Das Hosten und Verwalten von Daten in Datenbanken und Data Warehouses war schon immer eine hektische und mühsame Aufgabe. Es erfordert viele Ressourcen und Rechenleistung, um die Daten zu verstehen. Amazon Web Services bietet hierfür eine Komplettlösung. Es verfügt über einen Dienst namens Amazon Redshift, der die Data Warehouses der Benutzer vollständig verwaltet.
In diesem Artikel wird Amazon Redshift zusammen mit seiner Data Warehouse-Architektur ausführlich erläutert. Alle Komponenten der Data-Warehouse-Systemarchitektur von Redshift werden im Detail erläutert.
Was ist Amazon Redshift?
IT ist ein Data-Warehousing-Dienst von Amazon. Es verwaltet und analysiert effizient große Datensätze für Analysen und Berichte. Es basiert auf einem Säulenspeichermodell. Es verwendet Cluster von Rechenknoten, die von einem Führungsknoten gesteuert werden, um eine leistungsstarke Datenverarbeitung bereitzustellen.
Es nimmt Daten aus verschiedenen Quellen und bündelt sie zu einem Data Warehouse. Es bietet verschiedene Funktionen wie Datenaustausch und Echtzeitanalysen. Sehen Sie sich das Bild unten an, um die Funktionen und Fähigkeiten von Amazon Redshift zu verstehen:
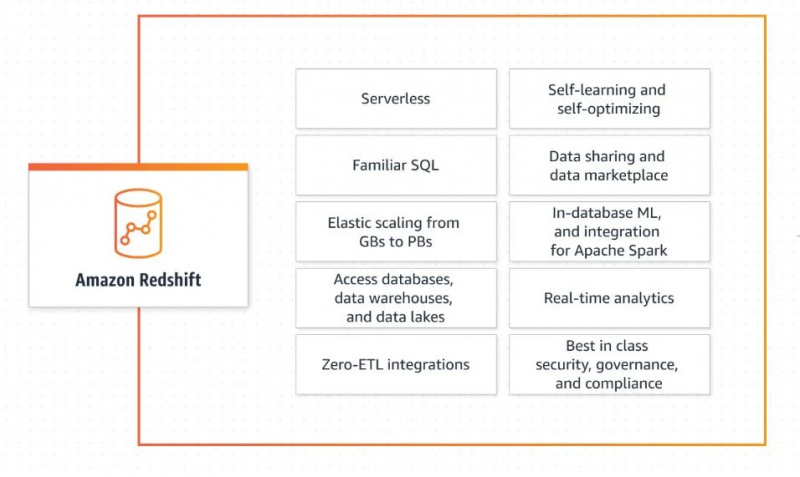
Kommen wir nun zur Architektur des Data-Warehouse-Systems.
Was ist die Architektur des Amazon Redshift Data Warehouse-Systems?
Diese Systemarchitektur besteht aus drei Kernteilen. Diese Teile sind:
- Lagerung
- Beschleunigung
- Berechnung
Lassen Sie uns ihre Zwecke verstehen:
Lagerung
Der Speicherteil befasst sich mit Speicherdiensten, die Redshift anbietet. Es verfügt über eine eigene Managed-Storage-Service-Option sowie eine S3-Bucket-Option.
Beschleunigung
Der Beschleunigungsanteil hängt vom verwendeten Speicherdienst und der eingesetzten Rechenleistung ab. Von Redshift verwalteter Speicher ist im Vergleich zu anderen Speicheroptionen schneller
Berechnung
Der Berechnungsteil befasst sich ausschließlich mit der verwendeten Rechenleistung. Die Berechnung erfolgt mit Clustern und Cluster haben Knoten. Knoten wiederum haben Slices.
