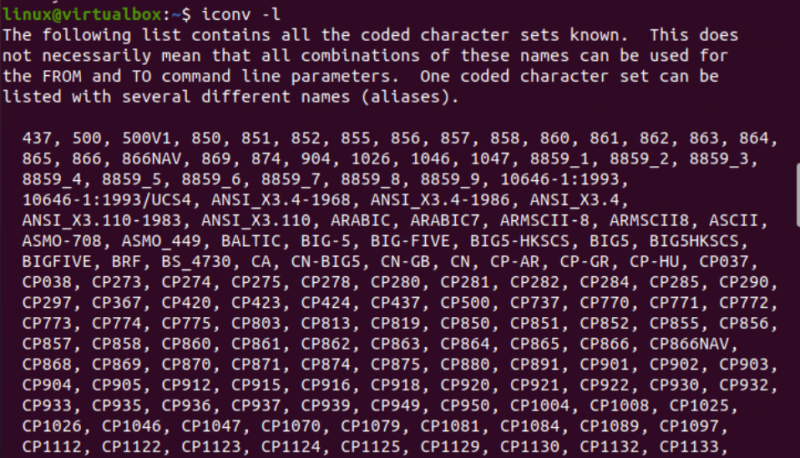
Schauen wir uns jetzt das Iconv-Dienstprogramm von Linux in seiner Terminalkonsole an. Wir haben also die Anweisung „iconv“ mit dem Flag „-l“ ausgeführt, um alle bekannten und am häufigsten verwendeten codierten Zeichensätze auf unserem Terminalbildschirm anzuzeigen. Es zeigt die codierten Zeichensätze zusammen mit ihren Aliasnamen an. Sie können eine lange Liste codierter Zeichensätze sehen, nachdem Sie ein wenig nach unten gescrollt haben.
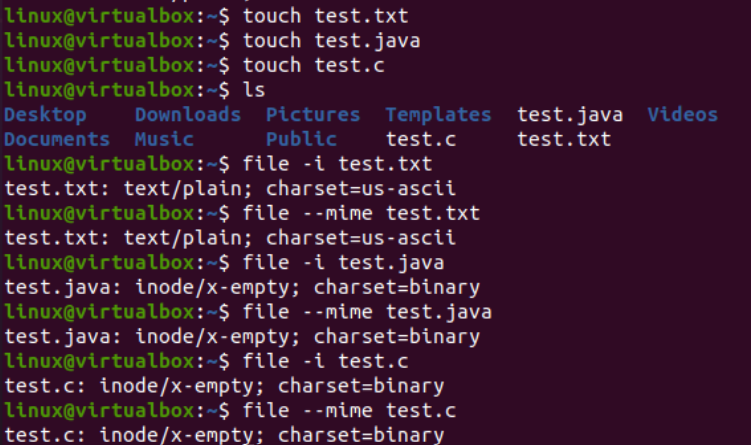
Jetzt ist es an der Zeit, mit der Implementierung des Befehls iconv in Linux zu beginnen. Erstens benötigen wir verschiedene Dateitypen in unserem System, um einen Dateityp in einen anderen zu konvertieren. Daher verwenden wir die „Touch“-Abfrage am Konsolenterminal, um drei verschiedene Dateien zu erstellen, d. h. Java-Typ, C-Typ und Texttyp. Wenn Sie den aktuellen Inhalt des Verzeichnisses auflisten, finden Sie darin die neu generierten Dateien.
Danach sehen wir uns den Typ jeder Datei separat an, indem wir die Abfrage „Datei“ zusammen mit dem Namen jeder Datei verwenden. Diese Abfrage benötigt die Option „-I“, um die Art des Codierungszeichensatzes für jede Datei separat anzuzeigen. Wenn Sie vergessen haben, die Option „-I“ zu verwenden, verwenden Sie stattdessen das Flag „—mime“. Sowohl die Flags „-I“ als auch „—mime“ funktionieren gleich.
Nachdem wir nun die Anweisung „file“ für die Datei vom Typ „txt“ ausgeführt haben, haben wir die Codierung des Zeichentyps „US-ASCII“ erhalten. Während die gleiche Anweisung für die Java- und C-Dateien verwendet wird, zeigt es, dass beide Dateien die Codierung des Zeichentyps „BINARY“ enthalten. Gleichzeitig zeigt diese Anweisung, dass alle diese drei Dateien leer sind.
Nun veranschaulichen wir die Verwendung der iconv-Anweisung an der Konsole, um eine bestimmte Zeichensatzcodierungsdatei in eine andere Zeichensatzcodierung zu konvertieren. Zuvor müssen wir unseren Dateien Code oder Daten hinzufügen. Daher haben wir den Java-Code in der Datei „text.java“, den C-Code in der Datei „text.c“ und Textdaten in der Datei „test.txt“ hinzugefügt. Die cat-Abfrage wurde hier verwendet, um den Inhalt aller drei Dateien anzuzeigen, wie unten dargestellt:
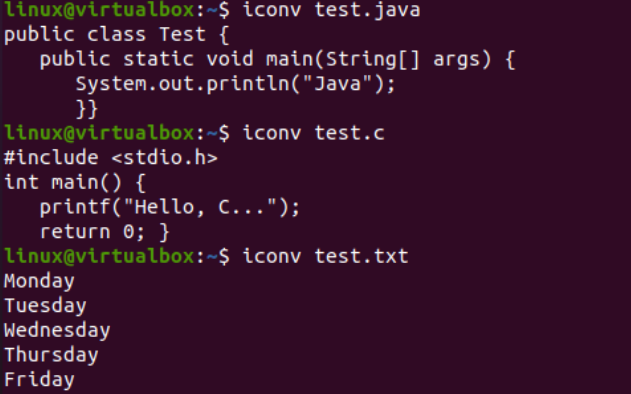
Nachdem wir die Daten erfolgreich hinzugefügt haben, sehen wir noch einmal die Zeichensatzkodierung dieser Dateien. Wir haben also dieselbe Dateianweisung innerhalb der Shell mit dem „-I“-Flag und den Dateinamen ausprobiert, d. h. test.txt, test.java und test.c. Die separate Ausführung dieser drei Anweisungen für alle drei Dateien zeigt, dass die Zeichensatzcodierung für die Java- und C-Dateien aktualisiert wurde, während sie für die Textdatei gleich blieb, d. h. US-ASCII. Die Kodierung von Java- und C-Dateien war bisher „binär“; jetzt ist es „US-ASCII“. Außerdem zeigt es, dass die Textdatei reine Textdaten enthält, während die anderen beiden Codedateien die Skripte als Inhalt enthalten.

