Wie verwende ich ein Konversationspufferfenster in LangChain?
Das Konversationspufferfenster wird verwendet, um die neuesten Nachrichten der Konversation im Speicher zu behalten, um den aktuellsten Kontext zu erhalten. Es verwendet den Wert von K zum Speichern der Nachrichten oder Zeichenfolgen im Speicher mithilfe des LangChain-Frameworks.
Um den Prozess der Verwendung des Konversationspufferfensters in LangChain zu erlernen, gehen Sie einfach die folgende Anleitung durch:
Schritt 1: Module installieren
Starten Sie den Prozess der Verwendung des Konversationspufferfensters, indem Sie das LangChain-Modul mit den erforderlichen Abhängigkeiten zum Erstellen von Konversationsmodellen installieren:
pip langchain installieren
Installieren Sie anschließend das OpenAI-Modul, mit dem die Large Language Models in LangChain erstellt werden können:
pip openai installieren
Jetzt, Richten Sie die OpenAI-Umgebung ein So erstellen Sie die LLM-Ketten mithilfe des API-Schlüssels aus dem OpenAI-Konto:
importieren Du
importieren getpass
Du . etwa [ „OPENAI_API_KEY“ ] = getpass . getpass ( „OpenAI-API-Schlüssel:“ )
Schritt 2: Verwenden des Konversationspuffer-Fensterspeichers
Um den Konversationspuffer-Fensterspeicher in LangChain zu verwenden, importieren Sie die ConversationBufferWindowMemory Bibliothek:
aus langchain. Erinnerung importieren ConversationBufferWindowMemoryKonfigurieren Sie den Speicher mit ConversationBufferWindowMemory ()-Methode mit dem Wert von k als Argument. Der Wert von k wird verwendet, um die neuesten Nachrichten aus der Konversation beizubehalten und dann die Trainingsdaten mithilfe der Eingabe- und Ausgabevariablen zu konfigurieren:
Erinnerung = ConversationBufferWindowMemory ( k = 1 )Erinnerung. save_context ( { 'Eingang' : 'Hallo' } , { 'Ausgabe' : 'Wie geht es dir' } )
Erinnerung. save_context ( { 'Eingang' : 'Mir geht es gut und dir' } , { 'Ausgabe' : 'nicht viel' } )
Testen Sie den Speicher, indem Sie die aufrufen Load_memory_variables ()-Methode zum Starten der Konversation:
Erinnerung. Load_memory_variables ( { } ) 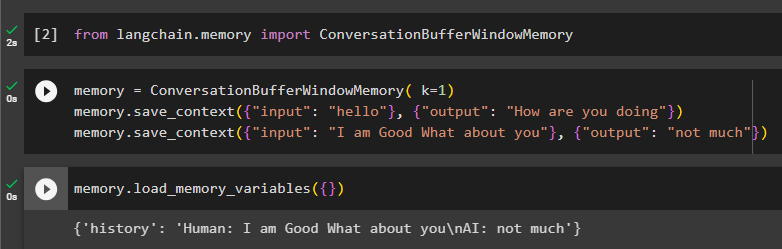
Um den Verlauf der Konversation abzurufen, konfigurieren Sie die Funktion ConversationBufferWindowMemory() mit return_messages Streit:
Erinnerung = ConversationBufferWindowMemory ( k = 1 , return_messages = WAHR )Erinnerung. save_context ( { 'Eingang' : 'Hi' } , { 'Ausgabe' : 'was ist los' } )
Erinnerung. save_context ( { 'Eingang' : „Nicht viel von dir“ } , { 'Ausgabe' : 'nicht viel' } )
