Kurzer Überblick
Dieser Beitrag enthält die folgenden Abschnitte:
- So verwenden Sie einen Async-API-Agenten in LangChain
- Methode 1: Verwenden der seriellen Ausführung
- Methode 2: Gleichzeitige Ausführung verwenden
- Abschluss
Wie verwende ich einen Async-API-Agenten in LangChain?
Chat-Modelle führen mehrere Aufgaben gleichzeitig aus, z. B. das Verstehen der Struktur der Eingabeaufforderung, ihrer Komplexität, das Extrahieren von Informationen und vieles mehr. Durch die Verwendung des Async-API-Agenten in LangChain kann der Benutzer effiziente Chat-Modelle erstellen, die mehrere Fragen gleichzeitig beantworten können. Um den Prozess der Verwendung des Async-API-Agenten in LangChain zu erlernen, folgen Sie einfach dieser Anleitung:
Schritt 1: Frameworks installieren
Installieren Sie zunächst das LangChain-Framework, um seine Abhängigkeiten vom Python-Paketmanager zu erhalten:
pip langchain installieren
Installieren Sie anschließend das OpenAI-Modul, um das Sprachmodell wie llm zu erstellen und seine Umgebung festzulegen:
pip openai installieren
Schritt 2: OpenAI-Umgebung
Der nächste Schritt nach der Installation der Module ist Einrichten der Umgebung Verwendung des API-Schlüssels von OpenAI und Serper-API So suchen Sie nach Daten von Google:
importieren Du
importieren getpass
Du . etwa [ „OPENAI_API_KEY“ ] = getpass . getpass ( „OpenAI-API-Schlüssel:“ )
Du . etwa [ „SERPER_API_KEY“ ] = getpass . getpass ( „Serper-API-Schlüssel:“ )
Schritt 3: Bibliotheken importieren
Nachdem die Umgebung nun eingerichtet ist, importieren Sie einfach die erforderlichen Bibliotheken wie Asyncio und andere Bibliotheken mithilfe der LangChain-Abhängigkeiten:
aus langchain. Agenten importieren initialize_agent , Load_toolsimportieren Zeit
importieren asynchron
aus langchain. Agenten importieren AgentType
aus langchain. lms importieren OpenAI
aus langchain. Rückrufe . stdout importieren StdOutCallbackHandler
