Optimieren des Python-Codes mit Profiling-Tools
Beim Einrichten von Google Colab zur Optimierung des Python-Codes mit Profilierungstools beginnen wir mit der Einrichtung einer Google Colab-Umgebung. Wenn wir neu bei Colab sind, handelt es sich um eine unverzichtbare, leistungsstarke cloudbasierte Plattform, die Zugriff auf Jupyter-Notebooks und eine Reihe von Python-Bibliotheken bietet. Wir greifen auf Colab zu, indem wir (https://colab.research.google.com/) besuchen und ein neues Python-Notizbuch erstellen.
Importieren Sie die Profilierungsbibliotheken
Unsere Optimierung basiert auf der kompetenten Nutzung von Profiling-Bibliotheken. Zwei wichtige Bibliotheken in diesem Zusammenhang sind cProfile und line_profiler.
importieren cProfile
importieren line_profiler
Die „cProfile“-Bibliothek ist ein integriertes Python-Tool zum Profilieren von Code, während „line_profiler“ ein externes Paket ist, das es uns ermöglicht, noch tiefer zu gehen und den Code Zeile für Zeile zu analysieren.
In diesem Schritt erstellen wir ein Beispiel-Python-Skript, um die Fibonacci-Folge mithilfe einer rekursiven Funktion zu berechnen. Lassen Sie uns diesen Prozess genauer analysieren. Die Fibonacci-Folge ist eine Zahlenfolge, bei der jede aufeinanderfolgende Zahl die Summe der beiden Einsen davor ist. Normalerweise beginnt es mit 0 und 1, sodass die Reihenfolge wie folgt aussieht: 0, 1, 1, 2, 3, 5, 8, 13, 21 usw. Es handelt sich um eine mathematische Folge, die aufgrund ihrer rekursiven Natur häufig als Beispiel in der Programmierung verwendet wird.
Wir definieren eine Python-Funktion namens „Fibonacci“ in der rekursiven Fibonacci-Funktion. Diese Funktion verwendet eine ganze Zahl „n“ als Argument, die die Position in der Fibonacci-Folge darstellt, die wir berechnen möchten. Wir wollen die fünfte Zahl in der Fibonacci-Folge finden, zum Beispiel wenn „n“ gleich 5 ist.
def Fibonacci ( N ) :
Als nächstes erstellen wir einen Basisfall. Ein Basisfall bei der Rekursion ist ein Szenario, das die Aufrufe beendet und einen vorgegebenen Wert zurückgibt. Wenn in der Fibonacci-Folge „n“ 0 oder 1 ist, kennen wir das Ergebnis bereits. Die 0. und 1. Fibonacci-Zahl sind 0 bzw. 1.
Wenn N <= 1 :zurückkehren N
Diese „if“-Anweisung bestimmt, ob „n“ kleiner oder gleich 1 ist. Wenn dies der Fall ist, geben wir „n“ selbst zurück, da keine weitere Rekursion erforderlich ist.
Rekursive Berechnung
Wenn „n“ 1 überschreitet, fahren wir mit der rekursiven Berechnung fort. In diesem Fall müssen wir die „n“-te Fibonacci-Zahl ermitteln, indem wir die „(n-1)“-te und „(n-2)“-te Fibonacci-Zahl summieren. Dies erreichen wir, indem wir innerhalb der Funktion zwei rekursive Aufrufe durchführen.
anders :zurückkehren Fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
Hier berechnet „fibonacci(n – 1)“ die „(n-1)“-te Fibonacci-Zahl und „fibonacci(n – 2)“ berechnet die „(n-2)“-te Fibonacci-Zahl. Wir addieren diese beiden Werte, um die gewünschte Fibonacci-Zahl an der Position „n“ zu erhalten.
