In dieser Anleitung wird veranschaulicht, wie VectorStoreRetrieverMemory mithilfe des LangChain-Frameworks verwendet wird.
Wie verwende ich VectorStoreRetrieverMemory in LangChain?
Das VectorStoreRetrieverMemory ist die Bibliothek von LangChain, die zum Extrahieren von Informationen/Daten aus dem Speicher mithilfe der Vektorspeicher verwendet werden kann. Vektorspeicher können zum Speichern und Verwalten von Daten verwendet werden, um die Informationen entsprechend der Eingabeaufforderung oder Abfrage effizient zu extrahieren.
Um den Prozess der Verwendung des VectorStoreRetrieverMemory in LangChain zu erlernen, gehen Sie einfach die folgende Anleitung durch:
Schritt 1: Module installieren
Starten Sie den Prozess der Verwendung des Memory Retrievers, indem Sie LangChain mit dem Befehl pip installieren:
pip langchain installieren
Installieren Sie die FAISS-Module, um die Daten mithilfe der semantischen Ähnlichkeitssuche zu erhalten:
pip install faiss-gpu 
Installieren Sie das Chromadb-Modul zur Nutzung der Chroma-Datenbank. Es fungiert als Vektorspeicher zum Aufbau des Speichers für den Retriever:
pip chromadb installieren 
Zur Installation ist ein weiteres Modul „tiktoken“ erforderlich, mit dem Token erstellt werden können, indem Daten in kleinere Blöcke umgewandelt werden:
pip tiktoken installieren 
Installieren Sie das OpenAI-Modul, um seine Bibliotheken zum Erstellen von LLMs oder Chatbots mithilfe seiner Umgebung zu verwenden:
pip openai installieren 
Richten Sie die Umgebung ein auf der Python-IDE oder im Notebook mit dem API-Schlüssel aus dem OpenAI-Konto:
importieren Duimportieren getpass
Du . etwa [ „OPENAI_API_KEY“ ] = getpass . getpass ( „OpenAI-API-Schlüssel:“ )
Schritt 2: Bibliotheken importieren
Der nächste Schritt besteht darin, die Bibliotheken aus diesen Modulen für die Verwendung des Memory Retrievers in LangChain abzurufen:
aus langchain. Aufforderungen importieren PromptTemplateaus Terminzeit importieren Terminzeit
aus langchain. lms importieren OpenAI
aus langchain. Einbettungen . openai importieren OpenAIEmbeddings
aus langchain. Ketten importieren Konversationskette
aus langchain. Erinnerung importieren VectorStoreRetrieverMemory
Schritt 3: Vector Store initialisieren
