In diesem Artikel erfahren Sie, welche Unterschiede zwischen diesen beiden Funktionen bestehen und wie sie funktionieren.
shuffle() in C++
Der Mischen() Die Funktion ist eine integrierte C++-Funktion, mit der die Elemente in einem bestimmten Bereich zufällig gemischt oder neu angeordnet werden. Die Funktion wird im deklariert
Darüber hinaus wird ein optionaler dritter Parameter benötigt, bei dem es sich um ein Funktionsobjekt handelt, das Zufallszahlen generiert, die zum Mischen der Elemente im Bereich verwendet werden.
Wenn das Mischen() Wenn die Funktion aufgerufen wird, ordnet sie mithilfe des bereitgestellten Zufallszahlengenerators die Elemente im angegebenen Bereich zufällig neu an. Das Ergebnis des Mischens ist nicht vorhersehbar und jede mögliche Permutation der Elemente tritt mit gleicher Wahrscheinlichkeit auf.
Beispiel
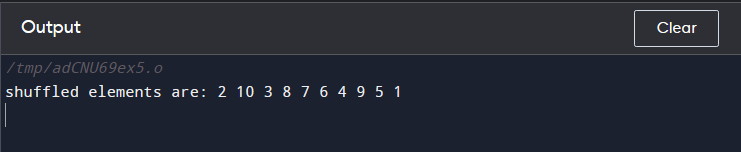
Betrachten Sie das folgende Beispiel für die Verwendung von shuffle()-Funktion in C++. In diesem Programm haben wir den Vektor erstellt ein Ding mit den ganzzahligen Werten von 0 bis 10. Dann generieren wir einen Zufallszahlengenerator, der dann zusammen mit dem Bereich des Vektors an den übergeben wird Mischen() Funktion. Der Mischen() Die Funktion nimmt die Zahl und tauscht die Elemente basierend auf dieser Zahl aus. Dann haben wir die neu angeordnete Vektorsequenz mithilfe der for-Schleife gedruckt
#include
#include
#include
#include
#include
Verwenden des Namensraums std ;
int hauptsächlich ( )
{
Vektor < int > ein Ding { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
ohne Vorzeichen Samen = Chrono :: System Uhr :: Jetzt ( ) . time_since_epoch ( ) . zählen ( ) ;
Mischen ( ein Ding. Start ( ) , ein Ding. Ende ( ) , default_random_engine ( Samen ) ) ;
cout << „gemischte Elemente sind:“ ;
für ( int & ich : ein Ding )
cout << ' ' << ich ;
cout << endl ;
zurückkehren 0 ;
}
random_shuffle() in C++
Der random_shuffle() Die Funktion ordnet die Elemente im angegebenen Bereich auch zufällig mit einer zufällig ausgewählten Zahl neu an. Es verwendet einen Zufallszahlengenerator, um eine Folge von Zufallszahlen zu generieren, und verwendet diese Zahlen dann, um die Elemente im Bereich zu mischen, sodass die Reihenfolge des Programms jedes Mal anders ist, wenn Sie das Programm ausführen.
Dafür sind zwei Parameter erforderlich random_shuffle() : Die Startposition des Bereichs ist der erste Parameter und der zweite Parameter ist die Endposition. Zusätzlich, random_shuffle() kann einen optionalen dritten Parameter annehmen, bei dem es sich um ein Funktionsobjekt handelt, das zum Generieren der Zufallszahlen zum Mischen der Elemente verwendet werden kann.
Beispiel
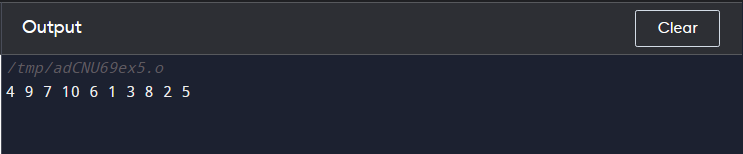
Das folgende Beispiel veranschaulicht die Funktionsweise des random_shuffle() in C++. In diesem Code haben wir eine erstellt Vektorsache mit ganzen Zahlenwerten von 1 bis 10 und dann verwendet for-Schleife So drucken Sie die zufällig gemischte Sequenz aus:
#include#include
Verwenden des Namensraums std ;
int hauptsächlich ( )
{
Vektor < int > ein Ding { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 } ;
Sand ( static_cast < ohne Vorzeichen int > ( Zeit ( nullptr ) ) ) ;
random_shuffle ( ein Ding. Start ( ) , ein Ding. Ende ( ) ) ;
für ( int ich : ein Ding ) {
cout << ich << ' ' ;
}
cout << ' \N ' ;
zurückkehren 0 ;
}
Unterschied zwischen shuffle() und random_shuffle()
Hier sind die wichtigsten Unterschiede zwischen Mischen() Und random_shuffle() Funktionen in C++.
1: random_shuffle() benötigt ein Iteratorpaar, das den Bereich der zu mischenden Elemente darstellt, while Mischen() benötigt ein Paar Iteratoren, die den Bereich der zu mischenden Elemente darstellen, sowie einen Zufallszahlengenerator, der zum Mischen verwendet wird.
2: random_shuffle() ist im Allgemeinen weniger effizient als Mischen() , da es eine Folge von Zufallszahlen erzeugen muss, die zum Mischen verwendet werden.
3: random_shuffle() verwendet die interne Implementierung des Zufallszahlengenerators der C++-Standardbibliothek, um die Elemente zu mischen, während Mischen() ermöglicht es Ihnen, Ihren eigenen Zufallszahlengenerator für das Mischen anzugeben, wodurch Sie mehr Kontrolle über die Zufälligkeit des Mischens haben.
4: random_shuffle() wurde in C++98 eingeführt und wird von allen Versionen der C++-Standardbibliothek unterstützt Mischen() wurde in C++11 eingeführt und wird nur von Compilern unterstützt, die diese Version des Standards implementieren.
Abschließende Gedanken
Die Wahl zwischen Mischen() Und random_shuffle() hängt von Ihrem spezifischen Anwendungsfall und Ihren Anforderungen ab. Wenn Sie mehr Kontrolle über die Zufälligkeit des Mischens benötigen oder einen benutzerdefinierten Zufallszahlengenerator verwenden möchten, dann Mischen() wäre eine bessere Wahl. Wenn Sie dieses Maß an Kontrolle jedoch nicht benötigen und nur eine einfache Möglichkeit zum Mischen von Elementen wünschen, dann ist dies der Fall random_shuffle() könnte ausreichen.