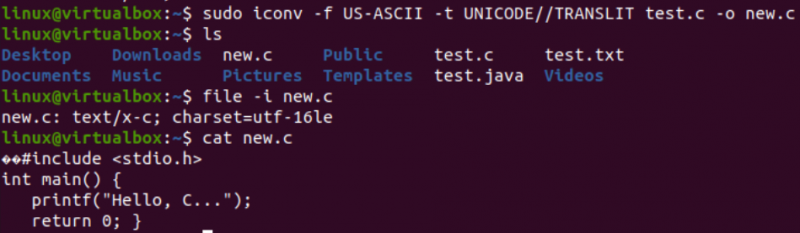
Es ist an der Zeit, die eigentliche Aufgabe für diesen Artikel auszuführen, d. h. eine Kodierung mit dem Befehl iconv in der Shell in eine andere umzuwandeln. Daher haben wir die „iconv“-Anweisung innerhalb des Shell-Terminals mit den „sudo“-Berechtigungen verwendet. Bei diesem Befehl steht die Option „-f“ für „from“ und die Option „-t“ steht für „to“, d. h. von einer Codierung zur anderen.
Nach der Option „-f“ müssen Sie die Codierung angeben, die Ihre Datei bereits hat, also US-ASCII. Nach der Option „-t“ müssen Sie die Codierung angeben, die Sie durch die alte Codierung ersetzen möchten, dh UNICODE. Sie müssen den Namen einer als Quelle verwendeten Datei mit der Option –o angeben, um ihr Objekt-Image zu erstellen. Das Objektbild wäre eine andere Datei, d. h. „new.c“, des gleichen Typs, aber mit der neuen Kodierung und den gleichen Daten.
Nachdem Sie die folgende Anweisung ausgeführt haben, erhalten Sie eine neue Datei im selben Verzeichnis, also gemäß der „ls“-Abfrage. Jetzt prüfen wir die Zeichensatzcodierung einer neuen Datei, die mit der iconv-Anweisung generiert wurde. Wir verwenden wieder die „file“-Anweisung mit der „-I“-Option und dem neuen Dateinamen, d. h. new.c.
Sie werden sehen, dass sich der Zeichensatz für diese neue Datei vom Zeichensatz einer alten Datei, d. h. dem UTF-16LE-Zeichensatz, unterscheidet. Dies liegt daran, dass wir die US-ASCII-Codierung mithilfe der iconv-Anweisung für unsere Datei new.c in die UNICODE-Codierung übersetzt haben. Die „cat“-Abfrage zeigte denselben C-Code innerhalb der Datei an, begann jedoch mit einigen Unicode-Zeichen, wie bereits dargestellt.
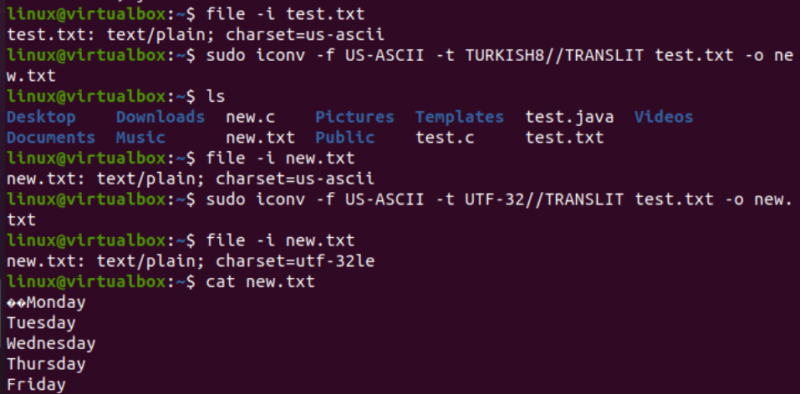
Auf sehr ähnliche Weise werden wir die Codierung der Textdatei test.txt ändern. Die Dateianweisung zeigt, dass es eine US-ASCII-Zeichensatzcodierung hat. Der Befehl iconv wurde mit demselben Format verwendet, um die Codierung der Datei test.txt von US-ASCII in TÜRKISH8 zu konvertieren. Sie werden sehen, dass US-ASCII nicht in Türkisch geändert wird.
Danach haben wir denselben Befehl verwendet, um die Zeichensatzcodierung von US-ASCII nach UTF-32 für dieselbe Datei abzudecken. Diesmal funktioniert es. Dies liegt daran, dass manchmal ein Problem beim Konvertieren eines Codierungssatzes in einen anderen auftreten kann oder die andere Codierung dies möglicherweise nicht unterstützt.
Fazit
In diesem Artikel wurde erläutert, wie Sie die Linux-Anweisungen von iconv verwenden, um einen Codierungszeichensatz mithilfe ihrer Aliase in einen anderen zu konvertieren. Auf diese Weise mussten wir einige Dateien unterschiedlichen Typs erstellen.