LangChain ist das Framework, das zum Importieren von Bibliotheken und Abhängigkeiten zum Erstellen großer Sprachmodelle oder LLMs verwendet werden kann. Die Sprachmodelle nutzen den Speicher, um Daten oder den Verlauf in der Datenbank als Beobachtung zu speichern, um den Kontext der Konversation zu ermitteln. Der Speicher ist so konfiguriert, dass er die neuesten Nachrichten speichert, damit das Modell die mehrdeutigen Eingabeaufforderungen des Benutzers verstehen kann.
In diesem Blog wird der Prozess der Speichernutzung in LLMChain über LangChain erläutert.
Wie nutzt man den Speicher in LLMChain über LangChain?
Um Speicher hinzuzufügen und ihn in der LLMChain über LangChain zu verwenden, kann die ConversationBufferMemory-Bibliothek verwendet werden, indem sie aus der LangChain importiert wird.
Um den Prozess der Nutzung des Speichers in LLMChain über LangChain zu erlernen, lesen Sie die folgende Anleitung:
Schritt 1: Module installieren
Beginnen Sie zunächst mit der Nutzung des Speichers, indem Sie LangChain mit dem Befehl pip installieren:
pip langchain installieren
Installieren Sie die OpenAI-Module, um deren Abhängigkeiten oder Bibliotheken zum Erstellen von LLMs oder Chat-Modellen zu erhalten:
pip openai installieren
Richten Sie die Umgebung ein für OpenAI unter Verwendung seines API-Schlüssels durch Importieren der Bibliotheken os und getpass:
Importieren Sie unsgetpass importieren
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API-Schlüssel:')
Schritt 2: Bibliotheken importieren
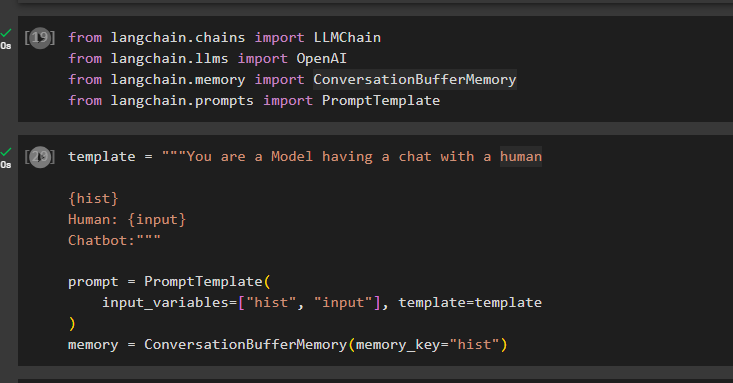
Nachdem Sie die Umgebung eingerichtet haben, importieren Sie einfach die Bibliotheken wie ConversationBufferMemory aus der LangChain:
aus langchain.chains importieren Sie LLMChainaus langchain.llms OpenAI importieren
aus langchain.memory ConversationBufferMemory importieren
Importieren Sie PromptTemplate aus langchain.prompts
Konfigurieren Sie die Vorlage für die Eingabeaufforderung mithilfe von Variablen wie „input“, um die Abfrage vom Benutzer zu erhalten, und „hist“, um die Daten im Pufferspeicher zu speichern:
template = '''Du bist ein Model, das mit einem Menschen chattet{hist}
Mensch: {input}
Chatbot:'''
prompt = PromptTemplate(
input_variables=['hist', 'input'], template=template
)
Speicher = ConversationBufferMemory(memory_key='hist')
