In diesem Leitfaden werden Listencrawler in AWS erläutert.
Was sind List-Crawler in AWS?
Ein Crawler ist eine Komponente von AWS Glue, die zum Crawlen des Datenspeicherorts verwendet wird und diese Informationen zurück in den Katalog leitet. Bei den Informationen, die ein Crawler sammelt, kann es sich um Datentypen der Daten oder eine Schemastruktur handeln. Mit anderen Worten: Er sammelt Metadaten. Crawler kann auch mit dem Datenkatalog verwendet werden, der verwendet wird, wenn die Daten innerhalb des Glue-Ökosystems verschoben werden, während ETL-Jobs usw. verwendet werden.
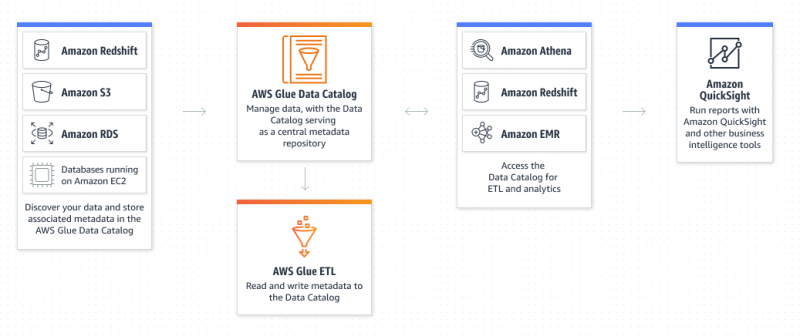
Was ist der Amazon Glue Service?
AWS Glue ist ein Amazon Extract Transform and Load-Dienst, der es dem Benutzer ermöglicht, alle Daten zu organisieren, zu lokalisieren, zu verschieben und zu transformieren. AWS Glue ist serverlos, da der Benutzer weder Server bereitstellen und konfigurieren noch Lebenszyklen verwalten muss. Datenkatalog und Crawler sind die Komponenten von AWS Glue, der als persistentes Metadaten-Repository fungiert:

Wie erstelle ich einen Crawler auf AWS?
Um einen Crawler auf AWS zu erstellen, besuchen Sie den AWS Glue-Service über die AWS-Managementkonsole:
Gehen Sie in die „ Crawler ”-Seite, indem Sie im linken Bereich auf den Namen klicken:
Klick auf das ' Crawler erstellen ' Taste:
Geben Sie den Namen des Crawlers ein und klicken Sie auf „ Nächste ' Taste:
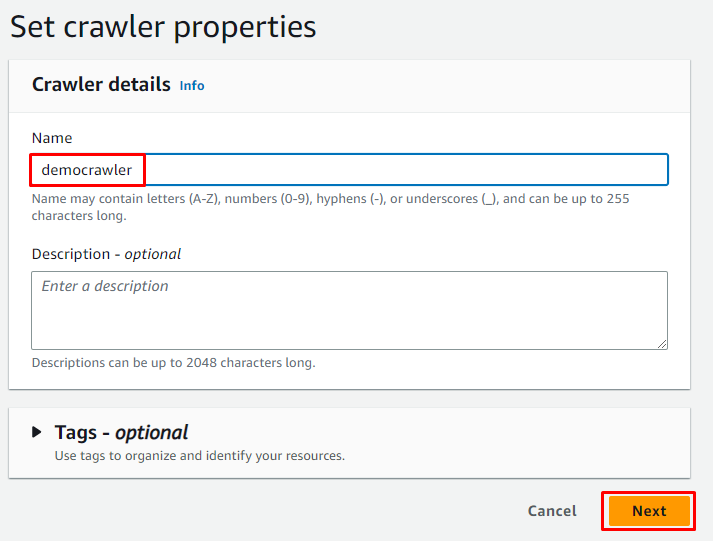
Wählen Sie die Zuordnungsoption für Klebetabellen und klicken Sie auf „ Fügen Sie eine Quelle hinzu ”-Taste, um Daten abzurufen von:

