Die Verwaltung umfangreicher Datenmengen kann für Datenmanager eine schwierige Aufgabe sein, vor allem, wenn Ihre Abfrage- oder Scanergebnisse mehrere Seiten umfassen. Die Paginierung in DynamoDB ermöglicht es der Datenbank, die großen Datenmengen zu verarbeiten, indem die Ergebnisse in mehrere überschaubare Seiten aufgeteilt werden. Dieser Artikel erläutert die DynamoDB-Paginierung und stellt verschiedene mögliche Anwendungsfälle und Beispiele bereit. Außerdem wird hervorgehoben, wie sich die Paginierung in DynamoDB von der Paginierung in anderen Datenbanken unterscheidet.
Was ist Paginierung in DynamoDB?
Im Allgemeinen ist die von den Wortseiten abgeleitete Paginierung eine Technik, die von Datenbanken verwendet wird, um die Datensätze in mehrere Blöcke, Segmente oder Seiten aufzuteilen. Und da AWS DynamoDB das Speichern großer Datenmengen unterstützt, verfügt es über zuverlässige Paginierungsfunktionen.
Die DynamoDB-Paginierungskomponente stellt sicher, dass Sie nur bis zu 1 GB Daten pro Scan oder Abfrage abrufen können. Obwohl dies eine Standardeinstellung ist, können Sie einer Abfrage einen Begrenzungsparameter hinzufügen, um eine Begrenzung anzugeben. Sie können außerdem ein Limit für die Anzahl der Datensätze in jeder Scan-Abfrage festlegen.
Insbesondere bestehen einige Unterschiede zwischen der Paginierung in DynamoDB und der Paginierung in einer typischen SQL-Datenbank. Ganz offensichtlich ist jeder paginierte Datensatz, der in DynamoDB abgerufen wird, mit direkten Kosten verbunden, was dies zu einer ungeschriebenen Regel macht, wenn die Paginierung in DynamoDB verwendet wird. Diese Funktion macht die Paginierung zu einem entscheidenden Faktor bei der Begrenzung sowohl der abgerufenen Datensätze als auch der direkten Kosten.
So verwenden Sie die Paginierung in DynamoDB
1. Paginierung während einer Abfrageoperation
In DynamoDB gibt eine Abfrage nur die Ergebnisse von bis zu 1 MB zurück. Aber Sie können effektiv bestätigen, ob es mehr Ergebnisse gibt, indem Sie Ihre Ergebnisse überprüfen. Insbesondere enthält das Ergebnis eines Abfragevorgangs auf niedriger Ebene ein LastEvaluatedKey-Element, das nicht null ist, um anzugeben, dass weitere Elemente im Zusammenhang mit Ihrer Abfrage vorhanden sind, die Sie abrufen sollten.
Ein Ergebnis ohne ein LastEvaluatedKey-Element, das nicht null ist, impliziert, dass alle Elemente, die mit der Abfrage übereinstimmen, in die 1-MB-Grenze passen und es keine weiteren Elemente zum Abrufen gibt. Natürlich können Sie auch die Anzahl der Artikel pro Ergebnis begrenzen. Sehen Sie sich den folgenden Beispielbefehl an:
aws dynamodb-Abfrage \
--table-name MeinTabellenname \
--key-condition-expression 'Partitionsschlüssel = :pk \
--Ausdrucksattributwerte '{' :pk ':{' S ':' a1234b '}},
- Grenze 10 \
Sie können den vorherigen Befehl verwenden, um Ihre Tabelle nach Elementen mit denselben Schlüsselbedingungsausdruckswerten abzufragen. Lassen Sie uns unsere „Orders“-Tabelle nach order_Ids von Darry Tech durchsuchen. Wir haben auch ein Limit von 10 Artikeln pro Seite festgelegt. Eine weitere Option für den Parameter –limit ist die Verwendung des Parameters –page-size für den gleichen Zweck.
Paginierung ist ein automatischer Vorgang in AWS CLI für Elemente mit weniger als 1 MB an Daten. Sie können dem Befehl einen exklusiven Startschlüssel hinzufügen, wenn Sie möchten, dass Ihre Abfrage mit einer bestimmten Reihenfolge beginnt.
