist eine der am häufigsten verwendeten Skriptsprachen. Wiederholen Sie die gleiche Arbeit mit verschiedenen Daten, bis ein Kriterium, wie z. B. eine vorbestimmte Anzahl von Iterationen, erreicht ist. Die Schleife führt jede Iteration einzeln durch.
Beispiel 1: Nutzung der For-Schleife im Python-Multiprocessing-Modul
In diesem Beispiel verwenden wir die for-Schleife und den Klassenprozess des Python-Multiprocessing-Moduls. Wir beginnen mit einem sehr einfachen Beispiel, damit Sie schnell verstehen, wie die Python-Multiprocessing-for-Schleife funktioniert. Unter Verwendung einer dem Threading-Modul vergleichbaren Schnittstelle verpackt das Multiprocessing die Erstellung von Prozessen.
Durch die Verwendung von Unterprozessen anstelle von Threads bietet das Multiprocessing-Paket sowohl lokale als auch entfernte Parallelität und vermeidet so die globale Interpretersperre. Verwenden Sie eine for-Schleife, die ein Zeichenfolgenobjekt oder ein Tupel sein kann, um eine Sequenz kontinuierlich zu durchlaufen. Dies funktioniert weniger wie das Schlüsselwort in anderen Programmiersprachen und eher wie eine Iteratormethode in anderen Programmiersprachen. Indem Sie eine neue Mehrfachverarbeitung starten, können Sie eine for-Schleife ausführen, die eine Prozedur gleichzeitig ausführt.
Beginnen wir damit, den Code für die Codeausführung zu implementieren, indem wir das Tool „Spyder“ verwenden. Wir glauben, dass „Spyder“ auch das Beste zum Ausführen von Python ist. Wir importieren einen Multiprocessing-Modulprozess, in dem der Code ausgeführt wird. Das Multiprocessing in Python-Konzept, das als „Prozessklasse“ bezeichnet wird, erstellt einen neuen Python-Prozess, gibt ihm eine Methode zum Ausführen von Code und gibt der übergeordneten Anwendung eine Möglichkeit, die Ausführung zu verwalten. Die Klasse Process enthält die Prozeduren start() und join(), die beide entscheidend sind.
Als nächstes definieren wir eine benutzerdefinierte Funktion namens „func“. Da es sich um eine benutzerdefinierte Funktion handelt, geben wir ihr einen Namen unserer Wahl. Innerhalb des Hauptteils dieser Funktion übergeben wir die „subject“-Variable als Argument und den „maths“-Wert. Als nächstes rufen wir die Funktion „print()“ auf und übergeben die Anweisung „Der Name des gemeinsamen Subjekts ist“ sowie das Argument „subject“, das den Wert enthält. Dann verwenden wir im folgenden Schritt das „if name== _main_“, das verhindert, dass Sie den Code ausführen, wenn die Datei als Modul importiert wird, und dies nur zulässt, wenn der Inhalt als Skript ausgeführt wird.
Der Bedingungsabschnitt, mit dem Sie beginnen, kann in den meisten Fällen als ein Ort angesehen werden, an dem der Inhalt bereitgestellt wird, der nur ausgeführt werden sollte, wenn Ihre Datei als Skript ausgeführt wird. Dann verwenden wir das Argument Betreff und speichern einige Werte darin, nämlich „Wissenschaft“, „Englisch“ und „Computer“. Im folgenden Schritt erhält der Prozess dann den Namen „process1[]“. Dann verwenden wir „process(target=func)“, um die Funktion im Prozess aufzurufen. Target wird verwendet, um die Funktion aufzurufen, und wir speichern diesen Vorgang in der „P“-Variablen.
Als nächstes verwenden wir „process1“, um die Funktion „append()“ aufzurufen, die ein Element am Ende der Liste hinzufügt, die wir in der Funktion „func“ haben. Da der Prozess in der Variablen „P“ gespeichert ist, übergeben wir „P“ als Argument an diese Funktion. Schließlich verwenden wir die Funktion „start()“ mit „P“, um den Prozess zu starten. Danach führen wir die Methode erneut aus, während wir das „subject“-Argument bereitstellen und „for“ im Betreff verwenden. Dann beginnen wir den Prozess, indem wir erneut „process1“ und die Methode „add()“ verwenden. Der Prozess wird dann ausgeführt und die Ausgabe wird zurückgegeben. Die Prozedur wird dann mit der „join()“-Technik zum Ende gebracht. Die Prozesse, die die „join()“-Prozedur nicht aufrufen, werden nicht beendet. Ein entscheidender Punkt ist, dass der Schlüsselwortparameter „args“ verwendet werden muss, wenn Sie während des Prozesses Argumente bereitstellen möchten.