aus langchain. Rückrufe . Tracer importieren LangChainTracer
aus aiohttp importieren ClientSession
Schritt 4: Fragen zur Einrichtung
Legen Sie einen Fragendatensatz fest, der mehrere Abfragen zu verschiedenen Domänen oder Themen enthält, die im Internet (Google) durchsucht werden können:
Fragen = [„Wer ist der Gewinner der U.S. Open-Meisterschaft 2021?“ ,
„Wie alt ist der Freund von Olivia Wilde?“ ,
„Wer ist der Gewinner des Formel-1-Weltmeistertitels?“ ,
„Wer hat das US Open-Frauenfinale 2021 gewonnen?“ ,
„Wer ist Beyoncés Ehemann und wie alt ist er?“ ,
]
Methode 1: Verwenden der seriellen Ausführung
Sobald alle Schritte abgeschlossen sind, führen Sie einfach die Fragen aus, um mithilfe der seriellen Ausführung alle Antworten zu erhalten. Das bedeutet, dass jeweils eine Frage ausgeführt/angezeigt wird und auch die vollständige Zeit zurückgegeben wird, die zum Ausführen dieser Fragen benötigt wird:
llm = OpenAI ( Temperatur = 0 )Werkzeuge = Load_tools ( [ „google-header“ , „llm-math“ ] , llm = llm )
Agent = initialize_agent (
Werkzeuge , llm , Agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , ausführlich = WAHR
)
S = Zeit . perf_counter ( )
#Zeitzähler konfigurieren, um die für den gesamten Prozess benötigte Zeit zu ermitteln
für Q In Fragen:
Agent. laufen ( Q )
verstrichen = Zeit . perf_counter ( ) - S
#drucken Sie die Gesamtzeit, die der Agent für die Beantwortung benötigt hat
drucken ( F „Seriell ausgeführt in {elapsed:0.2f} Sekunden.“ )
Ausgabe
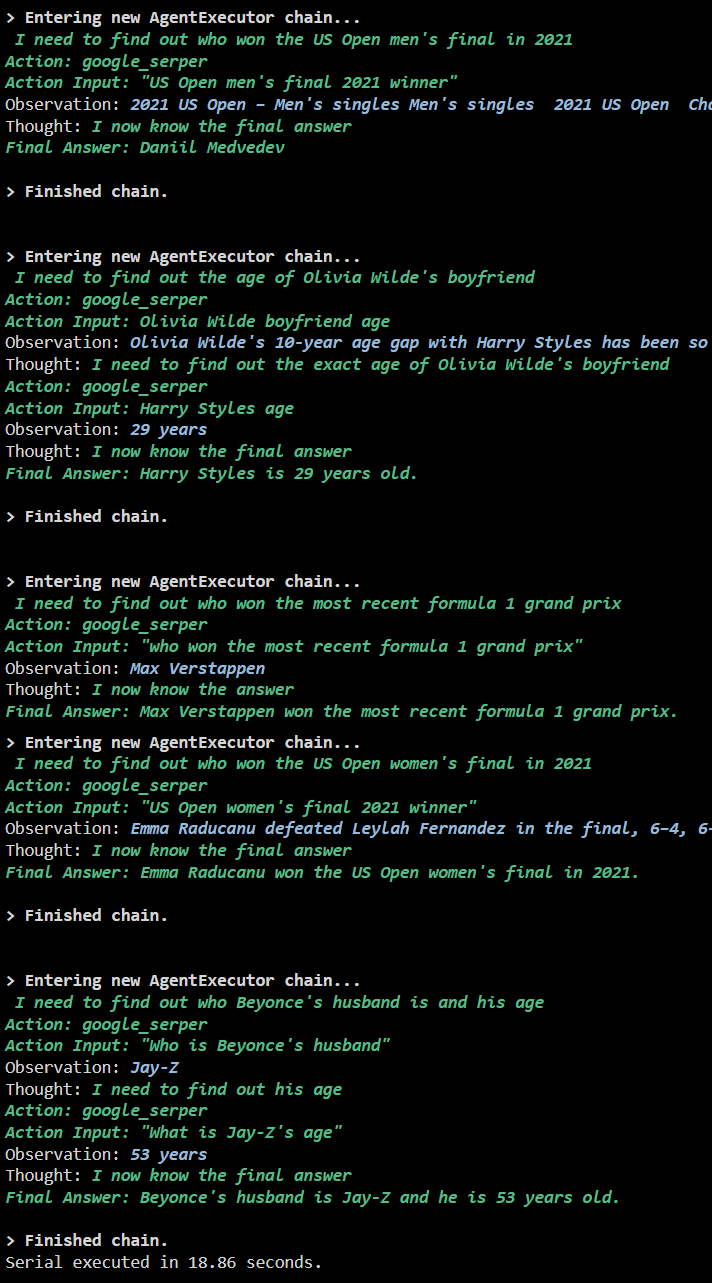
Der folgende Screenshot zeigt, dass jede Frage in einer separaten Kette beantwortet wird und sobald die erste Kette abgeschlossen ist, wird die zweite Kette aktiv. Die serielle Ausführung benötigt mehr Zeit, um alle Antworten einzeln zu erhalten:
Methode 2: Gleichzeitige Ausführung verwenden
Die gleichzeitige Ausführungsmethode nimmt alle Fragen entgegen und erhält ihre Antworten gleichzeitig.
