Die for-Schleife ist eine Kontrollstruktur, die es uns ermöglicht, eine Reihe von Anweisungen in einer bestimmten Anzahl von Malen zu wiederholen. Dies ist eine häufig verwendete Methode für die Iteration in R, insbesondere wenn wir dieselbe Operation für einige Elemente ausführen oder über eine Datenstruktur wie die im DataFrame iterieren müssen. Zeilen und Spalten bilden die DataFrames in R, wobei jede Zeile eine einzelne Beobachtung darstellt und jede Spalte eine Variable oder einen Aspekt dieser Beobachtung bezeichnet.
In diesem speziellen Artikel verwenden wir eine for-Schleife, um den DataFrame in verschiedenen Ansätzen zu durchlaufen. Beachten Sie, dass die Iteration der For-Schleife über Zeilen und Spalten für große DataFrames sehr rechenintensiv sein kann.
Beispiel 1: Verwenden von For-Loop über DataFrame-Zeilen in R
Die for-Schleife in R kann verwendet werden, um über die Zeilen eines DataFrame zu iterieren. Innerhalb der for-Schleife können wir den Zeilenindex verwenden, um auf jede Zeile des DataFrame zuzugreifen. Betrachten wir den folgenden R-Code, der die for-Schleife demonstriert, um über die Zeilen des angegebenen DataFrame zu iterieren.
daten = daten.frame (c1 = c (1:5),
c2 = c(6:10),
c3 = c(11:15))
for(i in 1:nrow(data)) {
Zeile <- Daten[i, ]
drucken (Zeile)
}
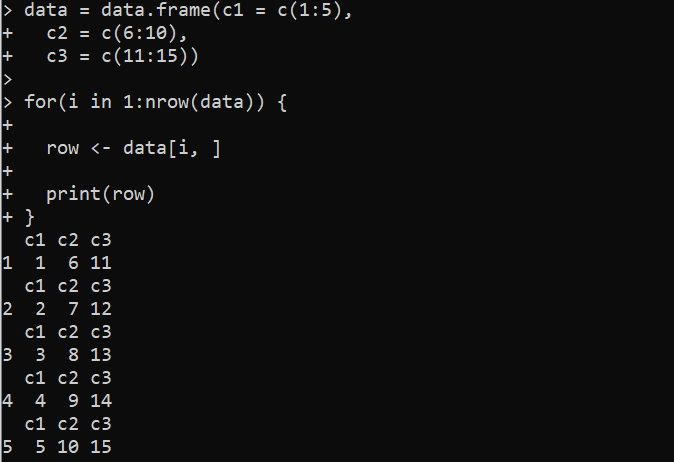
Hier definieren wir zunächst die Funktion data.frame() innerhalb der „Daten“. Die Funktion data.frame() enthält hier drei Spalten. Jede Spalte ist mit einer Zahlenfolge von 1 bis 5, 6 bis 10 bzw. 11 bis 15 belegt. Danach wird die for-Loop-Funktion bereitgestellt, die mit der nrow()-Funktion über die Zeilen des DataFrame „data“ iteriert, um die Gesamtzahl der Zeilen zu erhalten. Die Schleifenvariable „i“ nimmt die Werte für die gesamte Zeilenanzahl in „data“ an.
Dann extrahieren wir die i-te Zeile des DataFrame „data“ mit der Notation „[ ]“ in eckigen Klammern. Die extrahierte Zeile wird in einer „Zeilen“-Variablen gespeichert, die von der Funktion print() gedruckt wird.
Daher durchläuft die Schleife alle Zeilen im DataFrame und zeigt die Zeilennummern in der Ausgabe zusammen mit den Werten der Spalte an.
