Bei der Arbeit in der Befehlszeilenumgebung ist es wichtig, die verschiedenen verfügbaren Befehle zu verstehen, um Dateien, Verzeichnisse und andere Daten effektiv zu verwalten. Ein solcher Befehl ist der „awk“-Befehl. awk ist ein leistungsstarkes Dienstprogramm zum Verarbeiten und Manipulieren von Textdateien in der Unix/Linux-Umgebung. Dieser Artikel erklärt, was der Befehl „awk“ ist und wie man ihn effektiv verwendet.
Was ist der „awk“-Befehl?
Der Befehl „awk“ ist ein mächtiges Werkzeug zum Manipulieren und Verarbeiten von Textdateien in Unix/Linux-Umgebungen. Es kann verwendet werden, um Aufgaben wie Musterabgleich, Filtern, Sortieren und Bearbeiten von Daten auszuführen. awk dient hauptsächlich dazu, Daten strukturiert zu verarbeiten und zu manipulieren.
So verwenden Sie den awk-Befehl
awk ist ein Befehlszeilentool, das auf vielfältige Weise verwendet werden kann. Es kann direkt von der Befehlszeile aufgerufen oder in Verbindung mit einem Shell-Skript verwendet werden. Hier sind einige Beispiele für die Verwendung von awk:
Beispiel 1: Zählen der Anzahl der Zeilen in einer Datei
Um die Anzahl der Zeilen in einer Datei zu zählen, können Sie die folgende awk-Syntax verwenden:
ach 'ENDE{drucke NR}' < Dateiname.txt >
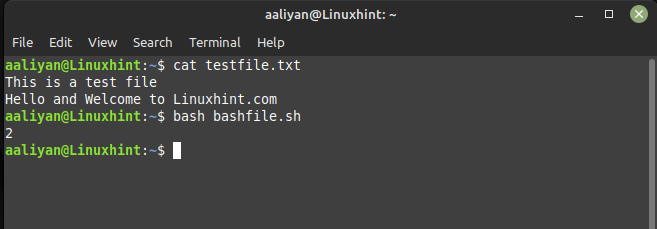
Hier ist „NR“ eine eingebaute Variable, die die Anzahl der von awk verarbeiteten Datensätze (Zeilen) enthält. Das Schlüsselwort „END“ weist awk an, diesen Befehl auszuführen, nachdem alle Zeilen in der Datei verarbeitet wurden. Hier habe ich zur Veranschaulichung eine Datei-Textdatei erstellt und dann die obige Syntax in einem Shell-Skript verwendet, das lautet:
#!/bin/bash
ach 'ENDE{drucke NR}' testdatei.txt
Die von mir erstellte Textdatei hat zwei Zeilen und wenn der Befehl awk verwendet wird, wird die Ausgabe angezeigt 2, Sie können die von mir erstellte Textdatei im Bild unten sehen:
Beispiel 2: Filtern von Daten
Das awk kann verwendet werden, um Daten basierend auf bestimmten Kriterien zu filtern, und hier ist die Syntax, die man für diesen Zweck verwenden sollte:
ach '!/
Sie können beispielsweise den folgenden Befehl verwenden, um alle Zeilen in einer Datei herauszufiltern, die das Wort „Hallo“ enthalten.
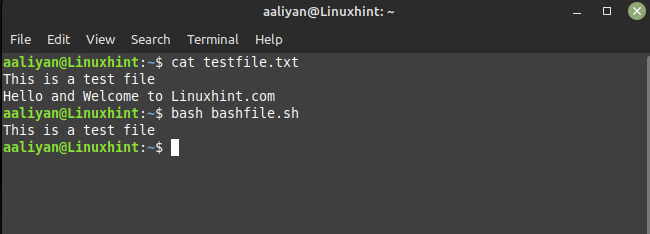
ach '!/Hallo/' testdatei.txt
In diesem Beispiel wird das „!“ symbol negiert die Suche nach regulären Ausdrücken, sodass alle Zeilen gedruckt werden, die das Wort „Hallo“ nicht enthalten. Ich habe die gleiche Textdatei wie im vorherigen Beispiel verwendet, also ist hier die Ausgabe des oben angegebenen Skripts:
Beispiel 3: Extrahieren bestimmter Felder
awk kann auch verwendet werden, um bestimmte Felder aus einer Datei zu extrahieren. Wenn Sie beispielsweise eine Datei mit einer Liste von Namen und Adressen haben und nur die Namen extrahieren möchten, können Sie den folgenden Befehl verwenden:
ach '{print $
Hier habe ich zur Veranschaulichung das erste Feld derselben Textdatei gedruckt und „$1“ steht für das erste Feld in jeder Zeile der Datei. Der Befehl „print“ weist awk an, nur dieses Feld zu drucken.
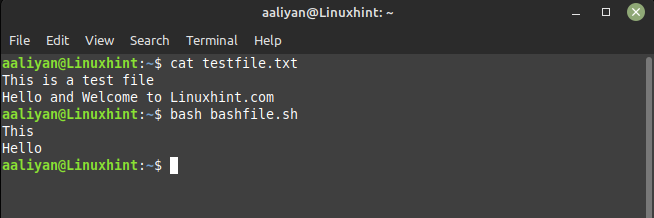
ach '{$1 drucken}' testdatei.txt
In der Textdatei ist der erste Eintrag der ersten Zeile „This“ und der erste Eintrag der zweiten Zeile „Hallo“, also ist hier die Ausgabe des angegebenen Codes:
Abschluss
Der awk-Befehl ist ein mächtiges Werkzeug, das zum Manipulieren und Verarbeiten von Textdateien verwendet wird. Sie können damit verschiedene Operationen an Textdateien ausführen, z. B. bestimmte Spalten drucken, nach Mustern suchen und Summen berechnen. Indem Sie die Grundlagen von awk beherrschen, können Sie Ihren Arbeitsablauf rationalisieren und ein effizienterer und effektiverer Linux- oder Unix-Benutzer werden.