„Python bietet eine breite Palette von Datenstrukturen und Operationen für die Handhabung von numerischen und Zeitreihendaten. Der von uns erstellte oder in Pandas importierte DataFrame kann für eine Vielzahl von Zwecken verwendet werden. Neben der Datenquelle können auch die Spalten im Datenrahmen angepasst werden. Pandas vereinfachen viele der mühsamen und zeitaufwändigen Aufgaben, die mit der Bearbeitung der Daten verbunden sind. Es gibt vier Möglichkeiten, eine Spalte zu einem DataFrame in Pandas hinzuzufügen, aber in diesem Artikel verwenden wir die Panda-Spaltenfunktion „insert()“.
Nachdem wir unseren DataFrame in Pandas erstellt oder geladen haben, gibt es eine Vielzahl von Dingen, die wir erreichen möchten. Beispielsweise können wir Daten weiter manipulieren, indem wir beispielsweise die Spalten im Datenrahmen ändern. Als Nächstes müssen wir verstehen, wie man Spalten in einen Datenrahmen einbezieht, wenn die Mehrheit der Daten von einem Datenanbieter stammt, einige Daten jedoch von einem anderen. Eine Spalte kann einfach zu einem Pandas-Datenrahmen hinzugefügt werden.“
Pandas insert() Methode
Die letzte Spalte des Datenrahmens wird von einer anderen Funktion generiert. Durch die Verwendung der DataFrame-Methode „insert()“ können Sie Spalten zwischen aktuellen Spalten hinzufügen, anstatt sie am Ende des Pandas-DataFrame hinzuzufügen. Es bietet uns die Möglichkeit, an beliebiger Stelle eine Spalte hinzuzufügen, anstatt nur am Schluss. Darüber hinaus bietet es viele Möglichkeiten, die Werte für die Spalten hinzuzufügen. Wenn Sie eine Spalte an einer bestimmten Position oder einem bestimmten Index hinzufügen müssen, ist die pandas-Funktion „insert()“ hilfreich.
Syntax für die Spalte insert() von Pandas

Beispiel 1: Einfügen einer Spalte in einen Datenrahmen mit Pandas insert()-Methode
Beginnen Sie mit dem ersten Beispiel des Artikels, in dem wir erklären, wie Sie eine Spalte in einen Datenrahmen einfügen. Mit dem Tool „Spyder“ können wir diesen Code nachweisen. Zuerst generieren wir einen Datenrahmen namens „Kurs“. Wir haben zwei Spalten in diesem Datenrahmen, „course_title“ und „fee“. In der Spalte „Kurstitel“ haben wir eine Liste der Kurse „Python“, „Java“, „Objektorientiert“ und „PHP“. In der zweiten Spalte „Gebühr“ haben wir die Liste der Kursgebühren, die „30000“, „25000“, „15000“ und „22000“ lautet. Das Anzeigen unseres Datenrahmens „Kurs“ mithilfe von „pd. Datenrahmen“.
Als Nächstes besprechen wir die Hauptfunktion des Codes, die Pandas „insert()-Spalte“ ist. Es ist eine effiziente Methode, eine neue Liste in den Datenrahmen aufzunehmen. Sie können die neue Spalte mit der Einfügemethode an einer beliebigen angegebenen Stelle hinzufügen. Diese Methode ermöglicht auch das manuelle Hinzufügen einer Spalte zu einem Datenrahmen, aber die Anpassungsfähigkeit ist geringer.
Durchgängiges Einfügen bedeutet, dass der Quell-DataFrame während des Vorgangs direkt aktualisiert wird und kein neuer DataFrame erstellt wird. In diesem Fall haben wir unserem Datenrahmen eine neue Spalte mit dem Namen „Time_duration“ hinzugefügt, indem wir die Funktion „insert()“ verwendet haben. Die Werteliste in dieser Spalte ist „6_Monate“, „3_Monate“, „3Monate“ und „6_Monate“. Wir haben eine Spalte „Time_duration“ mit einem Index, der im Programm unten als „2“ definiert ist. Da der Index angegeben ist, würde der DataFrame einen Bereich erhalten, der bei 0 beginnt und schrittweise zunimmt, was bedeutet, dass diese Spalte als dritte Spalte im Datenrahmen angezeigt wird. Der DataFrame fügt eine neue Spalte mit dem Namen „Time _duration“ hinzu, indem er die Funktion „pd.insert()“ verwendet.
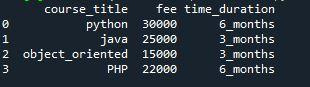
Lassen Sie uns nun die Ausgabe des Programms von oben besprechen. Seine Ausgabe zeigt einen Datenrahmen mit drei Spalten. Die zusätzliche Spalte wird am Ende des Datenrahmens hinzugefügt. Durch die Verwendung der Methode „pd.DataFrame.insert()“ können Sie eine Spalte zwischen anderen Spalten hinzufügen, anstatt sie am Ende des Pandas-Datenrahmens hinzuzufügen. Funktion. Position „2“ bezieht sich auf die dritte Spalte im Datenrahmen, da die Position bei 0 beginnt. Die Spalte wird an der letzten Stelle im Datenrahmen hinzugefügt.