Zusammenfassend lässt sich sagen, dass diese „Fibonacci“-Funktion die Fibonacci-Zahlen rekursiv berechnet, indem sie das Problem in kleinere Teilprobleme aufteilt. Es führt rekursive Aufrufe durch, bis es die Basisfälle (0 oder 1) erreicht und bekannte Werte zurückgibt. Für jedes andere „n“ berechnet es die Fibonacci-Zahl, indem es die Ergebnisse zweier rekursiver Aufrufe für „(n-1)“ und „(n-2)“ summiert.
Obwohl diese Implementierung die Berechnung der Fibonacci-Zahlen einfach macht, ist sie nicht die effizienteste. In den späteren Schritten verwenden wir die Profilierungstools, um die Leistungseinschränkungen zu identifizieren und zu optimieren, um die Ausführungszeiten zu verkürzen.
Profilierung des Codes mit CProfile
Jetzt profilieren wir unsere „Fibonacci“-Funktion mithilfe von „cProfile“. Diese Profilierungsübung bietet Einblicke in die Zeit, die jeder Funktionsaufruf verbraucht.
cprofiler = cProfile. Profil ( )cprofiler. aktivieren ( )
Ergebnis = Fibonacci ( 30 )
cprofiler. deaktivieren ( )
cprofiler. print_stats ( Sortieren = 'kumulativ' )
In diesem Segment initialisieren wir ein „cProfile“-Objekt, aktivieren die Profilerstellung, fordern die „Fibonacci“-Funktion mit „n=30“ an, deaktivieren die Profilerstellung und zeigen die nach kumulierter Zeit sortierten Statistiken an. Diese erste Profilerstellung gibt uns einen allgemeinen Überblick darüber, welche Funktionen die meiste Zeit verbrauchen.
! pip install line_profilerimportieren cProfile
importieren line_profiler
def Fibonacci ( N ) :
Wenn N <= 1 :
zurückkehren N
anders :
zurückkehren Fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
cprofiler = cProfile. Profil ( )
cprofiler. aktivieren ( )
Ergebnis = Fibonacci ( 30 )
cprofiler. deaktivieren ( )
cprofiler. print_stats ( Sortieren = 'kumulativ' )
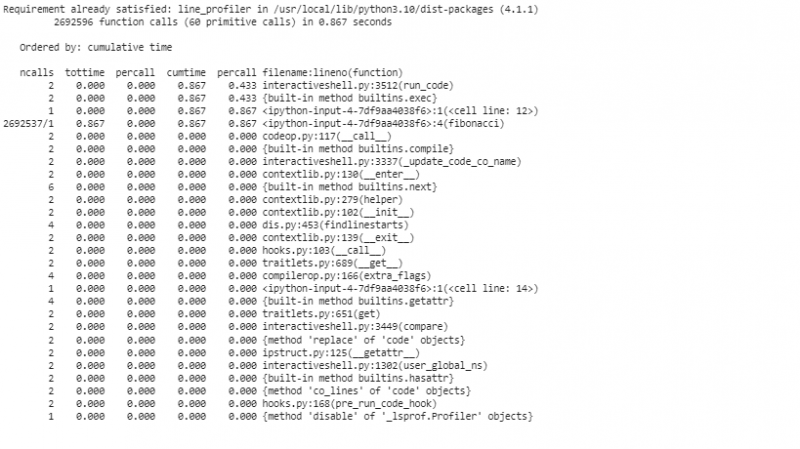
Um den Code Zeile für Zeile mit line_profiler für eine detailliertere Analyse zu profilieren, verwenden wir den „line_profiler“, um unseren Code Zeile für Zeile zu segmentieren. Bevor wir „line_profiler“ verwenden, müssen wir das Paket im Colab-Repository installieren.