Um alle Elemente und Komponenten dieser Architektur besser zu verstehen, sehen Sie sich das Bild unten an:
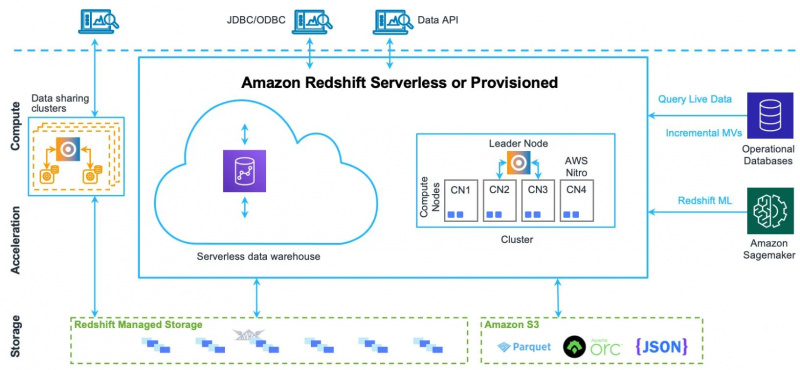
Lassen Sie uns seine Komponenten einzeln verstehen.
Was sind die Architekturkomponenten von Amazon Redshift?
Im Folgenden sind die Architekturkomponenten von Amazon Redshift aufgeführt:
- Cluster
- Knoten
- Knotenscheiben
- Lagerung
- Internes Netzwerk
- Datenbanken
Lassen Sie uns diese einzeln besprechen:
Cluster
Ein Cluster ist die Grund- und Kerneinheit. Es besteht aus einer Reihe von Knoten. Wenn ein Cluster aus mehreren Rechenknoten besteht, übernimmt ein zusätzlicher Leader-Knoten die Aufgabe, die Aktivitäten dieser Rechenknoten zu koordinieren und die externe Kommunikation zu verwalten.
Knoten
Es gibt zwei Arten von Knoten in Clustern. Diese sind:
- Führungsknoten
- Rechenknoten
Lassen Sie uns diese einzeln verstehen:
Führungsknoten
Es verwaltet die Kommunikation mit Clientprogrammen und koordiniert Interaktionen mit Rechenknoten. Der Führungsknoten spielt eine entscheidende Rolle bei der Ausführung komplexer Abfragen. Es kompiliert Code basierend auf dem Ausführungsplan, der an Rechenknoten verteilt wird, und weist jedem einzelnen Rechenknoten Datenteile zu.
Rechenknoten
Rechenknoten sind das Rückgrat der Architektur von Amazon Redshift. Sie führen sowohl die Speicherung als auch die Verarbeitung von Daten durch. Diese verfügen über dedizierte Ressourcen wie Speicher und CPU.
Knotenscheiben
Rechenknoten werden weiter in Slices unterteilt. Diese Slices arbeiten zusammen, um zugewiesene Arbeitslasten zu verarbeiten und Parallelität zu erreichen, um die Abfrageverarbeitung zu verbessern.
Lagerung
Die Datenspeicherung innerhalb von Amazon Redshift wird durch „Redshift Managed Storage (RMS)“ verwaltet. Es bietet die Möglichkeit, den Speicher mithilfe von „Amazon S3“-Speicher unabhängig zu skalieren. RMS verwendet leistungsstarken SSD-basierten lokalen Speicher als Tier-1-Cache, der die Leistung optimiert.
Internes Netzwerk
Dieses interne Netzwerk in Amazon Redshift hilft bei der schnellen und sicheren Kommunikation zwischen Leader-Knoten und Rechenknoten. Auf dieses Netzwerk können Clientanwendungen nicht direkt zugreifen.
Datenbanken
Cluster verfügen über eine oder mehrere Datenbanken. Daten aus diesen Datenbanken befinden sich auf Rechenknoten. Clientanwendungen kommunizieren mit dem Leader-Knoten. Der Rechenknoten verwaltet die Abfrageausführung über Rechenknoten hinweg.
Hier dreht sich alles um Amazon Redshift und seine architektonischen Elemente. In diesem Artikel wurden die Arbeitskomponenten von Amazon Redshift ausführlich erläutert
Abschluss
Die Architektur von Amazon Redshift ist der Grund, auf dem seine Fähigkeiten basieren. Der Leader-Knoten steuert und verwaltet die Rechenknoten und Knoten-Slices helfen bei der Parallelverarbeitung. Redshift Managed Storage nutzt SSD-basierten Speicher, um die Leistung zu steigern. In diesem Artikel wurde die Architektur des Amazon Redshift Data Warehouse-Systems erläutert.