Beispiel 2: Spalten in einen Datenrahmen hinzufügen, indem Pandas die insert()-Funktion verwendet
Wir werden die Methode „insert()“ verwenden, um dem Datenrahmen neue Spalten hinzuzufügen. Anstatt zusätzliche Spalten am Ende der Pandas hinzuzufügen, können Sie sie zwischen den vorhandenen Spalten einfügen. Um einen Datenrahmen ähnlich dem vorherigen Beispiel zu generieren, haben wir drei Spalten genommen und ihnen Werte zugewiesen. In der ersten Spalte „Name“ haben wir eine Liste mit Namen, darunter „Emma“, „Ella“, „Smith“ und „Maxwell“. In der zweiten Spalte „Alter“ haben wir die Werteliste „29“, „36“, „39“ und „33“.
Danach drucken wir eine Erklärung „DataFrame“. Wir zeigen den Datenrahmen unter der „Datenrahmen“-Anweisung. Wir erstellen mit der Funktion „insert()“ eine weitere Spalte für den Pandas-Datenrahmen. Eine Liste muss erstellt werden, damit sie unserem gegebenen Datensatz als neue Spalte hinzugefügt werden kann. Die „assign()“-Methode des Pandas DataFrame kann auch verwendet werden, um weitere Spalten hinzuzufügen. Wir fügen eine neue Spalte ein, indem wir „df. Einfügung'. Die zusätzliche Spalte „Geschlecht“ zeigt das Geschlecht entweder als „männlich“ oder „weiblich“ an.
Lassen Sie uns einfach eine weitere Anweisung „Neuer Datenrahmen“ drucken. Unterhalb der Anweisung „Neuer Datenrahmen“ wird nun ein neuer Datenrahmen angezeigt, der die zusätzliche Spalte enthält, die wir mit dem „pd. insert()“-Funktion. Die gleichnamige Spalte kann nicht mit der Funktion „insert()“ hinzugefügt werden. Falls eine Spalte bereits im Datenrahmen vorhanden ist, wird standardmäßig ein Wertfehler ausgegeben.
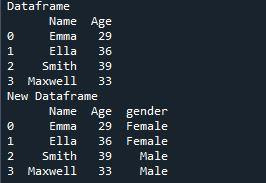
In dieser Ausgabe wird die Spalte, die wir mit der Funktion „insert()“ erstellt haben, dem Datenrahmen hinzugefügt. Seine Ausgabe zeigt zwei Datenrahmen an; Der erste dataFrame wurde mit „pd.data frame“ erstellt, in dem wir zwei Spalten haben, „Name“ und „Alter“. Die neue Spalte „Geschlecht“, die wir mit der Funktion „Einfügen()“ hinzugefügt haben, wird im zweiten unten angezeigten Datenrahmen angezeigt. Dieser Datenrahmen zeigt, dass es drei Spalten mit einigen Daten gibt. Der Index ist „2“ groß, hat also Einträge von „0 bis 3“. Die neue Spalte, die wir diesem Datenrahmen zugewiesen haben, hat die Indexposition „3“.
Fazit
Ein häufig verwendeter Datenanalyse- und Aktualisierungsvorgang ist das Hinzufügen von Spalten zu DataFrame. Pandas bietet Ihnen jedoch zahlreiche Möglichkeiten, die Aufgabe zu erledigen, indem es vier verschiedene Methoden anbietet. In unserem Artikel verwenden wir jedoch nur eine Technik, nämlich die panadas-Spalte „insert()“. Einer der schwierigsten Teile beim Erweitern eines DataFrame mit neuen Spalten ist die Indizierung. Lassen Sie uns beide Beispiele kurz beschreiben. Wir haben zuerst einen Datenrahmen mit dem Titel Kurs erstellt und die Spalten „Kurstitel“ und „Gebühr“ hinzugefügt und dieser Spalte Werte zugewiesen. Mit der Funktion „insert()“ fügen wir dann eine neue Spalte zum selben Datenrahmen hinzu, die ihre Position als „2“ im Index angibt. Im zweiten Beispiel werden zwei DataFrames gezeigt. Wir haben zwei Spalten erstellt und einige Werte im ersten Datenrahmen aufgelistet. Dann haben wir mit der Funktion insert() eine neue Spalte mit dem Namen „Gender“ in den Datenrahmen eingefügt, sie wurde auch als „2“ im Index positioniert; Jetzt wird die Tabelle erneut angezeigt, wie im obigen zweiten Beispiel gezeigt.
Nachdem wir die oben genannten Techniken gemeistert haben, können wir dem DataFrame ganz einfach neue Spalten hinzufügen.