Der Datenvergleich in SQL ist eine häufige Aufgabe, mit der jeder Datenbankentwickler gelegentlich konfrontiert wird. Glücklicherweise gibt es den Datenvergleich in einer Vielzahl von Formaten, z. B. als Literalvergleich, Boolescher Vergleich usw.
Eines der realen Datenvergleichsszenarien, denen Sie begegnen könnten, ist jedoch der Vergleich zwischen zwei Tabellen. Es spielt eine entscheidende Rolle bei Aufgaben wie Datenvalidierung, Fehlererkennung, Duplizierung oder Gewährleistung der Datenintegrität.
In diesem Tutorial werden wir alle verschiedenen Methoden und Techniken erkunden, die wir zum Vergleichen zweier Datenbanktabellen in SQL verwenden können.
Beispieldaten-Setup
Bevor wir uns mit den einzelnen Methoden befassen, richten wir zu Demonstrationszwecken ein grundlegendes Daten-Setup ein.
Wir haben zwei Tabellen mit Beispieldaten, wie im Beispiel gezeigt.
Beispieltabelle 1:
Im Folgenden finden Sie die Abfragen zum Erstellen der ersten Tabelle und zum Einfügen der Beispieldaten in die Tabelle:
TABELLE sample_tb1 ERSTELLEN (
Employee_id INT PRIMARY KEY AUTO_INCREMENT,
Vorname VARCHAR ( fünfzig ) ,
Nachname VARCHAR ( fünfzig ) ,
Abteilung VARCHAR ( fünfzig ) ,
Gehalt DEZIMAL ( 10 , 2 )
) ;
IN sample_tb1 EINFÜGEN ( Vorname, Nachname, Abteilung, Gehalt )
WERTE
( „Penelope“ , 'Verfolgungsjagd' , „HR“ , 55000,00 ) ,
( 'Matthew' , 'Käfig' , 'ES' , 60000,00 ) ,
( „Jeniffer“ , 'Davis' , 'Finanzen' , 50000,00 ) ,
( „Kirsten“ , 'Fawcet' , 'ES' , 62000,00 ) ,
( „Cameron“ , 'Kosten' , 'Finanzen' , 48000,00 ) ;
Dadurch sollte eine neue Tabelle namens „sample_tb1“ mit verschiedenen Informationen wie Namen, Abteilung und Gehalt erstellt werden.
Die resultierende Tabelle sieht wie folgt aus:

Beispieltabelle 2:
Lassen Sie uns fortfahren und zwei Beispieltabellen erstellen. Gehen Sie davon aus, dass es sich hierbei um eine Sicherungskopie der ersten Tabelle handelt. Wir können die Tabelle erstellen und Beispieldaten einfügen, wie im Folgenden gezeigt:
TABELLE sample_tb2 ERSTELLEN (Employee_id INT PRIMARY KEY AUTO_INCREMENT,
Vorname VARCHAR ( fünfzig ) ,
Nachname VARCHAR ( fünfzig ) ,
Abteilung VARCHAR ( fünfzig ) ,
Gehalt DEZIMAL ( 10 , 2 )
) ;
IN sample_tb2 EINFÜGEN ( Vorname, Nachname, Abteilung, Gehalt )
WERTE
( „Penelope“ , 'Verfolgungsjagd' , „HR“ , 55000,00 ) ,
( 'Matthew' , 'Käfig' , 'ES' , 60000,00 ) ,
( „Jeniffer“ , 'Davis' , 'Finanzen' , 50000,00 ) ,
( „Kirsten“ , 'Fawcet' , 'ES' , 62000,00 ) ,
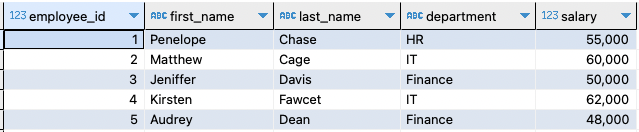
( „Audrey“ , 'Dean' , 'Finanzen' , 48000,00 ) ;
Dadurch sollte eine Tabelle erstellt und die Beispieldaten wie in der vorherigen Abfrage angegeben eingefügt werden. Die resultierende Tabelle sieht wie folgt aus:
Vergleichen Sie zwei Tabellen mit Except
Eine der gebräuchlichsten Methoden zum Vergleichen zweier Tabellen in SQL ist die Verwendung des EXCEPT-Operators. Dadurch werden die Zeilen gefunden, die in der ersten Tabelle, aber nicht in der zweiten Tabelle vorhanden sind.