Dieses Handbuch verwendet die Chroma-Datenbank nach dem Import der FAISS-Bibliothek, um die Daten mithilfe des Eingabebefehls zu extrahieren:
importieren faissaus langchain. docstore importieren InMemoryDocstore
#Importieren von Bibliotheken zum Konfigurieren der Datenbanken oder Vektorspeicher
aus langchain. Vektorstores importieren FAISS
#Einbettungen und Texte erstellen, um diese in den Vektorspeichern zu speichern
Einbettungsgröße = 1536
Index = faiss. IndexFlatL2 ( Einbettungsgröße )
einbettung_fn = OpenAIEmbeddings ( ) . eingebettete_Abfrage
vectorstore = FAISS ( einbettung_fn , Index , InMemoryDocstore ( { } ) , { } )
Schritt 4: Erstellen eines Retrievers mit Unterstützung durch einen Vector Store
Bauen Sie den Speicher auf, um die neuesten Nachrichten in der Konversation zu speichern und den Kontext des Chats abzurufen:
Retriever = vectorstore. as_retriever ( search_kwargs = dict ( k = 1 ) )Erinnerung = VectorStoreRetrieverMemory ( Retriever = Retriever )
Erinnerung. save_context ( { 'Eingang' : 'Ich esse gern Pizza' } , { 'Ausgabe' : 'fantastisch' } )
Erinnerung. save_context ( { 'Eingang' : „Ich bin gut im Fußball“ } , { 'Ausgabe' : 'OK' } )
Erinnerung. save_context ( { 'Eingang' : „Ich mag die Politik nicht“ } , { 'Ausgabe' : 'Sicher' } )
Testen Sie den Speicher des Modells anhand der vom Benutzer bereitgestellten Eingaben mit seinem Verlauf:
drucken ( Erinnerung. Load_memory_variables ( { 'prompt' : „Welche Sportart soll ich mir ansehen?“ } ) [ 'Geschichte' ] ) 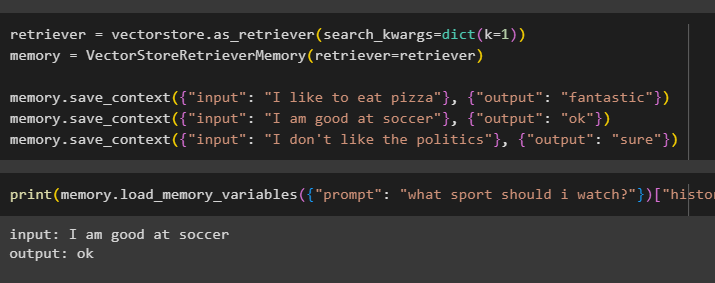
Schritt 5: Retriever in einer Kette verwenden
Der nächste Schritt ist die Verwendung eines Memory Retrievers mit den Ketten, indem das LLM mithilfe der OpenAI()-Methode erstellt und die Eingabeaufforderungsvorlage konfiguriert wird:
llm = OpenAI ( Temperatur = 0 )_DEFAULT_TEMPLATE = „“„Das ist eine Interaktion zwischen einem Menschen und einer Maschine
Das System erzeugt nützliche Informationen mit Details mithilfe des Kontexts
Wenn das System keine Antwort für Sie parat hat, wird einfach die Meldung „Ich habe keine Antwort“ angezeigt
Wichtige Informationen aus dem Gespräch:
{Geschichte}
(Wenn der Text nicht relevant ist, verwenden Sie ihn nicht)
Aktueller Chat:
Mensch: {input}
KI:'''