Wählen Sie den S3-Dienst aus und klicken Sie auf „ Durchsuchen Sie S3 ”-Taste, um den Standort der Quelle zu ermitteln:

Wählen Sie einfach den S3-Ordner aus und klicken Sie auf „ Wählen ' Taste:

Sobald der Standort zur Quelle hinzugefügt wurde, klicken Sie einfach auf „ Fügen Sie eine S3-Datenquelle hinzu ' Taste:
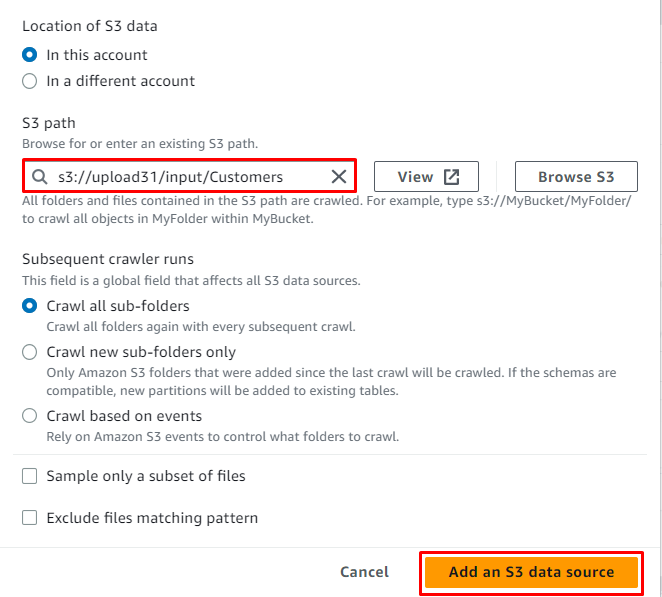
Klick auf das ' Nächste ' Taste:

Klick auf das ' Erstellen Sie eine neue IAM-Rolle ”-Taste aus dem „ Konfigurieren Sie Sicherheitseinstellungen ' Abschnitt:
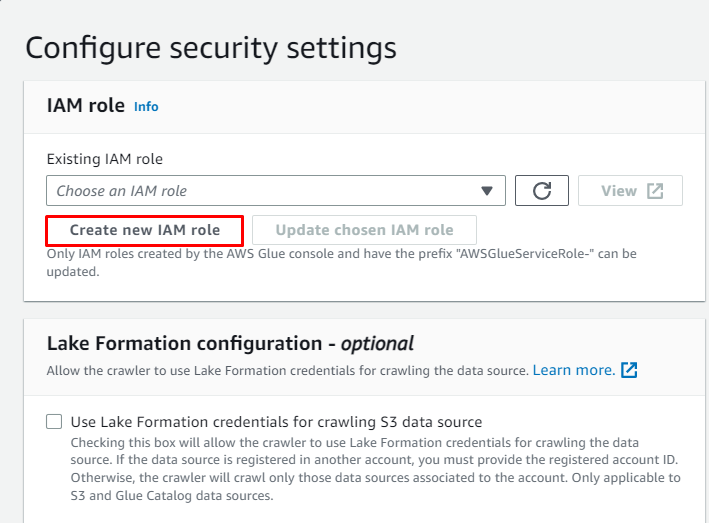
Geben Sie den Namen der Rolle ein und klicken Sie auf „ Erstellen ' Taste:
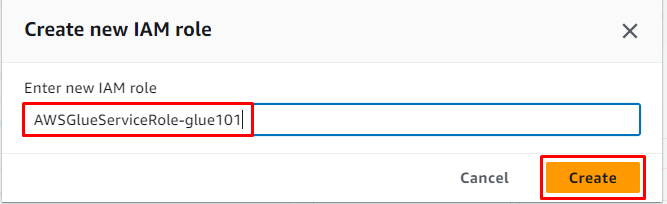
Klicken Sie anschließend einfach auf „ Nächste ' Taste:

