Es gibt viele weitere Methoden der File Input Stream-Klasse, die ebenfalls sehr hilfreich sind, um Daten aus einer Datei zu erhalten. Einige von ihnen sind int read(byte[] b), diese Funktion liest Daten aus dem Eingabestrom mit einer Länge von bis zu b.length Bytes. Der Dateikanal erhält den Kanal (): Das spezifische Dateikanalobjekt, das mit dem Dateieingabestrom verbunden ist, wird mit ihm zurückgegeben. Finalize() wird verwendet, um sicherzustellen, dass die close()-Funktion aufgerufen wird, wenn es keinen Verweis mehr auf den Dateieingabestrom gibt.“
Beispiel 01: Lesen eines einzelnen Bytes aus einer Textdatei unter Verwendung der read()- und close()-Methoden der Input-Stream-Klasse
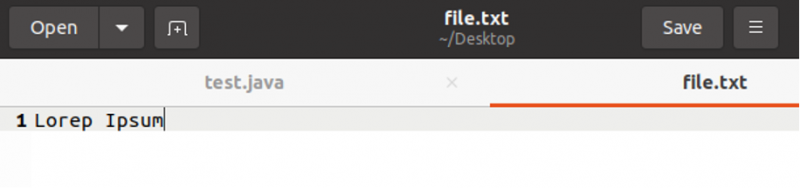
Dieses Beispiel verwendet File Input Stream, um ein einzelnes Zeichen zu lesen und den Inhalt auszudrucken. Angenommen, wir haben eine Datei namens „file.txt“ mit dem unten gezeigten Inhalt:

Angenommen, wir haben eine Datei namens „file.txt“ mit dem oben gezeigten Inhalt. Versuchen wir nun, das erste Zeichen der Datei zu lesen und zu drucken.
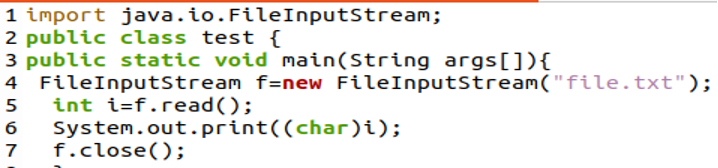
Wir müssen zuerst java.io importieren. File Input Stream-Paket, um einen Dateieingabestream zu erstellen. Dann erstellen wir ein neues Objekt des File Input Stream, das mit der in der Variablen „f“ angegebenen Datei (file.txt) verknüpft wird.
In diesem Beispiel verwenden wir die „int read()“-Methode der Java File Input Stream-Klasse, mit der ein einzelnes Byte aus der Datei gelesen und in der Variablen „I“ gespeichert wird. Als nächstes zeigt „System.out.print(char(i))“ das Zeichen an, das diesem Byte entspricht.
Die Methode f.close() schließt die Datei und den Stream. Nach dem Erstellen und Ausführen des oben genannten Skripts erhalten wir die folgende Ausgabe, da wir sehen können, dass nur der Anfangsbuchstabe des Textes „L“ gedruckt wird.

Beispiel 02: Lesen des gesamten Inhalts einer Textdatei unter Verwendung der read()- und close()-Methoden der Input-Stream-Klasse
In diesem Beispiel werden wir den gesamten Inhalt einer Textdatei lesen und anzeigen; Wie nachfolgend dargestellt:
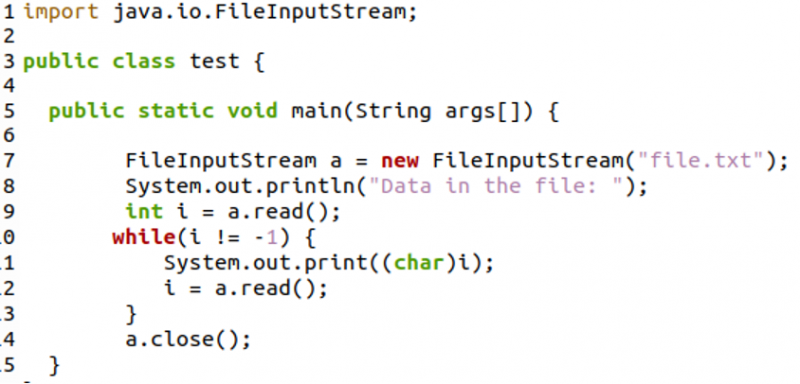
Wieder einmal werden wir java.io importieren. File Input Stream-Paket, um einen Dateieingabestream zu erstellen.
Zuerst lesen wir das erste Byte der Datei und zeigen das entsprechende Zeichen in der While-Schleife an. Die While-Schleife wird ausgeführt, bis keine Bytes mehr übrig sind, dh das Ende des Textes in der Datei. Zeile 12 liest das nächste Byte und die Schleife wird bis zum letzten Byte der Datei fortgesetzt.
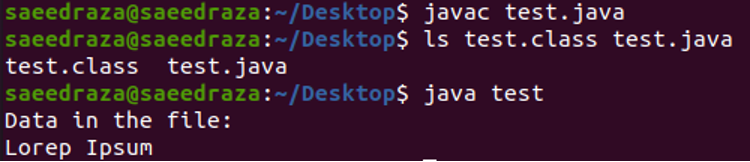
Nach dem Kompilieren und Ausführen des obigen Codes erhalten wir die folgenden Ergebnisse. Wie wir sehen können, wird der gesamte Text der Datei „Lorep Ipsum“ im Terminal angezeigt.
