Dieser Beitrag behandelt die PostgreSQL-Partitionierung. Wir werden die verschiedenen Partitionierungsoptionen besprechen, die Sie verwenden können, und zum besseren Verständnis Beispiele für deren Verwendung geben.
So erstellen Sie die PostgreSQL-Partitionen
Jede Datenbank kann zahlreiche Tabellen mit mehreren Einträgen enthalten. Für eine einfache Verwaltung sollten Sie die Tabellen partitionieren. Dies ist eine großartige und empfohlene Data-Warehouse-Routine zur Datenbankoptimierung und zur Verbesserung der Zuverlässigkeit. Sie können verschiedene Partitionen erstellen, einschließlich Liste, Bereich und Hash. Lassen Sie uns jeden im Detail besprechen.
1. Listenpartitionierung
Bevor wir über eine Partitionierung nachdenken, müssen wir die Tabelle erstellen, die wir für die Partitionen verwenden. Befolgen Sie beim Erstellen der Tabelle die angegebene Syntax für alle Partitionen:
CREATE TABLE Tabellenname(Spalte1 Datentyp, Spalte2 Datentyp) PARTITION BY
Der „Tabellenname“ ist der Name Ihrer Tabelle sowie die verschiedenen Spalten, die die Tabelle haben wird, und deren Datentypen. Beim „partition_key“ handelt es sich um die Spalte, nach der die Partitionierung erfolgt. Das folgende Bild zeigt beispielsweise, dass wir die Tabelle „Kurse“ mit drei Spalten erstellt haben. Darüber hinaus ist unser Partitionierungstyp LIST, und wir wählen die Fakultätsspalte als unseren Partitionierungsschlüssel aus:

Sobald die Tabelle erstellt ist, müssen wir die verschiedenen Partitionen erstellen, die wir benötigen. Gehen Sie dazu mit der folgenden Syntax vor:
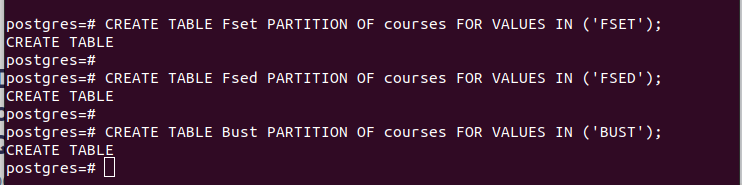
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES IN (VALUE);Das erste Beispiel im folgenden Bild zeigt beispielsweise, dass wir eine Partitionstabelle mit dem Namen „Fset“ erstellt haben, die alle Werte in der Spalte „faculty“ enthält, die wir als unseren Partitionsschlüssel ausgewählt haben, dessen Wert „FSET“ ist. Für die beiden anderen von uns erstellten Partitionen haben wir eine ähnliche Logik verwendet.
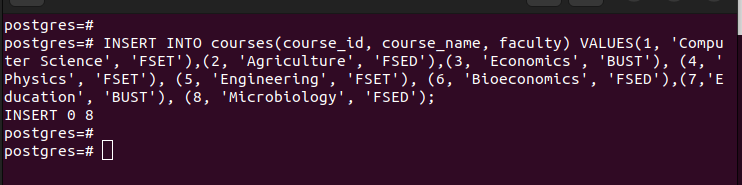
Sobald Sie die Partitionen haben, können Sie die Werte in die von uns erstellte Haupttabelle einfügen. Jeder von Ihnen eingegebene Wert wird mit der jeweiligen Partitionierung basierend auf den Werten im von Ihnen ausgewählten Partitionsschlüssel abgeglichen.
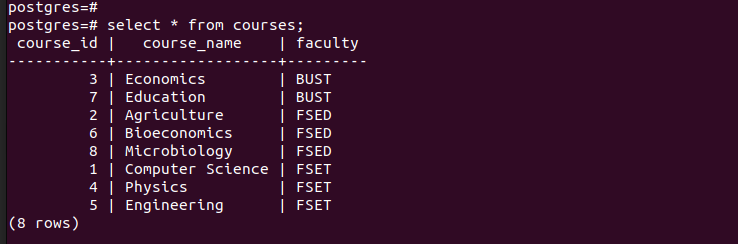
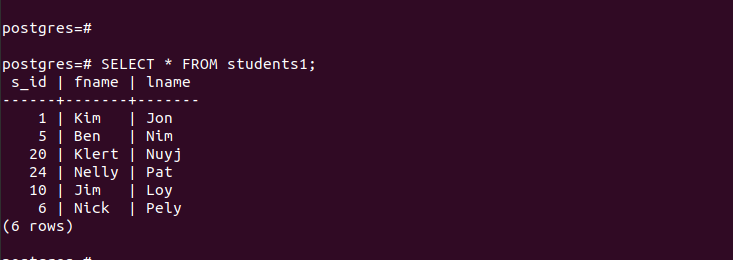
Wenn wir alle Einträge in der Haupttabelle auflisten, können wir sehen, dass sie alle Einträge enthält, die wir eingefügt haben.
