Skalierbarkeit
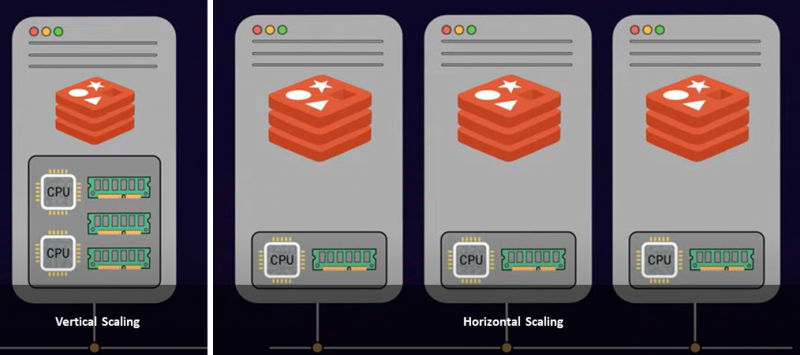
Es gibt zwei gängige Ansätze zur Skalierung eines Servers: vertikale Skalierung und horizontale Skalierung. Beim vertikalen Skalieren oder Hochskalieren fügen Sie Ihrem Server mehr Leistung und Ressourcen hinzu, z. B. mehr CPUs, Arbeitsspeicher und Speicherplatz, was kostspielig ist. Andererseits fügt die horizontale Skalierung Ihrem vorhandenen Ressourcenpool mehrere Knoten hinzu. Dies wird als Aufskalieren bezeichnet. Je nach Ihren Einschränkungen und Anforderungen liegt es also an Ihnen, eine einzelne größere Serverinstanz zu haben oder mehrere Serverknoten bereitzustellen.
Angenommen, Sie haben 100 GB RAM und müssen 200 GB Daten speichern. In diesem Fall haben Sie zwei Möglichkeiten:
- Skalieren Sie, indem Sie dem System mehr RAM hinzufügen
- Skalieren Sie, indem Sie eine weitere Serverinstanz mit 100 GB RAM hinzufügen
Wenn Sie die maximale RAM-Grenze innerhalb Ihrer Infrastruktur erreicht haben, ist Scale-out der ideale Ansatz. Darüber hinaus erhöht die horizontale Skalierung den Datenbankdurchsatz erheblich.
Redis-Splitter
Es ist eine bekannte Tatsache, dass Redis auf einem einzigen Thread arbeitet. Redis ist also nicht in der Lage, mehrere Kerne der CPU Ihres Servers zu verwenden, um Befehle zu verarbeiten. Daher bringt Ihnen das Hinzufügen weiterer CPU-Kerne mit Redis nicht viel Durchsatz oder Leistung. Dies ist nicht der Fall, wenn Sie Ihre Daten auf mehrere Serverinstanzen aufteilen. Das Hinzufügen mehrerer Server und die Verteilung des Datensatzes auf diese ermöglichen die parallele Verarbeitung von Client-Anfragen, was den Durchsatz erhöht. Darüber hinaus kann die Gesamtleistung nahezu linear steigen.
Dieser Ansatz, Daten unter Berücksichtigung der Skalierung auf mehrere Server aufzuteilen oder zu verteilen, wird als Scherben . Alle Server, die Teile der Daten speichern, werden aufgerufen Scherben .
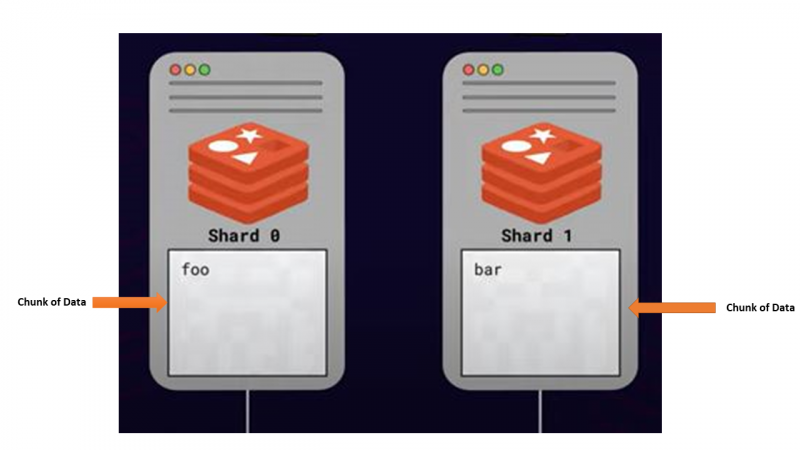
So funktioniert Sharding – Algorithmisches Sharding
Eines der Hauptprobleme beim Sharding war, wie ein bestimmter Schlüssel unter mehreren Redis-Knoten gefunden werden kann. Da ein bestimmter Schlüssel in allen verfügbaren Shards gespeichert werden kann, ist es nicht die beste Option, alle Shards abzufragen, um einen bestimmten Schlüssel zu finden. Es sollte also eine Möglichkeit geben, jeden Schlüssel einem bestimmten Shard zuzuordnen, und Redis verwendet eine algorithmische Sharding-Strategie.
