Daten werden täglich in großen Mengen gesammelt und die Verwaltung großer Datenmengen ist der wichtigste Anwendungsfall der Elasticsearch-Engine. Die Daten werden in Echtzeit in der Analysedatenbank gespeichert und der Benutzer kann Daten extrahieren, um mithilfe von Abfragen nützliches Wissen daraus zu finden. Der Benutzer kann Abfragen anwenden, um Daten aus mehreren Indizes zu finden und sie in einem einzigen Bucket aus der relationalen Datenbank anzuzeigen.
In diesem Leitfaden werden die Elasticsearch-Aggregationen anhand von Beispielen erläutert, die verschiedene Aggregationen verwenden.
Was ist Elasticsearch-Aggregation?
In Elasticsearch ist Aggregation der Prozess der Kombination oder Gruppierung der Felder, um Informationen aus der relationalen Datenbank zu extrahieren. Die Aggregation in Elasticsearch kann als betrachtet werden GRUPPE NACH KLAUSEL oder AGGREGAT() Funktion in der SQL-Sprache.
Wie verwende ich die Elasticsearch-Aggregation?
Um die Aggregation in Elasticsearch nutzen zu können, muss der Benutzer über grundlegende Kenntnisse seiner Datenbank verfügen. Lassen Sie uns die Syntax und ihre praktische Umsetzung untersuchen:
Syntax
Um Daten aus der Datenbank zu finden, verwenden Sie die Syntax der Aggregation in der Elasticsearch-Engine wie folgt:
„aggs“ : {„name_of_aggregation“ : {
„type_of_aggregation“ : {
'Feld' : „document_field_name“
}
Die obigen Ausschnitte:
-
- Es verwendet das „ aggs ”-Schlüsselwort, das die Verwendung der Aggregation in der Abfrage erklärt.
- Der name_of_aggregation wird vom Benutzer entsprechend den erforderlichen Informationen eingestellt.
- Danach wird die type_of_aggregation wird zum Abrufen von Daten verwendet.
- Die letzte Zeile verwendet die Feld Schlüsselwort, dem der Name des Attributs aus dem Dokument folgt.
Beispiel 1: Aggregation in Kibana-Beispieldaten
In diesem Abschnitt wird die Aggregation anhand eines Beispiels anhand der Beispieldaten von Kibana erläutert, indem zunächst eine Verbindung hergestellt wird. Gehen Sie danach einfach in das „ Entwicklungstools ” indem Sie es in der Suchleiste suchen und darauf klicken:
Daten aus Beispieldaten abrufen
Verwenden Sie einfach den folgenden Befehl, um die Daten aus dem „ kibana_sample_data_logs ” Index auf der Dev Tools-Konsole:
ERHALTEN / kibana_sample_data_logs / _suchen
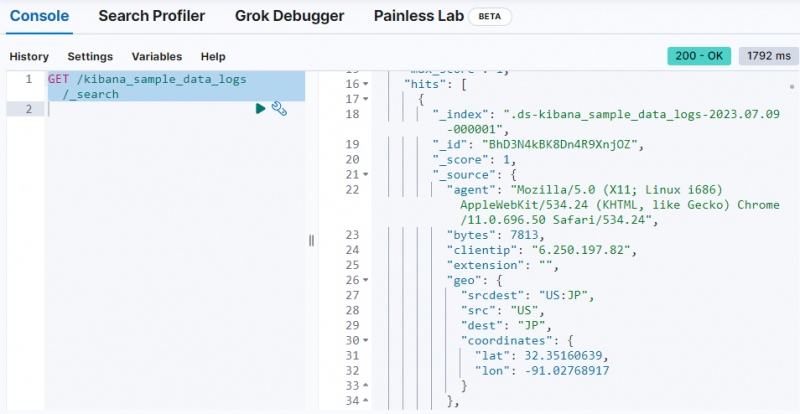
Die Ausgabe zeigt, dass Daten von der „ kibana_sample_data_logs ' Index.
