In diesem Artikel besprechen wir die Zuweisung ANDERS Erinnerung über die „ pytorch_cuda_alloc_conf ' Methode.
Was ist die Methode „pytorch_cuda_alloc_conf“ in PyTorch?
Grundsätzlich gilt: „ pytorch_cuda_alloc_conf „ist eine Umgebungsvariable innerhalb des PyTorch-Frameworks. Diese Variable ermöglicht die effiziente Verwaltung der verfügbaren Verarbeitungsressourcen, was bedeutet, dass die Modelle in kürzester Zeit ausgeführt werden und Ergebnisse liefern. Wenn es nicht ordnungsgemäß durchgeführt wird, wird das „ ANDERS Die Berechnungsplattform zeigt Folgendes an: aus dem Gedächtnis ”Fehler und Auswirkungen auf die Laufzeit. Modelle, die über große Datenmengen trainiert werden sollen oder über große „ Losgrößen „kann zu Laufzeitfehlern führen, da die Standardeinstellungen für sie möglicherweise nicht ausreichen.
Der ' pytorch_cuda_alloc_conf „Variable verwendet Folgendes:“ Optionen ” um die Ressourcenzuweisung zu verwalten:
- einheimisch : Diese Option verwendet die bereits verfügbaren Einstellungen in PyTorch, um dem laufenden Modell Speicher zuzuweisen.
- max_split_size_mb : Es stellt sicher, dass Codeblöcke, die größer als die angegebene Größe sind, nicht aufgeteilt werden. Dies ist ein wirksames Instrument zur Vorbeugung von „ Zersplitterung “. Wir werden diese Option für die Demonstration in diesem Artikel verwenden.
- Roundup_power2_divisions : Diese Option rundet die Größe der Zuteilung auf das nächste „ Potenz von 2 ” Aufteilung in Megabyte (MB).
- Roundup_bypass_threshold_mb: Es kann die Zuteilungsgröße für jede Anfrage aufrunden, die mehr als den angegebenen Schwellenwert auflistet.
- trash_collection_threshold : Es verhindert Latenz, indem es den verfügbaren Speicher der GPU in Echtzeit nutzt, um sicherzustellen, dass das Reclaim-All-Protokoll nicht initiiert wird.
Wie ordne ich Speicher mit der Methode „pytorch_cuda_alloc_conf“ zu?
Jedes Modell mit einem großen Datensatz erfordert eine zusätzliche Speicherzuweisung, die größer ist als die standardmäßig festgelegte. Die benutzerdefinierte Zuweisung muss unter Berücksichtigung der Modellanforderungen und verfügbaren Hardwareressourcen festgelegt werden.
Befolgen Sie die unten aufgeführten Schritte, um „ pytorch_cuda_alloc_conf ”-Methode in der Google Colab-IDE, um einem komplexen Modell für maschinelles Lernen mehr Speicher zuzuweisen:
Schritt 1: Öffnen Sie Google Colab
Suchen Sie nach Google Kollaborativ im Browser und erstellen Sie ein „ Neues Notizbuch ” um mit der Arbeit zu beginnen:
Schritt 2: Richten Sie ein benutzerdefiniertes PyTorch-Modell ein
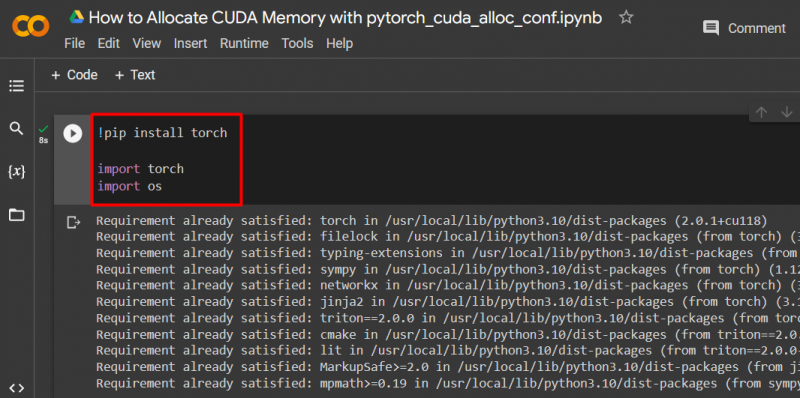
Richten Sie ein PyTorch-Modell ein, indem Sie „ !Pip ” Installationspaket zur Installation von „ Fackel ” Bibliothek und die „ importieren „Befehl zum Importieren“ Fackel ' Und ' Du ”Bibliotheken in das Projekt:
Taschenlampe importieren
Importieren Sie uns
Für dieses Projekt werden folgende Bibliotheken benötigt:
- Fackel – Dies ist die grundlegende Bibliothek, auf der PyTorch basiert.
- DU - Der ' Betriebssystem Die Bibliothek wird verwendet, um Aufgaben im Zusammenhang mit Umgebungsvariablen wie „ pytorch_cuda_alloc_conf ” sowie das Systemverzeichnis und die Dateiberechtigungen:
Schritt 3: CUDA-Speicher zuweisen
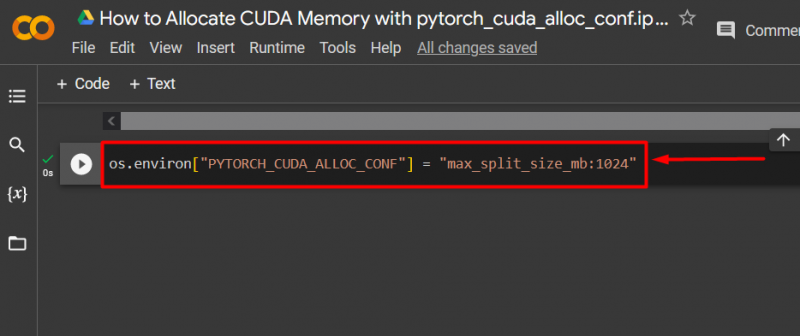
Benutzen Sie die „ pytorch_cuda_alloc_conf ”-Methode zum Festlegen der maximalen Teilungsgröße mithilfe von „ max_split_size_mb ”:
Schritt 4: Fahren Sie mit Ihrem PyTorch-Projekt fort
Nach der Angabe „ ANDERS ” Raumzuteilung mit dem „ max_split_size_mb ” Option, arbeiten Sie wie gewohnt am PyTorch-Projekt weiter, ohne Angst vor dem „ aus dem Gedächtnis ' Fehler.
Notiz : Hier können Sie auf unser Google Colab-Notizbuch zugreifen Verknüpfung .
Profi-Tipp
Wie bereits erwähnt, ist die „ pytorch_cuda_alloc_conf Die Methode kann jede der oben angegebenen Optionen annehmen. Nutzen Sie sie entsprechend den spezifischen Anforderungen Ihrer Deep-Learning-Projekte.
Erfolg! Wir haben gerade gezeigt, wie man das „ pytorch_cuda_alloc_conf ”-Methode zur Angabe eines „ max_split_size_mb ” für ein PyTorch-Projekt.
Abschluss
Benutzen Sie die „ pytorch_cuda_alloc_conf ”-Methode zum Zuweisen von CUDA-Speicher unter Verwendung einer der verfügbaren Optionen gemäß den Anforderungen des Modells. Diese Optionen sollen jeweils ein bestimmtes Verarbeitungsproblem in PyTorch-Projekten lindern und so zu besseren Laufzeiten und reibungsloseren Abläufen führen. In diesem Artikel haben wir die Syntax zur Verwendung des „ max_split_size_mb ” Option zum Definieren der maximalen Größe der Aufteilung.