Beispiel 03: Bestimmen der Anzahl verfügbarer Bytes in einer Textdatei durch Verwenden der available()-Methode der Input-Stream-Klasse
In diesem Beispiel verwenden wir die Funktion „available()“ des Dateieingabestroms, um die Anzahl der vorhandenen Bytes im Dateieingabestrom zu bestimmen.
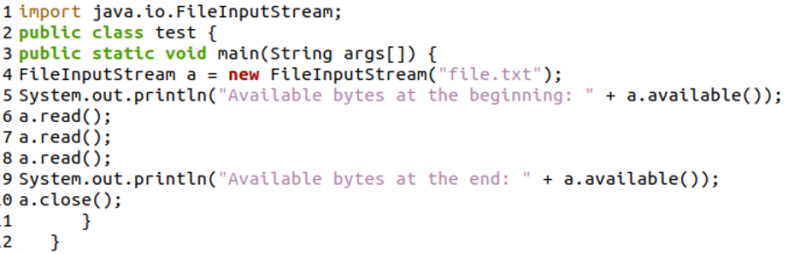
Zuerst haben wir mit dem folgenden Code ein Objekt der Dateieingabestromklasse namens „a“ generiert. In Zeile 5 haben wir die Methode „available()“ verwendet, um die Gesamtmenge der verfügbaren Bytes in der Datei zu ermitteln und anzuzeigen. Dann haben wir von Zeile 6 bis Zeile 8 die Funktion „read()“ dreimal verwendet. In Zeile 9 haben wir nun erneut die Methode „available()“ verwendet, um die verbleibenden Bytes zu prüfen und anzuzeigen.
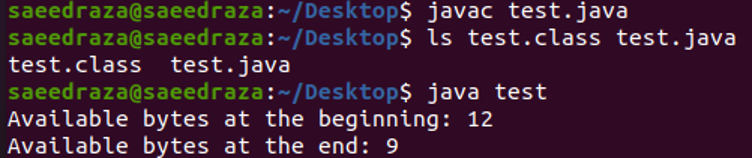
Nach dem Kompilieren und Ausführen des Codes können wir sehen, dass die erste Zeile der Ausgabe die Gesamtzahl der verfügbaren Bytes in der Datei anzeigt. Die nächste Zeile zeigt die Anzahl der am Ende des Codes verfügbaren Bytes, die 3 weniger als die am Anfang verfügbaren Bytes sind. Das liegt daran, dass wir die read-Methode dreimal in unserem Code verwendet haben.
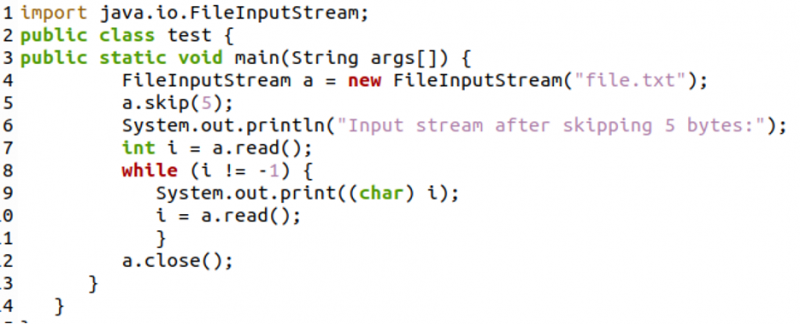
Beispiel 04: Überspringen von Bytes einer Textdatei zum Lesen von Daten von einem bestimmten Punkt mit der skip()-Methode der Input-Stream-Klasse
In diesem Beispiel verwenden wir die „skip(x)“-Methode von File Input Stream, die verwendet wird, um die angegebene Anzahl von Datenbytes aus dem Eingabestream zu ignorieren und zu ignorieren.
Im folgenden Code haben wir zunächst einen Dateieingabestream erstellt und in der Variablen „a“ gespeichert. Als nächstes haben wir die Methode „a.skip(5)“ verwendet, die die ersten 5 Bytes der Datei überspringt. Als nächstes druckten wir die restlichen Zeichen der Datei mit der Methode „read()“ innerhalb einer While-Schleife. Schließlich haben wir den Dateieingabestrom mit der Methode „close()“ geschlossen.
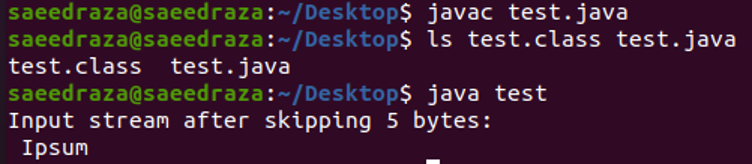
Unten ist der Screenshot des Terminals nach dem Kompilieren und Ausführen des Codes. Wie wir sehen können, wird nur „Ipsum“ angezeigt, da wir die ersten 5 Bytes mit der Methode „skip()“ übersprungen haben.
Fazit
In diesem Artikel haben wir die Verwendung der File Input Stream-Klasse und ihrer verschiedenen Methoden besprochen. read(), available(), skip() und close(). Wir haben diese Methoden verwendet, um das erste Element einer Datei mit den Methoden read() und close() zu lesen. Dann lesen wir die gesamte Datei durch den iterativen Ansatz und verwenden die gleichen Methoden. Dann haben wir die available()-Methode verwendet, um die Anzahl der Bytes zu bestimmen, die am Anfang und am Ende der Datei vorhanden sind. Danach haben wir die Methode skip() verwendet, um mehrere Bytes zu überspringen, bevor wir die Datei gelesen haben, wodurch wir die spezifischen Daten erhalten konnten, die wir brauchten.