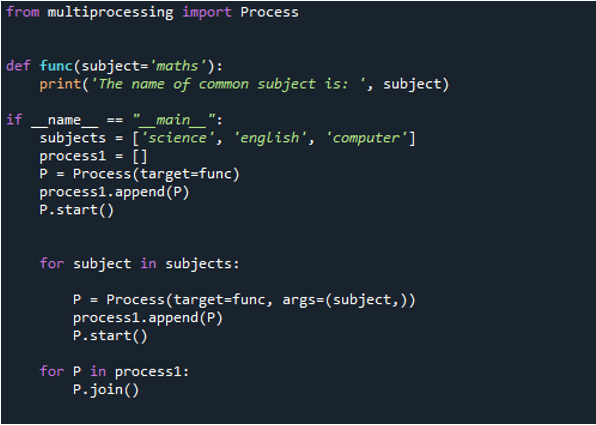
Jetzt können Sie in der Ausgabe sehen, dass die Anweisung zuerst angezeigt wird, indem Sie den Wert für das Thema „maths“ übergeben, den wir an die Funktion „func“ übergeben, weil wir ihn zuerst mit der Funktion „process“ aufrufen. Dann verwenden wir den Befehl „append()“, um Werte zu haben, die bereits in der Liste waren, die am Ende hinzugefügt wird. Dann wurden „Wissenschaft“, „Computer“ und „Englisch“ vorgestellt. Aber wie Sie sehen können, sind die Werte nicht in der richtigen Reihenfolge. Dies liegt daran, dass sie dies tun, sobald der Vorgang abgeschlossen ist, und ihre Nachricht melden.
Beispiel 2: Umwandlung einer sequentiellen For-Schleife in eine parallele Multiprocessing-For-Schleife
In diesem Beispiel wird die Multiprocessing-Schleife sequenziell ausgeführt, bevor sie in eine parallele for-Schleife umgewandelt wird. Mit den for-Schleifen können Sie Sequenzen wie eine Sammlung oder einen String in der Reihenfolge durchlaufen, in der sie auftreten.
Beginnen wir nun mit der Implementierung des Codes. Zuerst importieren wir „Schlaf“ aus dem Zeitmodul. Mit der „sleep()“-Prozedur im time-Modul können Sie die Ausführung des aufrufenden Threads beliebig lange unterbrechen. Dann verwenden wir „random“ aus dem random-Modul, definieren eine Funktion mit dem Namen „func“ und übergeben das Schlüsselwort „argu“. Dann erstellen wir mit „val“ einen Zufallswert und setzen ihn auf „random“. Dann blockieren wir für eine kurze Zeit mit der Methode „sleep()“ und übergeben „val“ als Parameter. Um eine Nachricht zu übertragen, führen wir dann die Methode „print()“ aus, übergeben die Wörter „ready“ und das Schlüsselwort „arg“ als Parameter sowie „created“ und übergeben den Wert mit „val“.
Schließlich verwenden wir „flush“ und setzen es auf „True“. Der Benutzer kann entscheiden, ob die Ausgabe gepuffert werden soll oder nicht, indem er die Option flush in der Druckfunktion von Python verwendet. Der Standardwert dieses Parameters von False gibt an, dass die Ausgabe nicht gepuffert wird. Wenn Sie es auf true setzen, wird die Ausgabe als eine Reihe aufeinander folgender Zeilen angezeigt. Dann verwenden wir „if name== main“, um die Einstiegspunkte zu sichern. Als nächstes führen wir den Job sequentiell aus. Hier setzen wir den Bereich auf „10“, was bedeutet, dass die Schleife nach 10 Iterationen endet. Als nächstes rufen wir die Funktion „print()“ auf, übergeben ihr die Eingabeanweisung „ready“ und verwenden die Option „flush=True“.
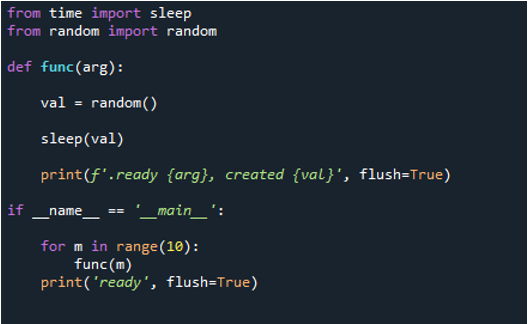
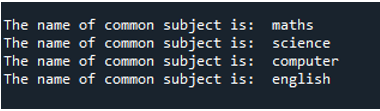
Sie können jetzt sehen, dass, wenn wir den Code ausführen, die Schleife bewirkt, dass die Funktion „10“ Mal ausgeführt wird. Es wird 10 Mal durchlaufen, beginnend bei Index null und endend bei Index neun. Jede Nachricht enthält eine Aufgabennummer, die eine Funktionsnummer ist, die wir als „arg“ übergeben, und eine Erstellungsnummer.