Beispiel 2: Verwenden von For-Loop über DataFrame-Spalten
In ähnlicher Weise können wir die for-Schleife in R verwenden, um die Spalten des angegebenen Datenrahmens zu durchlaufen. Wir können den vorherigen Code verwenden, um die Spalten zu durchlaufen, aber wir müssen die Funktion ncol() in der for-Schleife verwenden. Umgekehrt haben wir den einfachsten Ansatz, um die Spalten des DataFrame mit for-loop zu durchlaufen. Betrachten Sie dazu den folgenden R-Code:
df = data.frame (col1 = c (10, 20, 30, 40, 50),col2 = c(11, 21, 31, 41, 51),
col3 = c(12, 22, 32, 42, 52))
for(Spalte in Spaltennamen(df)) {
Spalte <- df[[Spalte]]
drucken (Spalte)
}
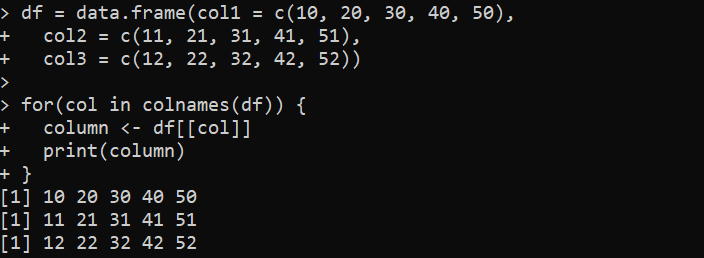
Hier erstellen wir zuerst die df-Variable, in der data.frame() mit der Spalteneinfügung verwendet wird. Der DataFrame „df“ enthält drei Spalten, die numerische Werte enthalten. Als Nächstes verwenden wir eine for-Schleife, um die Spaltennamen des DataFrame „data“ mit der Funktion colnames() zu durchlaufen. Bei jeder Iteration nimmt die Schleifenvariable „col“ den Namen der aktuellen Spalte an. Die extrahierte Spalte wird dann in einer neuen Variablen namens „Spalte“ gespeichert.
Die Daten der Variable „Spalte“ geben also die Ausgabe auf der folgenden Konsole aus:
Beispiel 3: Verwenden der For-Schleife über den gesamten DataFrame
In den vorherigen Beispielen haben wir die Spalten und Zeilen jeweils mit der for-Schleife durchlaufen. Jetzt verwenden wir die verschachtelten for-Schleifen, um gleichzeitig über die Zeilen und Spalten eines DataFrame zu iterieren. Der Code von R wird im Folgenden bereitgestellt, wo die verschachtelte for-Schleife über den Spalten und Zeilen verwendet wird:
Mitarbeiter <- data.frame(id=1:4,names=c('kim', 'John', 'Ian', 'Mark'),
location=c('Australien', 'Amerika', 'Kanada', 'Jordanien'),
Gehalt=c(2000, 1800, 1500, 1000))
for (Zeile in 1:nrow(Mitarbeiter)) {
for (col in 1:ncol(Mitarbeiter)) {
print(paste('Zeilenindex', Zeile, 'Spaltenname', Spalte, 'Zellenwert', Mitarbeiter[Zeile, Spalte]))
}
}
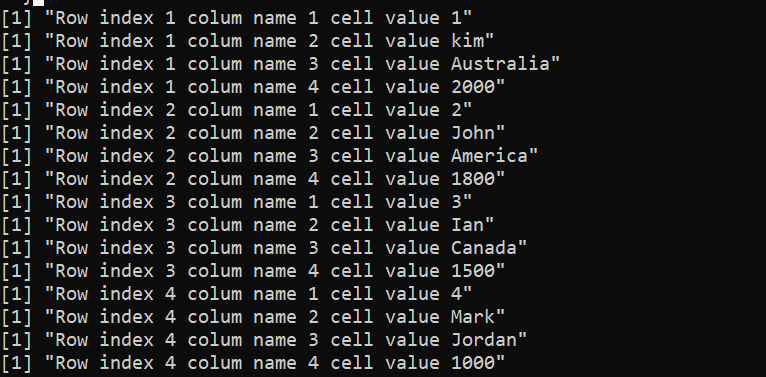
Hier deklarieren wir die Variable „Mitarbeiter“, in der data.frame() aufgerufen wird, um die Spalten festzulegen. Die Werte in jeder Spalte werden mithilfe von Vektoren angegeben. Dann verwenden wir für die Zeile und Spalte des DataFrame „Mitarbeiter“ zwei verschachtelte for-Schleifen, um die Daten zu durchlaufen. Die äußere Schleife durchläuft die Zeilen des angegebenen DataFrame mit „1:nrow(employees)“. Für jede Zeile wird „1:ncol(employees)“ in der inneren Schleife verwendet, um wiederholt über die Spalten des DataFrame zu iterieren.