Der folgende Code verwendet a ERHALTEN Anfrage zum „ kibana_sample_data_log ”, um daraus mithilfe der value_count-Aggregation auf der Seite „ zu suchen clientip ' Feld:
ERHALTEN / kibana_sample_data_logs / _suchen{ 'Größe' : 0 ,
„aggs“ : {
„ip_count“ : {
„value_count“ : {
'Feld' : „Kundentipp“
}
}
}
}
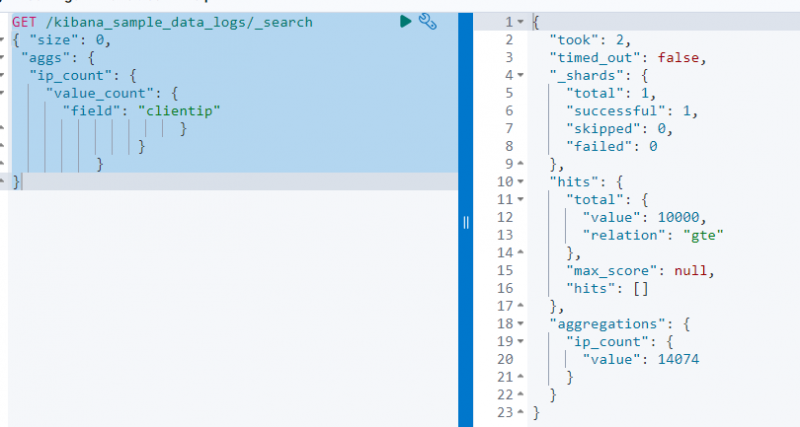
Der obige Screenshot zeigt die Aggregation auf der clientip Feld mit dem Wert 14074 .
Wichtige Aggregationen
Einige der wichtigen Aggregationen, die zum effizienten Auffinden von Daten aus der Datenbank verwendet werden, sind nachstehend aufgeführt:
Die folgenden Beispiele erläutern die oben genannten Aggregationen anhand der ERHALTEN Anfrage der „ kibana_sample_data_ecommerce ' Index:
Kardinalitätsaggregation
Der folgende Code verwendet das „ Kardinalität Aggregation auf der „ SKU ”-Feld aus den E-Commerce-Daten. Wenn Sie diesen Code ausführen, wird eine Einzelwertaggregation durchgeführt, um die eindeutigen SKUs aus der Elasticsearch-Datenbank abzurufen:
ERHALTEN / kibana_sample_data_ecommerce / _suchen{
'Größe' : 0 ,
„aggs“ : {
„unique_skus“ : {
„Kardinalität“ : {
'Feld' : „sku“
}
}
}
}
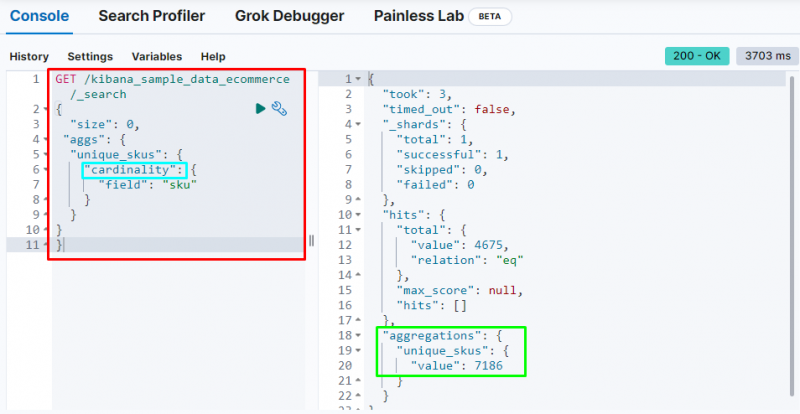
Es zeigt die Kardinalität Aggregation Finden der 7186 Werte aus dem Index.
Statistikaggregation
Eine weitere wichtige Aggregation ist die „ Statistiken Aggregation, die verwendet wird, um die „ zählen “, „ Mindest “, „ max “, „ Durchschn ', Und ' Summe ” Statistiken aus dem „ Gesamtmenge ' Feld:
ERHALTEN / kibana_sample_data_ecommerce / _suchen{
'Größe' : 0 ,
„aggs“ : {
„quantity_stats“ : {
'Statistiken' : {
'Feld' : 'Gesamtmenge'
}
}
}
}
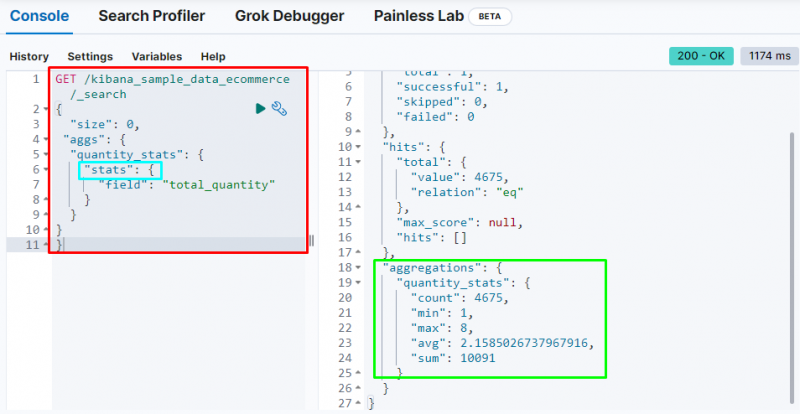
Der obige Screenshot zeigt die Statistiken in der Ausgabe von „ Gesamtmenge ' Feld.