Der gebräuchlichste Ansatz besteht darin, einen Hash-Wert mithilfe des Redis-Schlüsselnamens und Modulo zu berechnen. Teilen Sie es dann durch die verfügbaren Redis-Shards im System.
HASH_SLOT = CRC16(Schlüssel) mod 16384Es ist eine ziemlich gute Lösung, solange die Gesamtzahl der Shards konstant ist. Immer wenn Sie eine neue Reids-Serverinstanz hinzufügen, kann sich der resultierende Wert für einen bestimmten Schlüssel ändern, da sich die Gesamtzahl der Shards erhöht hat. Am Ende wird der falsche Redis-Shard abgefragt. Daher sollten Sie dem Resharding-Prozess folgen, indem Sie den neuen Shard für jeden Schlüssel berechnen und Daten auf den richtigen Server übertragen, was umständlich und keine triviale Aufgabe ist, wenn Ihre Gesamtanzahl von Shards von Zeit zu Zeit steigt.
Redis verwendet eine neue logische Entität namens a Hash-Slot um dieses Problem zu verhindern. Für einen bestimmten Shard stehen mehrere Hash-Slots zur Verfügung, und ein einzelner Hash-Slot kann mehrere Redis-Schlüssel enthalten. Es gibt 16384 Hash-Slots in einem Redis-Datenbank-Cluster, der unverändert bleibt. Die Modulo-Division erfolgt mit der Anzahl der Hash-Slots anstelle der Shard-Anzahl. Es liefert die korrekte Position des Hash-Slots für den angegebenen Schlüssel, auch wenn die Anzahl der Shards zugenommen hat. Es vereinfacht den Resharding-Prozess, indem die Hash-Slots von einem Shard auf das neue verschoben werden, das Daten je nach Anforderung auf die verschiedenen Redis-Instanzen aufteilt.
Vorteile von Redis Sharding
Redis-Sharding ermöglicht mehrere Vorteile für Ihr Datenbanksystem mit minimalen Änderungen.
Hoher Durchsatz
Da Redis Single-Threaded ist, kann die Verarbeitung mehrerer Client-Anforderungen nicht parallel mit mehreren CPU-Kernen verarbeitet werden. Das Hinzufügen neuer Shards oder Serverinstanzen garantiert also, dass Sie Redis-Vorgänge parallel ausführen können. Es erhöht die Operationen pro Sekunde in Ihrer Redis-Datenbank, was Ihnen letztendlich einen hohen Durchsatz beschert.
Hohe Verfügbarkeit
Mit dem Sharding-Ansatz kann der Redis-Cluster eine Master-Replikat-Architektur einrichten, die eine hohe Verfügbarkeit und Langlebigkeit gewährleistet.
Lesen Sie Repliken
Sharding ermöglicht es Ihnen, eine exakte Kopie Ihrer Daten zu behalten und Lesevorgänge über separate Redis-Instanzen bereitzustellen, was die Leistung Ihrer Leseabfrageausführung erhöht.
Abgesehen von diesen Vorteilen kann Sharding zu Split-Brain-Situationen führen, wenn Sie eine gerade Anzahl von Shards im Redis-Cluster haben. Es wird daher empfohlen, eine ungerade Anzahl von Shards in Ihrem Redis-Cluster zu behalten.
Fazit
Zusammenfassend lässt sich sagen, dass Redis-Sharding Daten auf mehrere Server aufteilt, was eine Skalierung und einen hohen Durchsatz für Ihre Datenbank ermöglicht. Wie bereits erwähnt, verwendet Redis eine algorithmische Sharding-Strategie, um Client-Anfragen auf das richtige Shard zu lenken. Dies hat einige Nachteile, wenn die Gesamtzahl der Shards zunimmt. Anstelle der Gesamtzahl der Shards verwendet Redis also die Anzahl der Hash-Slots, um den entsprechenden Shard zu berechnen. Mit der Einführung von Sharding bieten Redis-Datenbanken hohe Verfügbarkeit, hohen Durchsatz und hohe Leistung.