! pip install line_profilerDa wir nun den „line_profiler“ fertig haben, können wir ihn auf unsere „fibonacci“-Funktion anwenden:
%load_ext line_profilerdef Fibonacci ( N ) :
Wenn N <= 1 :
zurückkehren N
anders :
zurückkehren Fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
%lprun -f fibonacci fibonacci ( 30 )
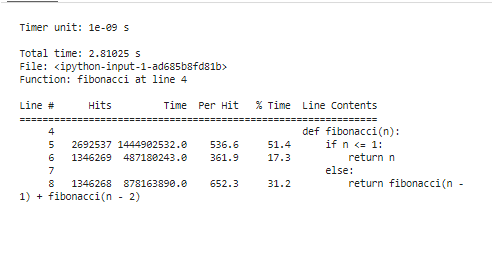
Dieses Snippet beginnt mit dem Laden der „line_profiler“-Erweiterung, definiert unsere „Fibonacci“-Funktion und verwendet schließlich „%lprun“, um die „Fibonacci“-Funktion mit „n=30“ zu profilieren. Es bietet eine zeilenweise Segmentierung der Ausführungszeiten und klärt genau, wo unser Code seine Ressourcen verbraucht.
Nachdem Sie die Profilierungstools zur Analyse der Ergebnisse ausgeführt haben, wird eine Reihe von Statistiken angezeigt, die die Leistungsmerkmale unseres Codes zeigen. Diese Statistiken umfassen die Gesamtzeit, die innerhalb jeder Funktion aufgewendet wurde, und die Dauer jeder Codezeile. Beispielsweise können wir feststellen, dass die Fibonacci-Funktion etwas mehr Zeit in die mehrfache Neuberechnung identischer Werte investiert. Dies ist die redundante Berechnung und ein klarer Bereich, in dem Optimierung angewendet werden kann, entweder durch Auswendiglernen oder durch den Einsatz iterativer Algorithmen.
Jetzt führen wir Optimierungen durch, bei denen wir eine potenzielle Optimierung in unserer Fibonacci-Funktion identifiziert haben. Wir haben festgestellt, dass die Funktion dieselben Fibonacci-Zahlen mehrmals neu berechnet, was zu unnötiger Redundanz und einer langsameren Ausführungszeit führt.
Um dies zu optimieren, implementieren wir die Memoisierung. Memoisierung ist eine Optimierungstechnik, bei der zuvor berechnete Ergebnisse (in diesem Fall Fibonacci-Zahlen) gespeichert und bei Bedarf wiederverwendet werden, anstatt sie neu zu berechnen. Dies reduziert redundante Berechnungen und verbessert die Leistung, insbesondere bei rekursiven Funktionen wie der Fibonacci-Folge.
Um die Memoisierung in unserer Fibonacci-Funktion zu implementieren, schreiben wir den folgenden Code:
# Wörterbuch zum Speichern berechneter Fibonacci-Zahlenfib_cache = { }
def Fibonacci ( N ) :
Wenn N <= 1 :
zurückkehren N
# Überprüfen Sie, ob das Ergebnis bereits zwischengespeichert ist
Wenn N In fib_cache:
zurückkehren fib_cache [ N ]
anders :
# Berechnen und zwischenspeichern Sie das Ergebnis
fib_cache [ N ] = Fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
zurückkehren fib_cache [ N ] ,
In dieser modifizierten Version der „Fibonacci“-Funktion führen wir ein „fib_cache“-Wörterbuch ein, um die zuvor berechneten Fibonacci-Zahlen zu speichern. Bevor wir eine Fibonacci-Zahl berechnen, prüfen wir, ob sie sich bereits im Cache befindet. Wenn ja, geben wir das zwischengespeicherte Ergebnis zurück. In allen anderen Fällen berechnen wir es, behalten es im Cache und geben es dann zurück.
Wiederholen der Profilerstellung und Optimierung
Nach der Implementierung der Optimierung (in unserem Fall der Memoisierung) ist es wichtig, den Profilierungsprozess zu wiederholen, um die Auswirkungen unserer Änderungen zu kennen und sicherzustellen, dass wir die Leistung des Codes verbessert haben.
