In dieser Anleitung wird erläutert, wie Sie Crawler erstellen, um Daten aus dem S3-Bucket abzurufen.
Wie erstelle ich einen Crawler zum Abrufen von Daten aus dem S3-Bucket?
Um einen Crawler in AWS zu erstellen, besuchen Sie die Seite „ AWS-Kleber ”-Service aus dem Amazon-Dashboard:
Klick auf das ' Datenbanken Klicken Sie auf die Schaltfläche „Datenkatalog“, um eine Datenbank zu erstellen:
Klick auf das ' Datenbank hinzufügen ”-Taste, um die Konfiguration zu starten:
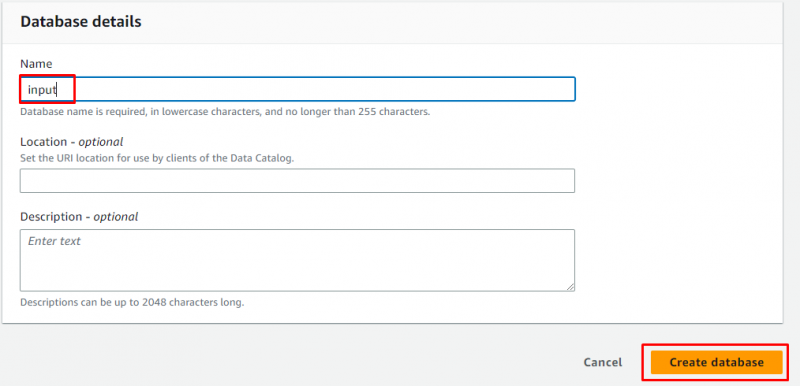
Geben Sie den Namen der Datenbank ein und lassen Sie alles optional, bevor Sie auf „ Datenbank erstellen ' Taste:
Die Datenbank wurde erfolgreich erstellt:
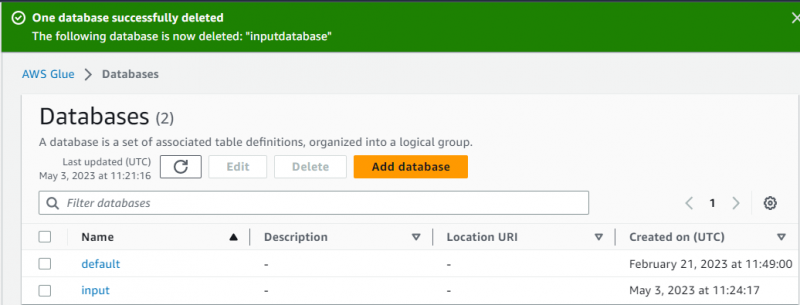
Danach gehen Sie einfach zu „ Crawler ”-Seite, indem Sie im linken Bereich darauf klicken:
Klick auf das ' Crawler erstellen ' Taste:

Geben Sie den Namen des Crawlers ein und klicken Sie auf „ Nächste ' Taste:

Klick auf das ' Fügen Sie eine Datenquelle hinzu ”-Taste, um die Quelle der Daten auszuwählen:
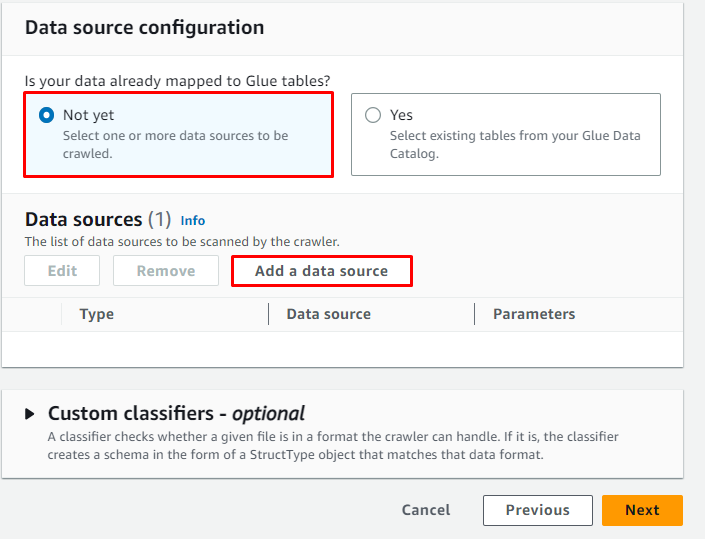
Um den Pfad zu überprüfen, in dem die Daten gespeichert sind, besuchen Sie den S3-Dienst:
Gehen Sie in den S3-Bucket, in den die Daten hochgeladen werden. Der Benutzer kann erstellen ein Eimer und hochladen Daten dazu aus dem AWS S3-Dashboard:

Klick auf das ' Durchsuchen Sie S3 ”-Taste, um den Pfad der Daten auszuwählen:
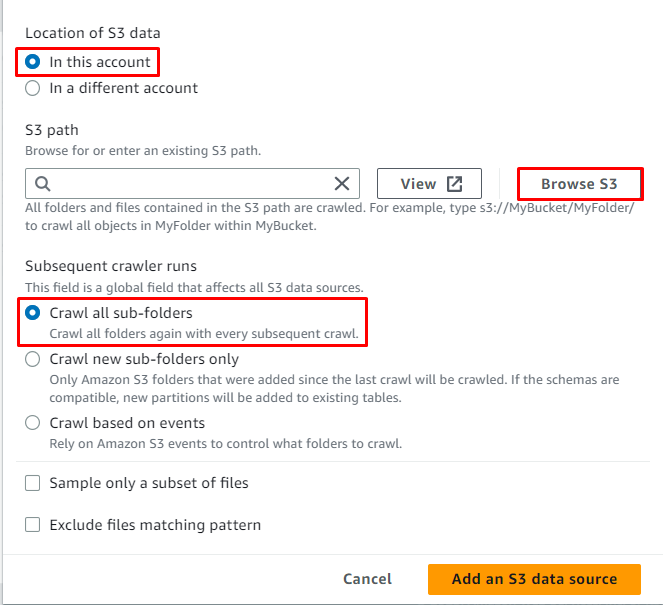
Wählen Sie den Ordner mit den Daten aus und klicken Sie dann auf „ Wählen ' Taste:

Der S3-Pfad wurde ausgewählt, klicken Sie nun auf „ Fügen Sie eine S3-Datenquelle hinzu ' Taste:

Sobald die Datenquelle hinzugefügt wurde, klicken Sie einfach auf „ Nächste ' Taste:
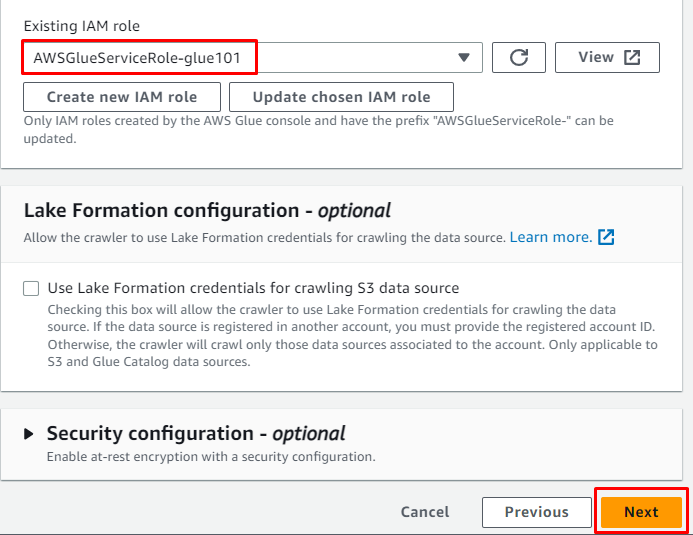
Fügen Sie die IAM-Rolle hinzu und klicken Sie dann auf „ Nächste ' Taste:
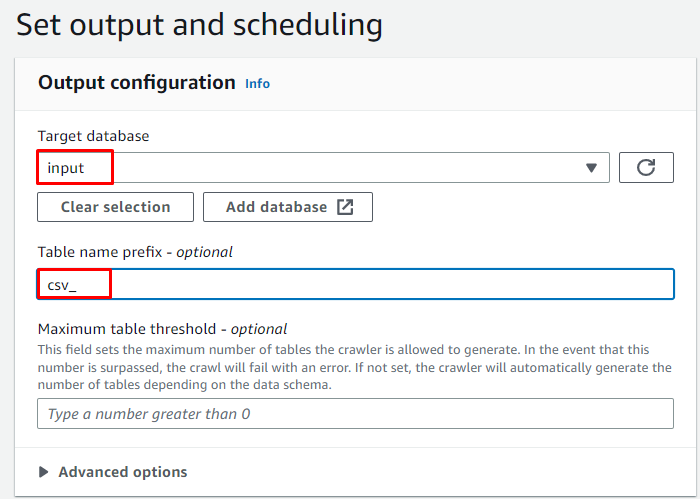
Geben Sie die zuvor erstellte Zieldatenbank ein und geben Sie dann den Namen für die Tabelle ein:
Wählen Sie den On-Demand-Zeitplan für den Crawler aus und klicken Sie auf „ Nächste ' Taste:
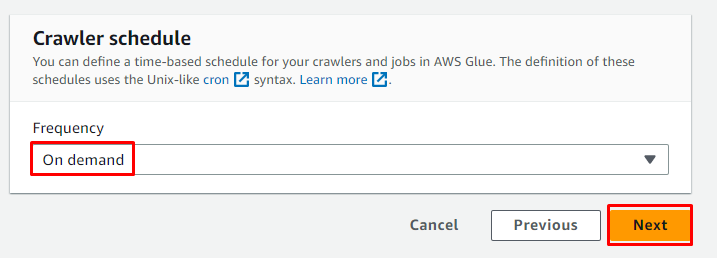
Überprüfen Sie den Crawler und klicken Sie auf „ Crawler erstellen ' Taste:
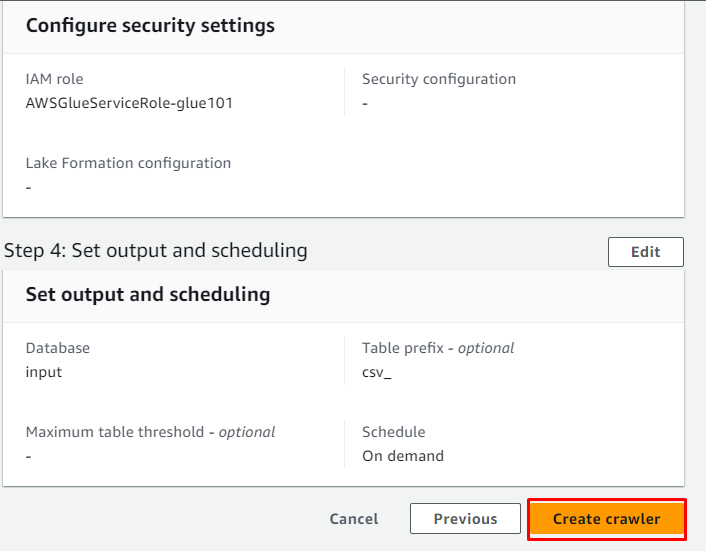
Der Crawler wurde erfolgreich erstellt, klicken Sie auf „ Laufen ”-Taste nach Auswahl:

Die Ausführung des Crawlers dauert einige Augenblicke. Er ruft Daten ab und erstellt eine Tabelle zum Speichern der Daten:
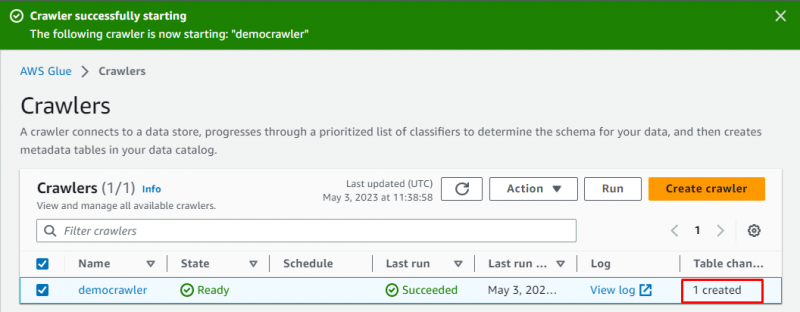
Gehen Sie in die „ Tische ”Seite aus dem Glue-Dashboard:
Wählen Sie die Tabelle aus, indem Sie auf ihren Namen klicken:
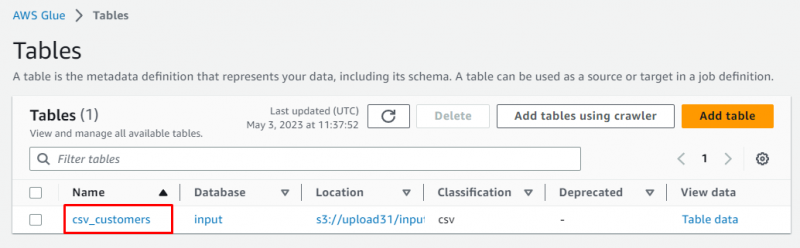
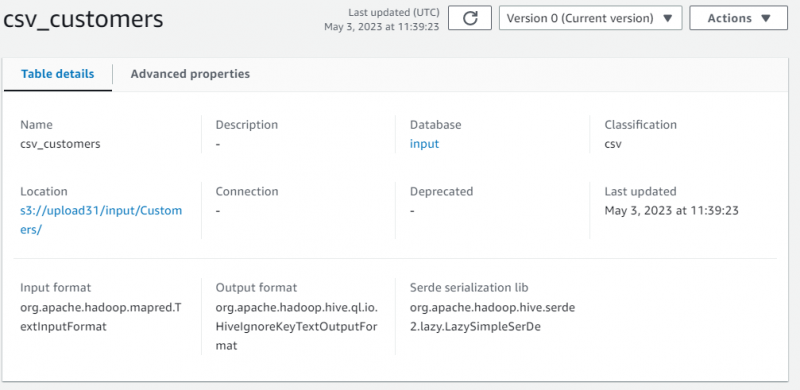
Die Tale-Details wurden mit den Metadaten der abgerufenen Daten angezeigt:
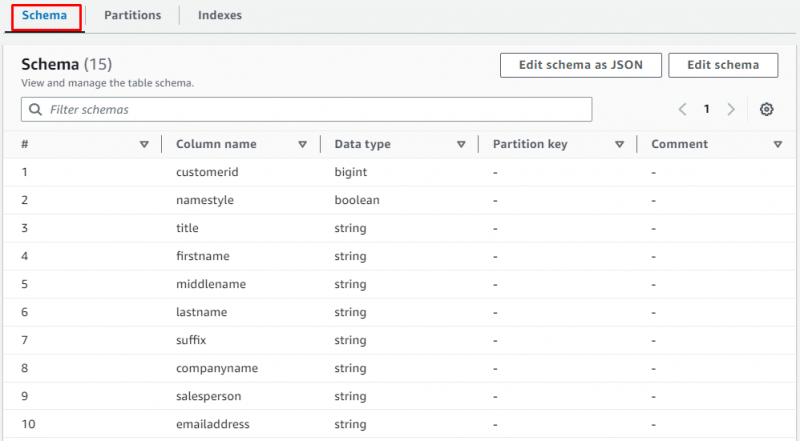
Scrollen Sie auf der Seite nach unten und wählen Sie den Abschnitt aus, um die Tabelle mit den Daten anzuzeigen:
Dabei geht es darum, einen Crawler zu erstellen, um Daten aus dem S3-Bucket abzurufen.
Abschluss
Um einen Crawler zum Abrufen von Daten aus dem S3-Bucket zu erstellen, erstellen Sie eine Datenbank auf AWS Glue, in der die gecrawlten Daten gespeichert werden. Konfigurieren Sie den Crawler über das Glue-Dashboard, indem Sie die Datenquelle (S3-Bucket) und die Zieldatenbank angeben. Führen Sie den Crawler aus und rufen Sie die Daten aus dem S3-Bucket in die Datenbanktabelle ab, wie in dieser Anleitung ausführlich erläutert.