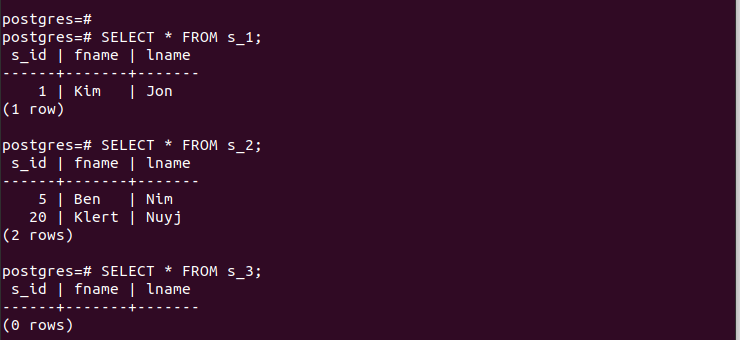
Um zu überprüfen, ob wir die Partitionen erfolgreich erstellt haben, überprüfen wir die Datensätze in jeder der erstellten Partitionen.
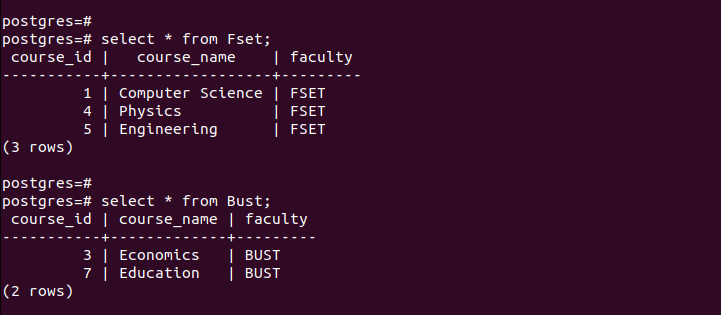
Beachten Sie, dass jede partitionierte Tabelle nur die Einträge enthält, die den beim Partitionieren definierten Kriterien entsprechen. So funktioniert die Partitionierung nach Liste.
2. Bereichspartitionierung
Ein weiteres Kriterium zum Erstellen von Partitionen ist die Verwendung der RANGE-Option. Dazu müssen wir die Start- und Endwerte angeben, die für den Bereich verwendet werden sollen. Die Verwendung dieser Methode ist ideal, wenn Sie mit Datumsangaben arbeiten.
Die Syntax zum Erstellen der Haupttabelle lautet wie folgt:
CREATE TABLE Tabellenname (Spalte1 Datentyp, Spalte2 Datentyp) PARTITION BY RANGE (Partitionsschlüssel);Wir haben die Tabelle „cust_orders“ erstellt und sie so angegeben, dass sie das Datum als unseren „partition_key“ verwendet.

Verwenden Sie zum Erstellen der Partitionen die folgende Syntax:
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES FROM (start_value) TO (end_value);Mithilfe der Spalte „Datum“ haben wir unsere Partitionen so definiert, dass sie vierteljährlich arbeiten.