Profilerstellung nach der Optimierung
Wir können dieselben Profilierungstools „cProfile“ und „line_profiler“ verwenden, um ein Profil für die optimierte Fibonacci-Funktion zu erstellen. Durch den Vergleich der neuen Profiling-Ergebnisse mit den vorherigen können wir die Wirksamkeit unserer Optimierung messen.
So können wir die optimierte „Fibonacci“-Funktion mithilfe von „cProfile“ profilieren:
cprofiler = cProfile. Profil ( )cprofiler. aktivieren ( )
Ergebnis = Fibonacci ( 30 )
cprofiler. deaktivieren ( )
cprofiler. print_stats ( Sortieren = 'kumulativ' )
Mit dem „line_profiler“ profilieren wir es Zeile für Zeile:
%lprun -f fibonacci fibonacci ( 30 )Code:
# Wörterbuch zum Speichern berechneter Fibonacci-Zahlenfib_cache = { }
def Fibonacci ( N ) :
Wenn N <= 1 :
zurückkehren N
# Überprüfen Sie, ob das Ergebnis bereits zwischengespeichert ist
Wenn N In fib_cache:
zurückkehren fib_cache [ N ]
anders :
# Berechnen und zwischenspeichern Sie das Ergebnis
fib_cache [ N ] = Fibonacci ( N - 1 ) + Fibonacci ( N - 2 )
zurückkehren fib_cache [ N ]
cprofiler = cProfile. Profil ( )
cprofiler. aktivieren ( )
Ergebnis = Fibonacci ( 30 )
cprofiler. deaktivieren ( )
cprofiler. print_stats ( Sortieren = 'kumulativ' )
%lprun -f fibonacci fibonacci ( 30 )
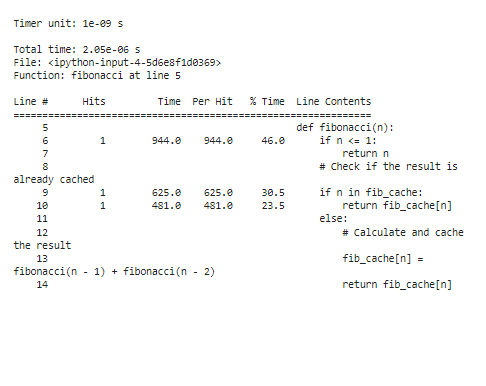
Um die Profilierungsergebnisse nach der Optimierung zu analysieren, werden die Ausführungszeiten erheblich verkürzt, insbesondere bei großen „n“-Werten. Aufgrund des Auswendiglernens stellen wir fest, dass die Funktion jetzt viel weniger Zeit mit der Neuberechnung der Fibonacci-Zahlen verbringt.
Diese Schritte sind im Optimierungsprozess von wesentlicher Bedeutung. Bei der Optimierung geht es darum, fundierte Änderungen an unserem Code vorzunehmen, die auf den Beobachtungen basieren, die aus der Profilerstellung gewonnen werden. Durch die wiederholte Profilerstellung wird sichergestellt, dass unsere Optimierungen die erwarteten Leistungsverbesserungen bringen. Durch iteratives Profiling, Optimieren und Validieren können wir unseren Python-Code optimieren, um eine bessere Leistung zu liefern und das Benutzererlebnis unserer Anwendungen zu verbessern.
Abschluss
In diesem Artikel haben wir das Beispiel besprochen, bei dem wir den Python-Code mithilfe von Profilierungstools in der Google Colab-Umgebung optimiert haben. Wir haben das Beispiel mit dem Setup initialisiert, die wesentlichen Profiling-Bibliotheken importiert, die Beispielcodes geschrieben, ein Profil mit „cProfile“ und „line_profiler“ erstellt, die Ergebnisse berechnet, die Optimierungen angewendet und die Leistung des Codes iterativ verfeinert.