Die Antwort sieht so aus:
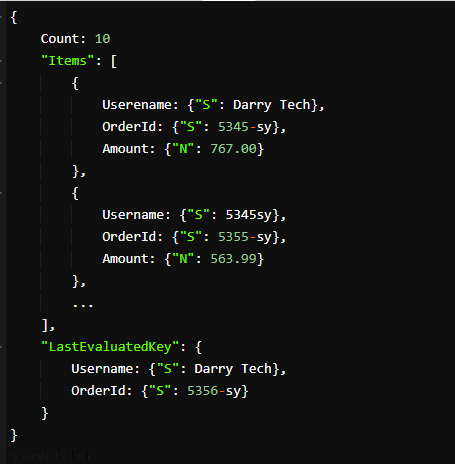
Die bereitgestellten Ergebnisse zeigen 10 Darry Tech auf der ersten Seite. Sie können die LastEvaluatedKey-Werte verwenden, um mehr Aufträge zu erhalten, die mit den Ausdrucksschlüsselwerten Ihrer Suche übereinstimmen, um eine neue Abfrage zu erstellen. Die neue Abfrageanforderung enthält die LastEvaluatedKey-Werte im ExclusiveStartKey-Parameter.
Ein Beispiel für die Syntax ist im Folgenden dargestellt:
aws dynamodb-Abfrage \--table-name Beispieltabelle \
--key-condition-expression 'Partitionsschlüssel = :pk \
--Ausdrucksattributwerte '{' :pk ':{' S ': Darry Tech ' \
- Grenze 10 \
--exclusive-start-key '{' Partitionsschlüssel ':{' S ': Darry Tech' }, 'Sortierschlüssel' :{ 'S' : '5356' }} '
Der vorherige Befehl erzeugt die nächsten Verrechnungsaufträge auf der nächsten Seite, beginnend mit der Auftrags-ID, die den angegebenen Primärschlüssel hat, d. h. {'PartitionKey':{'S': Darry Tech'},'SortKey':{'S': „5356-sy“}}.
2. Paginierung während Scanvorgängen
Es ist auch möglich, die Paginierung für Scanvorgänge zu verwenden. Alles funktioniert genauso wie bei den Abfragebefehlen. Sie müssen jedoch das filter-expression-Attribut verwenden. Der Befehl sieht so aus, wie wir ihn hier haben:
aws dynamodb-Scan \--table-name MeineTabelle \
--filter-ausdruck 'Attributname = :value' \
--Ausdrucksattributwerte '{':value':{'S':'ABC123'}}' \
--Grenze zwanzig \
--exklusiver-Startschlüssel '{'PartitionKey':{'S':'ABC123'},'SortKey':{'S':'XYZ987'}}'
Der vorherige Befehl entfernt bis zu 20 Elemente pro Seite aus der MyTable-Tabelle, beginnend mit dem Element, dessen Primärschlüssel {'PartitionKey': 'ABC123', 'SortKey': 'XYZ987'} ist. Es filtert die Ergebnisse so, dass nur die Elemente enthalten sind, bei denen das AttributeName-Attribut den Wert „ABC123“ hat.
In der Antwort, die LastEvaluatedKey Das Feld enthält den Primärschlüssel des letzten Elements in der Ergebnismenge. Sie können diesen Wert als verwenden ExclusiveStartKey in einer Folge Scan Vorgang zum Abrufen der nächsten Ergebnisseite.
Fazit
Die Paginierung in DynamoDB verbessert die Verwaltbarkeit von Daten. Es ist jedoch wichtig zu wissen, ob Ihre Systeme von der Paginierung profitieren. Wenn Sie eine lange Liste von Elementen in einer Anwendung haben, ist die Verwendung von Paginierung erforderlich. Während sich die bereitgestellte Abbildung auf den AWS CLI-Aufruf konzentriert, können Sie die Paginierung auch mit AWS SDKs wie Pythons Boto3 oder einem beliebigen SDK Ihrer Wahl verwenden.