Rufen Sie nun den Speicher mit auf Load_memory_variables ()-Methode, um die Antwort mit dem Verlauf der Konversation zu erhalten:
Erinnerung. Load_memory_variables ( { } ) 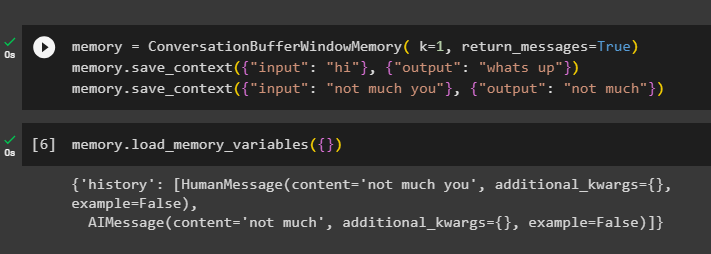
Schritt 3: Pufferfenster in einer Kette verwenden
Bauen Sie die Kette mit dem auf OpenAI Und Konversationskette Bibliotheken und konfigurieren Sie dann den Pufferspeicher, um die neuesten Nachrichten in der Konversation zu speichern:
aus langchain. Ketten importieren Konversationsketteaus langchain. lms importieren OpenAI
#Zusammenfassung der Konversation unter Verwendung mehrerer Parameter erstellen
Konversation_mit_Zusammenfassung = Konversationskette (
llm = OpenAI ( Temperatur = 0 ) ,
#Speicherpuffer mithilfe seiner Funktion mit dem Wert k aufbauen, um aktuelle Nachrichten zu speichern
Erinnerung = ConversationBufferWindowMemory ( k = 2 ) ,
#configure ausführliche Variable, um eine besser lesbare Ausgabe zu erhalten
ausführlich = WAHR
)
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = 'Hi was geht' )
Halten Sie das Gespräch nun am Laufen, indem Sie die Frage stellen, die sich auf die vom Modell bereitgestellte Ausgabe bezieht:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = „Was sind ihre Probleme?“ ) 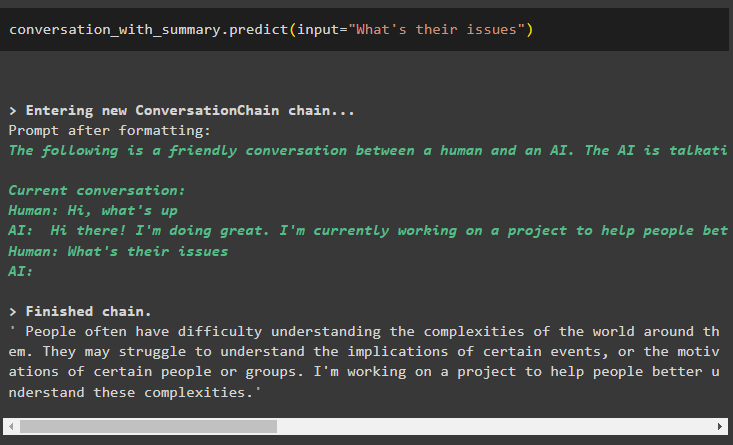
Das Modell ist so konfiguriert, dass es nur eine vorherige Nachricht speichert, die als Kontext verwendet werden kann:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = 'Geht es gut' ) 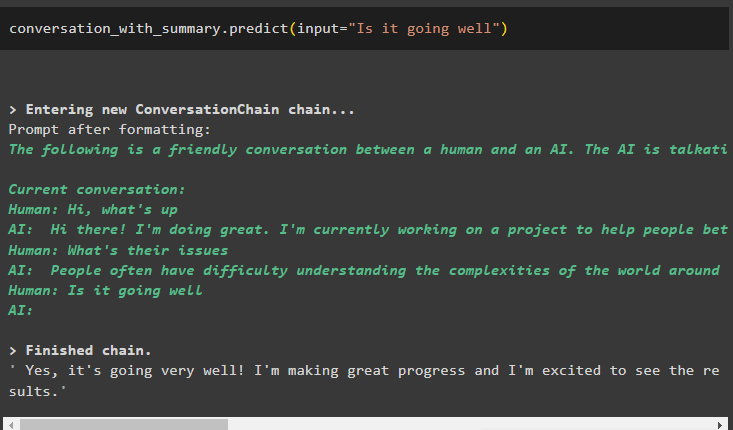
Wenn Sie nach einer Lösung für die Probleme fragen, verschiebt die Ausgabestruktur das Pufferfenster weiter, indem sie die früheren Meldungen entfernt:
Konversation_mit_Zusammenfassung. vorhersagen ( Eingang = 'Was ist die Lösung' ) 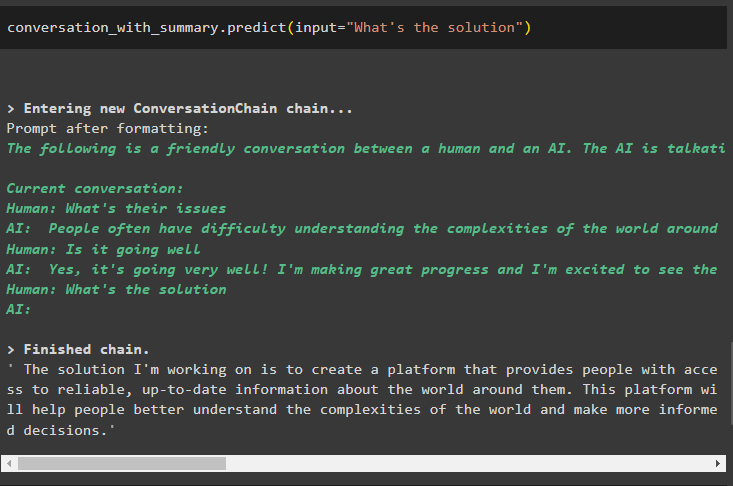
Das ist alles über den Prozess der Verwendung des Konversationspuffers Windows LangChain.
Abschluss
Um den Konversationspuffer-Fensterspeicher in LangChain zu nutzen, installieren Sie einfach die Module und richten Sie die Umgebung mit dem API-Schlüssel von OpenAI ein. Erstellen Sie anschließend den Pufferspeicher mit dem Wert von k, um die neuesten Nachrichten in der Konversation beizubehalten und den Kontext beizubehalten. Der Pufferspeicher kann auch mit Ketten verwendet werden, um die Konversation mit dem LLM oder der Kette anzustoßen. In diesem Leitfaden wurde der Prozess der Verwendung des Konversationspufferfensters in LangChain erläutert.