Diese sequentielle Schleife wird nun in eine parallele For-Schleife mit mehreren Verarbeitungsvorgängen umgewandelt. Wir verwenden den gleichen Code, aber wir gehen zu einigen zusätzlichen Bibliotheken und Funktionen für Multiprocessing. Daher müssen wir den Prozess aus Multiprocessing importieren, so wie wir es bereits erklärt haben. Als nächstes erstellen wir eine Funktion namens „func“ und übergeben das Schlüsselwort „arg“, bevor wir „val=random“ verwenden, um eine Zufallszahl zu erhalten.
Nachdem wir dann die Methode „print()“ aufgerufen haben, um eine Nachricht anzuzeigen, und den Parameter „val“ angegeben haben, um eine kleine Zeitspanne zu verzögern, verwenden wir die Funktion „if name= main“, um die Einstiegspunkte zu sichern. Darauf erstellen wir einen Prozess und rufen die Funktion im Prozess mit „process“ auf und übergeben „target=func“. Dann übergeben wir „func“, „arg“, übergeben den Wert „m“ und übergeben den Bereich „10“, was bedeutet, dass die Schleife die Funktion nach „10“ Iterationen beendet. Anschließend starten wir den Prozess über die Methode „start()“ mit „process“. Dann rufen wir die Methode „join()“ auf, um auf die Ausführung des Prozesses zu warten und den gesamten Prozess danach abzuschließen.
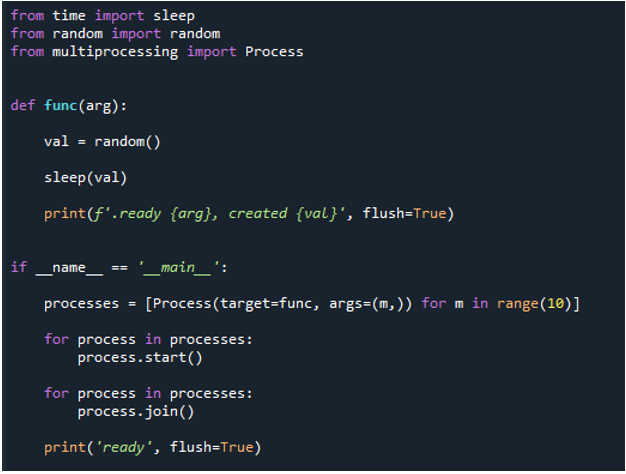
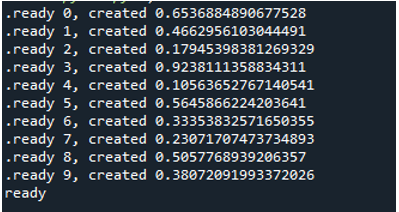
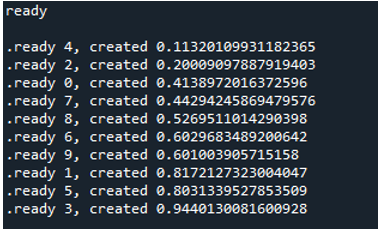
Wenn wir also den Code ausführen, rufen die Funktionen den Hauptprozess auf und beginnen mit der Ausführung. Sie werden jedoch ausgeführt, bis alle Aufgaben erfüllt sind. Das sehen wir daran, dass jede Aufgabe gleichzeitig ausgeführt wird. Es meldet seine Nachricht, sobald es fertig ist. Das bedeutet, dass die Schleife endet, obwohl die Nachrichten nicht in der richtigen Reihenfolge sind, nachdem alle „10“ Iterationen abgeschlossen sind.
Fazit
Wir haben in diesem Artikel die Python-Multiprocessing-for-Schleife behandelt. Wir haben auch zwei Illustrationen präsentiert. Die erste Abbildung zeigt, wie Sie eine for-Schleife in der Loop-Multiprocessing-Bibliothek von Python verwenden. Und die zweite Abbildung zeigt, wie Sie eine sequenzielle for-Schleife in eine parallele Multiprocessing-for-Schleife ändern. Bevor wir das Skript für Python-Multiprocessing erstellen, müssen wir das Multiprocessing-Modul importieren.