Wählen Sie die Zieldatenbank aus und geben Sie den Namen ein, der für die Tabelle verwendet werden soll:
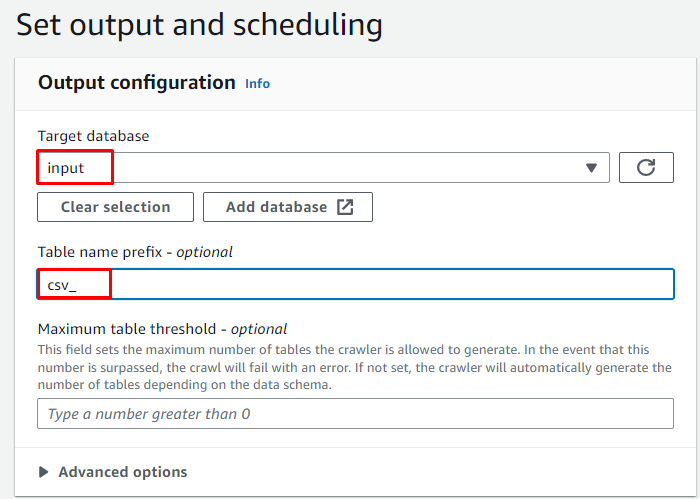
Planen Sie den Crawler für „ Auf Anfrage “ und klicken Sie auf „ Nächste ' Taste:
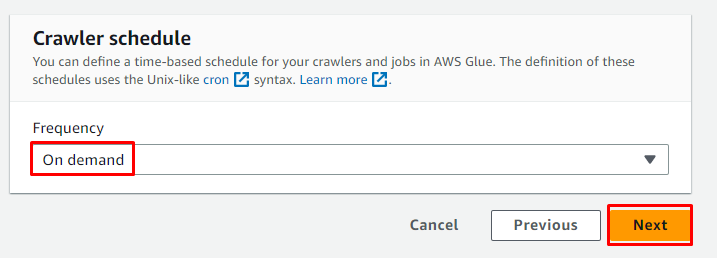
Überprüfen Sie die Konfiguration und klicken Sie auf „ Crawler erstellen ' Taste:
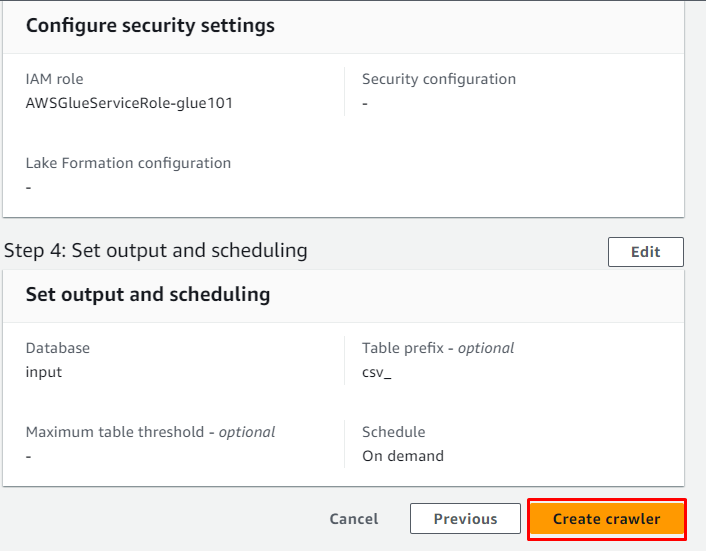
Der Crawler wurde erfolgreich erstellt und kann zum Abrufen der Daten aus der Quelle verwendet werden, indem Sie auf „ Laufen ' Taste:

Das ist alles über die Listencrawler in AWS.
Abschluss
ListCrawler ist die Komponente des AWS Glue-Dienstes, mit der Informationen aus Quellen gecrawlt und zum Katalog zurückgeleitet werden können. Datenkataloge und Crawler können zum Sammeln von Daten verwendet werden, um Informationen über die Daten zu erhalten, die als Metadaten bezeichnet werden. Der Benutzer kann auch einen Crawler aus AWS Glue erstellen, um Daten vom S3-Dienst oder anderen Quellen abzurufen und Erstellungstabellen in der Datenbank zu platzieren. In diesem Leitfaden wurden die ListCrawler in AWS und deren Erstellung erläutert.