Wir können damit einen Vergleich mit den Beispieltabellen wie folgt durchführen:
WÄHLEN *VON sample_tb1
AUSSER
WÄHLEN *
FROM sample_tb2;
In diesem Beispiel gibt der EXCEPT-Operator alle unterschiedlichen Zeilen aus der ersten Abfrage (sample_tb1) zurück, die in der zweiten Abfrage (sample_tb2) nicht erscheinen.
Vergleichen Sie zwei Tabellen mit Union
Die zweite Methode, die wir verwenden können, ist der UNION-Operator in Verbindung mit der GROUP BY-Klausel. Dies hilft dabei, die Datensätze zu identifizieren, die in einer Tabelle vorhanden sind, in der anderen jedoch nicht, und gleichzeitig die doppelten Datensätze beizubehalten.
Nehmen Sie die im Folgenden gezeigte Abfrage:
WÄHLENAngestellten ID,
Vorname,
Familienname, Nachname,
Abteilung,
Gehalt
AUS
(
WÄHLEN
Angestellten ID,
Vorname,
Familienname, Nachname,
Abteilung,
Gehalt
AUS
sample_tb1
UNION ALLE
WÄHLEN
Angestellten ID,
Vorname,
Familienname, Nachname,
Abteilung,
Gehalt
AUS
sample_tb2
) AS Combined_Data
GRUPPIERE NACH
Angestellten ID,
Vorname,
Familienname, Nachname,
Abteilung,
Gehalt
HABEN
ZÄHLEN ( * ) = 1 ;
Im gegebenen Beispiel verwenden wir den UNION ALL-Operator, um die Daten aus beiden Tabellen zu kombinieren und gleichzeitig die Duplikate beizubehalten.
Anschließend verwenden wir die GROUP BY-Klausel, um die kombinierten Daten nach allen Spalten zu gruppieren. Schließlich verwenden wir die HAVING-Klausel, um sicherzustellen, dass nur die Datensätze mit einer Anzahl von eins (keine Duplikate) ausgewählt werden.
Ausgabe:

Diese Methode ist etwas komplexer, bietet jedoch einen viel besseren Einblick, da Sie die tatsächlichen Daten erhalten, die in beiden Tabellen fehlen.
Vergleichen Sie zwei Tabellen mit INNER JOIN
Wenn Sie darüber nachgedacht haben, warum nicht einen INNER JOIN verwenden? Du wärst auf dem Punkt. Wir können einen INNER JOIN verwenden, um die Tabellen zu vergleichen und die gemeinsamen Datensätze zu finden.
Nehmen Sie zum Beispiel die folgende Abfrage:
WÄHLENsample_tb1. *
AUS
sample_tb1
INNER JOIN sample_tb2 EIN
sample_tb1.employee_id = sample_tb2.employee_id;
In diesem Beispiel verwenden wir einen SQL INNER JOIN, um die Datensätze zu finden, die in beiden Tabellen basierend auf einer bestimmten Spalte vorhanden sind. Obwohl dies funktioniert, kann es manchmal irreführend sein, da Sie nicht sicher sind, ob die Daten tatsächlich fehlen oder in beiden Tabellen oder nur in einer vorhanden sind.
Abschluss
In diesem Tutorial haben wir alle Methoden und Techniken kennengelernt, die wir zum Vergleichen zweier Tabellen in SQL verwenden können.