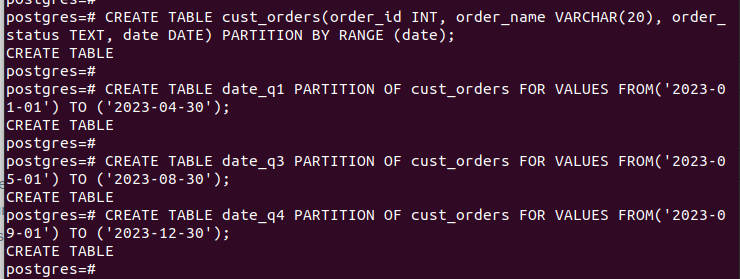
Nachdem wir alle Partitionen erstellt und die Daten eingefügt haben, sieht unsere Tabelle so aus:
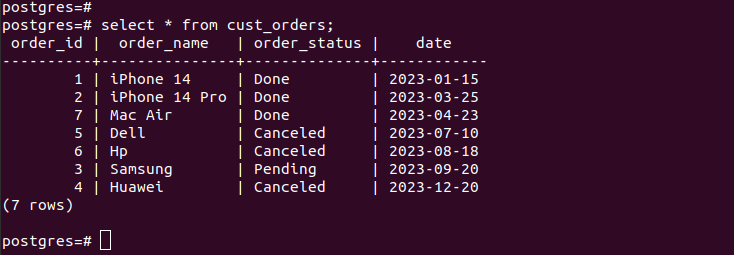
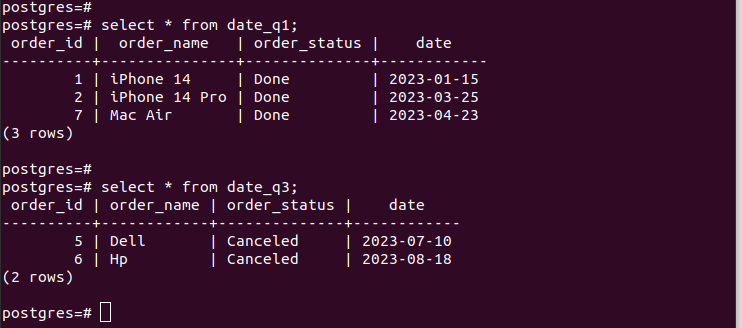
Wenn wir die Einträge in den erstellten Partitionen überprüfen, stellen wir sicher, dass unsere Partitionierung funktioniert und wir nur über die entsprechenden Datensätze gemäß den von uns angegebenen Partitionierungskriterien verfügen. Alle neuen Einträge, die Sie zu Ihrer Tabelle hinzufügen, werden automatisch der entsprechenden Partition hinzugefügt.
3. Hash-Partitionierung
Das letzte Partitionierungskriterium, das wir diskutieren werden, ist die Verwendung von Hash. Lassen Sie uns schnell die Haupttabelle mit der folgenden Syntax erstellen:
CREATE TABLE Tabellenname (Spalte1 Datentyp, Spalte2 Datentyp) PARTITION BY HASH (Partitionsschlüssel); 
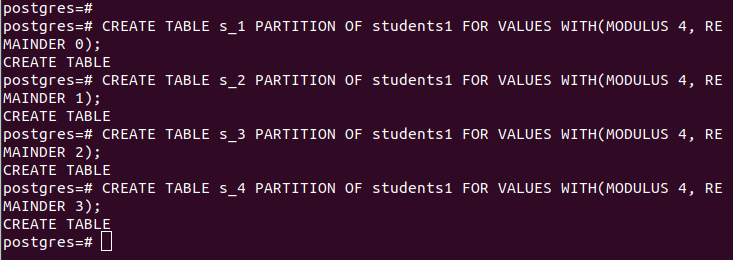
Bei der Partitionierung mit Hash müssen Sie den Modulus und den Rest angeben, also die Zeilen, die durch den Hash-Wert Ihres angegebenen „partition_key“ dividiert werden sollen. Für unseren Fall verwenden wir einen Modul von 4.
Unsere Syntax lautet wie folgt:
CREATE TABLE partition_table PARTITION OF main_table FOR VALUES WITH (MODULUS num1, REMAINDER num2);Unsere Partitionen sind wie folgt:
Für die „main_table“ enthält sie die Einträge, die im Folgenden dargestellt sind:
Für die erstellten Partitionen können wir schnell auf deren Einträge zugreifen und überprüfen, ob unsere Partitionierung funktioniert.
Abschluss
PostgreSQL-Partitionen sind eine praktische Möglichkeit, die Datenbank zu optimieren, um Zeit zu sparen und die Zuverlässigkeit zu erhöhen. Wir haben die Partitionierung ausführlich besprochen, einschließlich der verschiedenen verfügbaren Optionen. Darüber hinaus haben wir Beispiele zur Implementierung der Partitionen bereitgestellt. Probiere sie aus!