Danach haben wir eine print()-Funktion innerhalb der verschachtelten Schleifen, die die paste()-Funktion bereitstellt, um den Zeilenindex, den Spaltenindex und den Zellenwert zu einer einzigen Zeichenfolge zu verketten. Der Ausdruck employee [Zeile, Spalte] erhält hier den Wert in der aktuellen Zelle, wobei Zeile und Spalte die vorhandenen Zeilen- bzw. Spaltenindizes sind.
Daher wird die Ausgabe auf der Konsole mit dem verketteten Zeilenindex, Spaltenindex und Zellenwert in einer einzigen Zeichenfolge abgerufen.
Beispiel 4: Alternative Methode für die For-Schleife in R
Die for-Schleife ist jetzt in der R-Sprache veraltet. Es bietet jedoch einige alternative Methoden, die genauso funktionieren wie die for-Schleife und schneller als die for-Schleifen sind. Die Methode stammt aus den Funktionen der „Apply-Familie“, die im Hintergrund eine For-Schleife ausführen, um DataFrames zu durchlaufen. Betrachten wir den folgenden R-Code, in dem die Funktion sapply() verwendet wird, um den DataFrame zu durchlaufen.
dfX <- data.frame (var1=c(1:5),var2=c(6:10),
var3=c(11:15),
var4=c(16:20))
dfX
sapply(dfX, Summe)
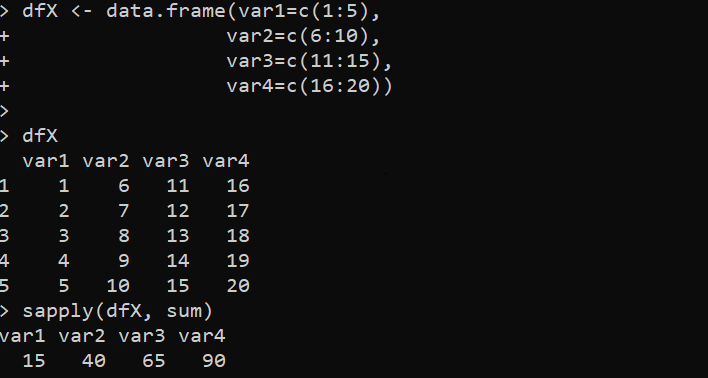
Hier erstellen wir zunächst den DataFrame „dfX“, indem wir die Funktion data.frame() mit zwei Spalten aufrufen, die jeweils numerische Werte enthalten. Wir drucken dann den ursprünglichen „dfX“-Datenrahmen auf die Konsole. Im nächsten Schritt verwenden wir die Funktion sapply(), um über den bereitgestellten DataFrame zu iterieren und die Summe jeder Spalte zu erhalten. Die Funktion sapply() übernimmt im Allgemeinen die Argumente „x“ und „FUN“. In diesem Fall ist X der DataFrame „dfX“ und „FUN“ ist die Funktion sum(), die auf jede Spalte des DataFrame angewendet wird.
Das Ergebnis der Iteration, das durch die Funktion sapply() erreicht wird, wird im folgenden Bildschirm erreicht. Die Ergebnisse der Summenoperation des DataFrames werden für jede Spalte angezeigt. Darüber hinaus können wir auch einige andere Funktionen der „Apply-Familie“ für die for-Schleife-Operation in R verwenden:
Abschluss
Wir arbeiten mit For-Schleifen, um die Zeilen oder Spalten des DataFrame zu durchlaufen, um eine bestimmte Operation auszuführen. Die for-Schleife wird einzeln verwendet, um über die Spalten und Zeilen zu iterieren. Darüber hinaus verwenden wir dies für die Iteration über Spalten und Zeilen des Datenrahmens gleichzeitig. Meistens ist es effektiver, Funktionen anzuwenden, um das gewünschte Ergebnis zu erzielen. Das Beispiel der apply-Funktion wird im letzten Beispiel über die for-Schleife-Operation gegeben.