Filteraggregation
Die Filteraggregation wird verwendet, um Daten basierend auf einem Begriff oder einer Phrase aus der Datenbank herauszufiltern, wie sie im folgenden Code enthalten ist:
ERHALTEN / kibana_sample_data_ecommerce / _suchen{ 'Größe' : 0 ,
„aggs“ : {
„filter_aggregation“ : {
'Filter' : {
'Begriff' : {
'Benutzer' : „Eddie“ } } ,
„aggs“ : {
„price_avg“ : {
„Durchschnitt“ : {
'Feld' : „Produkte.Preis“ } }
} } } }
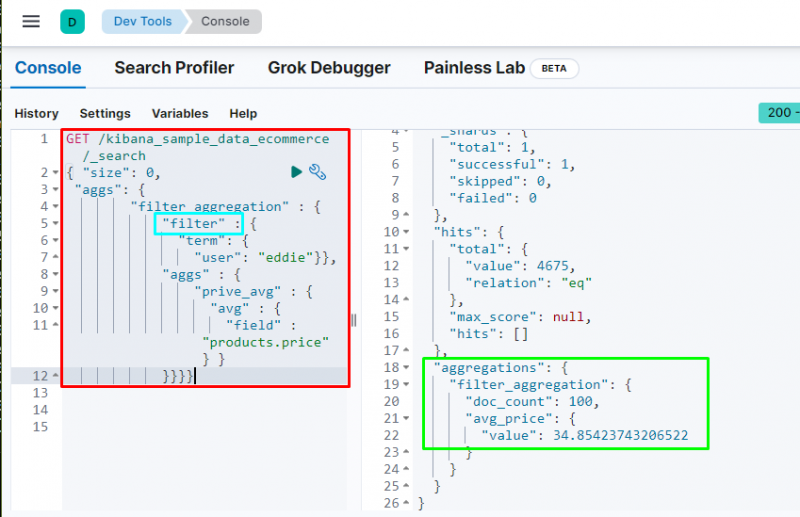
Durch die Ausführung des Codes werden die Daten basierend auf „ Eddie ”Benutzer und zeigt den Durchschnittspreis der gekauften Artikel an. Der obige Screenshot zeigt, dass die Benutzer hat gefunden 100 Zeiten aus den Daten und der Wert des Durchschn _ Preis Anhäufung.
Termaggregation
Der Begriff Aggregation erstellt einen Bucket und speichert Daten aus dem Feld im Bucket und der folgende Code verwendet das „ Benutzer ”-Feld, um seine Daten im Bucket zu speichern:
ERHALTEN / kibana_sample_data_ecommerce / _suchen{
'Größe' : 0 ,
„aggs“ : {
„Term_Aggregation“ : {
'Bedingungen' : {
'Feld' : 'Benutzer'
}
}
}
}
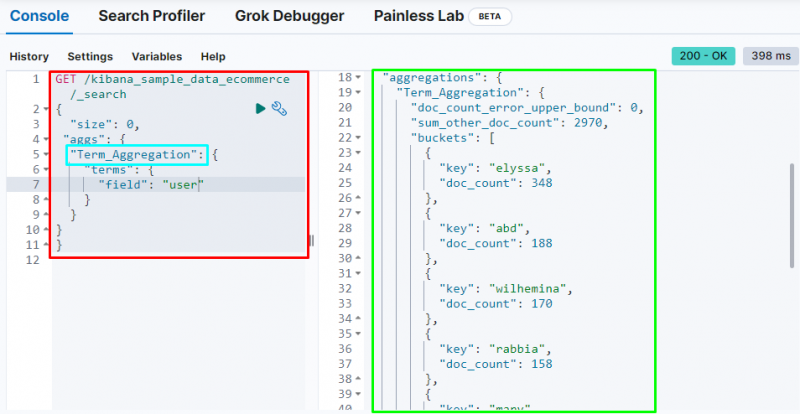
Der folgende Screenshot zeigt, dass die Begriffsaggregation Buckets für jeden Benutzer und seine Dokumentanzahl erstellt hat.
Hier dreht sich alles um die Elasticsearch-Aggregation und andere wichtige Aggregationen.
Abschluss
In Elasticsearch wird die Aggregation verwendet, um Daten aus den aggregierten Dokumenten abzurufen und diese Dokumente aus einem bestimmten Feld zu extrahieren. Es werden einige wichtige Aggregationen erläutert, die verwendet werden, um nützliche Erkenntnisse aus den Indizes zu gewinnen. In diesem Leitfaden wurde die Elasticsearch-Aggregation erläutert und der Prozess der Verwendung der Elasticsearch-Aggregation demonstriert.