PROMPT = PromptTemplate (
Eingabevariablen = [ 'Geschichte' , 'Eingang' ] , Vorlage = _DEFAULT_TEMPLATE
)
#Konfigurieren Sie die ConversationChain() mithilfe der Werte für ihre Parameter
Konversation_mit_Zusammenfassung = Konversationskette (
llm = llm ,
prompt = PROMPT ,
Erinnerung = Erinnerung ,
ausführlich = WAHR
)
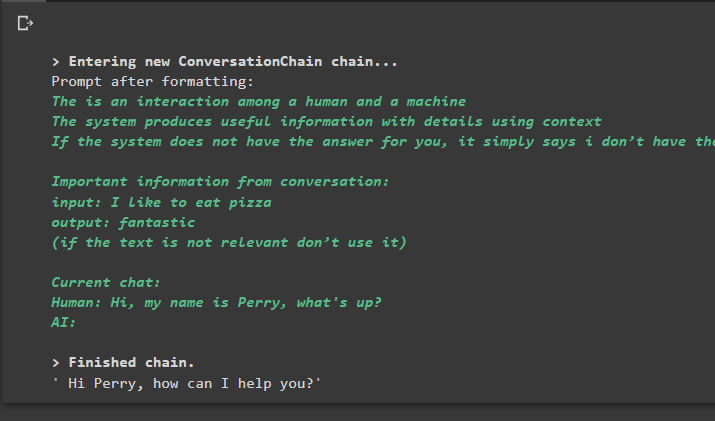
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = „Hallo, mein Name ist Perry, was ist los?“ )
Ausgabe
Durch Ausführen des Befehls wird die Kette ausgeführt und die vom Modell oder LLM bereitgestellte Antwort angezeigt:
Fahren Sie mit der Konversation fort, indem Sie die Eingabeaufforderung verwenden, die auf den im Vektorspeicher gespeicherten Daten basiert:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = „Was ist mein Lieblingssport?“ ) 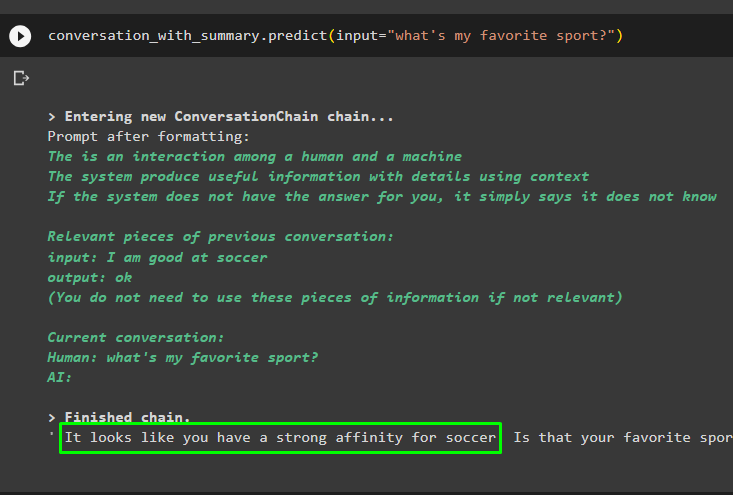
Die vorherigen Nachrichten werden im Speicher des Modells gespeichert und können vom Modell verwendet werden, um den Kontext der Nachricht zu verstehen:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = „Was ist mein Lieblingsessen“ ) 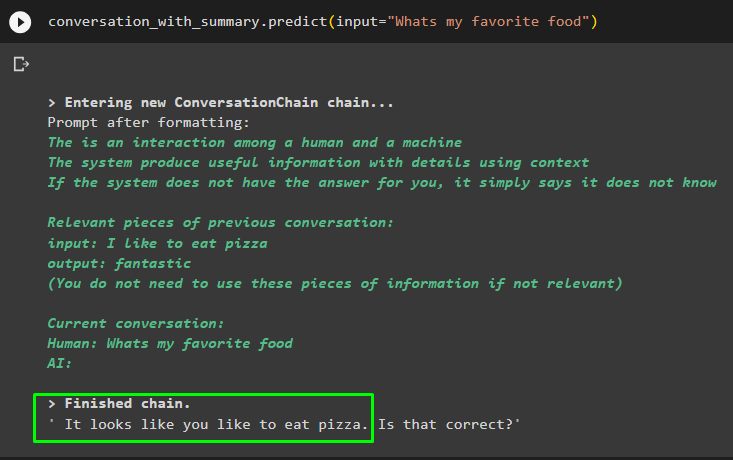
Holen Sie sich die Antwort, die dem Modell in einer der vorherigen Nachrichten bereitgestellt wurde, um zu überprüfen, wie der Memory Retriever mit dem Chat-Modell funktioniert:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = 'Was ist mein Name?' )Das Modell hat die Ausgabe mithilfe der Ähnlichkeitssuche aus den im Speicher abgelegten Daten korrekt angezeigt:
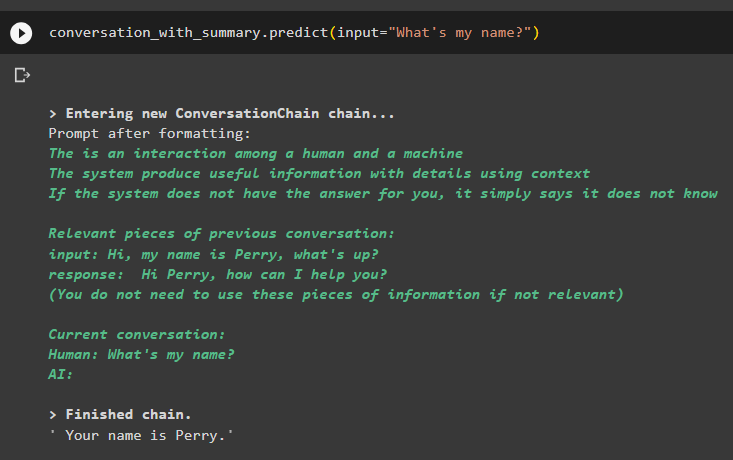
Hier dreht sich alles um die Verwendung des Vector Store Retriever in LangChain.
Abschluss
Um den auf einem Vektorspeicher basierenden Memory Retriever in LangChain zu nutzen, installieren Sie einfach die Module und Frameworks und richten Sie die Umgebung ein. Anschließend importieren Sie die Bibliotheken aus den Modulen, um die Datenbank mit Chroma zu erstellen, und legen dann die Eingabeaufforderungsvorlage fest. Testen Sie den Retriever nach dem Speichern der Daten im Speicher, indem Sie das Gespräch einleiten und Fragen zu den vorherigen Nachrichten stellen. In diesem Leitfaden wurde der Prozess der Verwendung der VectorStoreRetrieverMemory-Bibliothek in LangChain erläutert.