llm = OpenAI ( Temperatur = 0 )Werkzeuge = Load_tools ( [ „google-header“ , „llm-math“ ] , llm = llm )
#Konfigurieren Sie den Agenten mithilfe der oben genannten Tools, um gleichzeitig Antworten zu erhalten
Agent = initialize_agent (
Werkzeuge , llm , Agent = AgentType. ZERO_SHOT_REACT_DESCRIPTION , ausführlich = WAHR
)
#Zeitzähler konfigurieren, um die für den gesamten Prozess benötigte Zeit zu ermitteln
S = Zeit . perf_counter ( )
Aufgaben = [ Agent. Krankheit ( Q ) für Q In Fragen ]
warte auf Asyncio. versammeln ( *Aufgaben )
verstrichen = Zeit . perf_counter ( ) - S
#drucken Sie die Gesamtzeit, die der Agent für die Beantwortung benötigt hat
drucken ( F „Gleichzeitige Ausführung in {elapsed:0.2f} Sekunden“ )
Ausgabe
Die gleichzeitige Ausführung extrahiert alle Daten gleichzeitig und nimmt viel weniger Zeit in Anspruch als die serielle Ausführung:
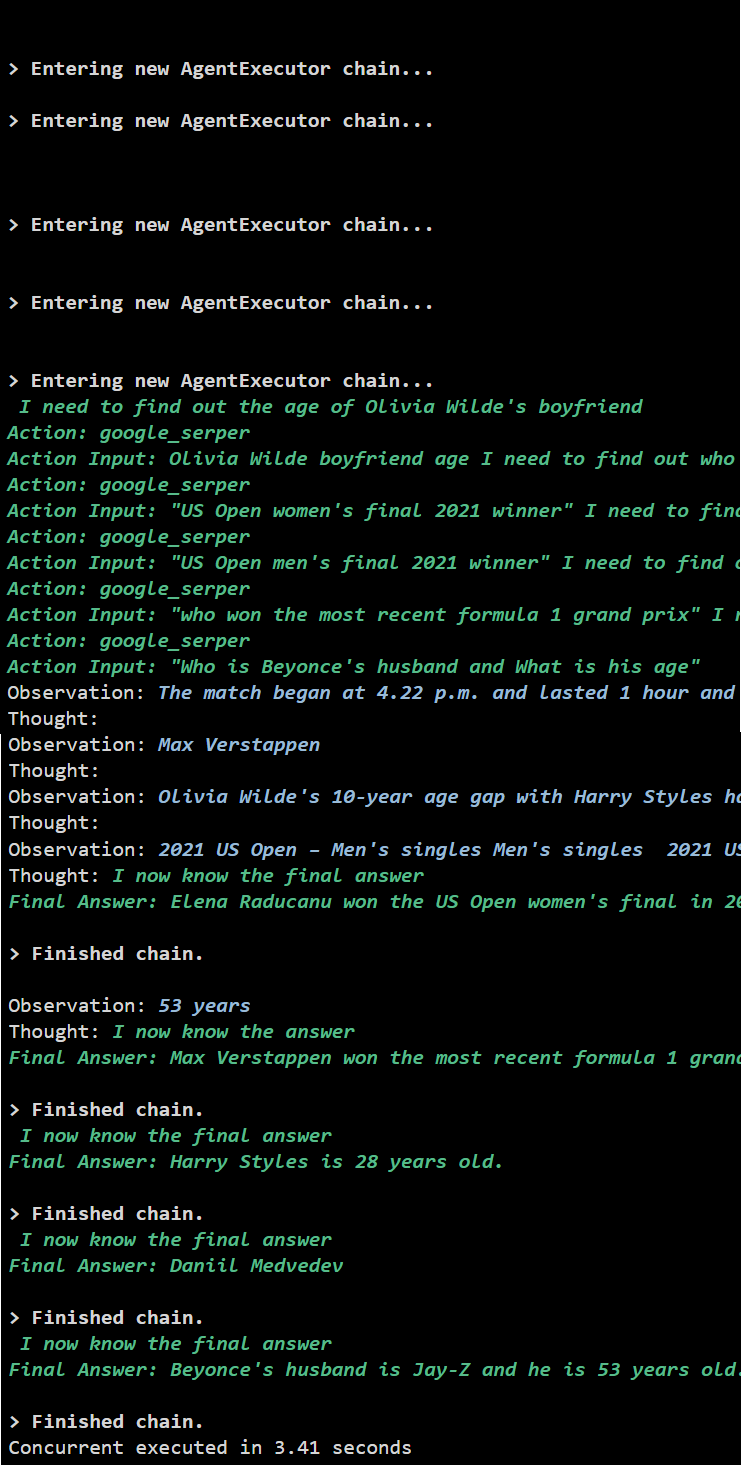
Dabei geht es um die Verwendung des Async-API-Agenten in LangChain.
Abschluss
Um den Async-API-Agenten in LangChain zu verwenden, installieren Sie einfach die Module, um die Bibliotheken aus ihren Abhängigkeiten zu importieren und die Asyncio-Bibliothek zu erhalten. Anschließend richten Sie die Umgebungen mithilfe der OpenAI- und Serper-API-Schlüssel ein, indem Sie sich bei ihren jeweiligen Konten anmelden. Konfigurieren Sie den Fragensatz zu verschiedenen Themen und führen Sie die Ketten nacheinander und gleichzeitig aus, um deren Ausführungszeit zu ermitteln. In diesem Leitfaden wurde der Prozess der Verwendung des Async-API-Agenten in LangChain erläutert.