Schritt 3: LLM konfigurieren
Sobald die Vorlage für die Abfrage erstellt ist, konfigurieren Sie die LLMChain()-Methode mit mehreren Parametern:
llm = OpenAI()llm_chain = LLMChain(
llm=llm,
prompt=Eingabeaufforderung,
verbose=Wahr,
Speicher=Speicher,
)
Schritt 4: LLMChain testen
Testen Sie anschließend die LLMChain mithilfe der Eingabevariablen, um die Eingabeaufforderung vom Benutzer in Textform zu erhalten:
llm_chain.predict(input='Hallo mein Freund') 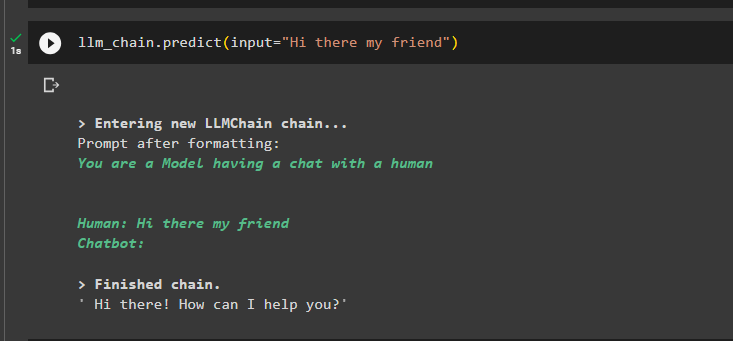
Verwenden Sie eine andere Eingabe, um die im Speicher gespeicherten Daten abzurufen und die Ausgabe mithilfe des Kontexts zu extrahieren:
llm_chain.predict(input='Gut! Mir geht es gut - wie geht es dir') 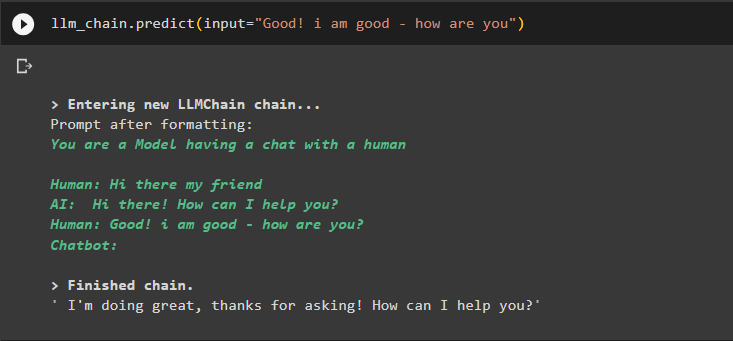
Schritt 5: Speicher zu einem Chat-Modell hinzufügen
Der Speicher kann durch den Import der Bibliotheken zur Chat-Modell-basierten LLMChain hinzugefügt werden:
aus langchain.chat_models ChatOpenAI importierenaus langchain.schema SystemMessage importieren
aus langchain.prompts importieren ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder
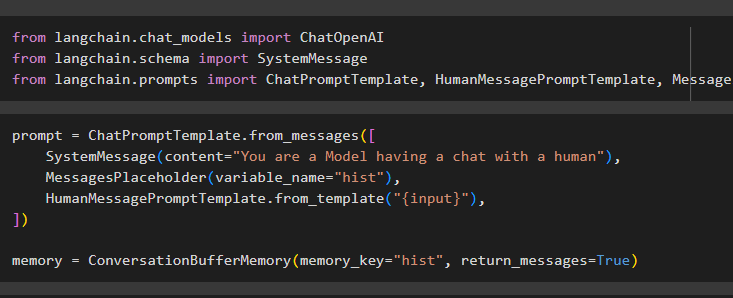
Konfigurieren Sie die Eingabeaufforderungsvorlage mithilfe von ConversationBufferMemory() und verwenden Sie verschiedene Variablen, um die Eingaben des Benutzers festzulegen:
prompt = ChatPromptTemplate.from_messages([SystemMessage(content='Sie sind ein Model, das mit einem Menschen chattet'),
MessagesPlaceholder(variable_),
HumanMessagePromptTemplate.from_template('{input}'),
])
Memory = ConversationBufferMemory(memory_key='hist', return_messages=True)
Schritt 6: LLMChain konfigurieren
Richten Sie die LLMChain()-Methode ein, um das Modell mit verschiedenen Argumenten und Parametern zu konfigurieren:
llm = ChatOpenAI()chat_llm_chain = LLMChain(
llm=llm,
prompt=Eingabeaufforderung,
verbose=Wahr,
Speicher=Speicher,
)
Schritt 7: LLMChain testen
Testen Sie am Ende einfach die LLMChain mithilfe der Eingabe, damit das Modell den Text gemäß der Eingabeaufforderung generieren kann:
chat_llm_chain.predict(input='Hallo mein Freund') 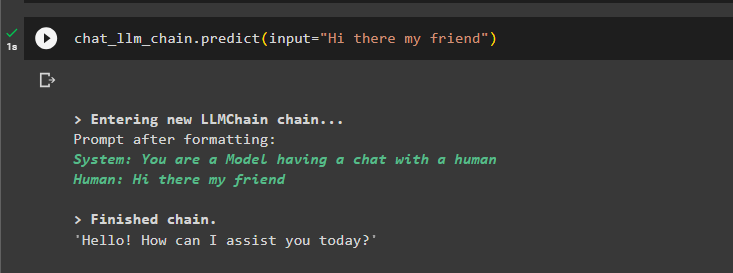
Das Modell hat die vorherige Konversation im Speicher abgelegt und zeigt sie vor der eigentlichen Ausgabe der Abfrage an:
llm_chain.predict(input='Gut! Mir geht es gut - wie geht es dir') 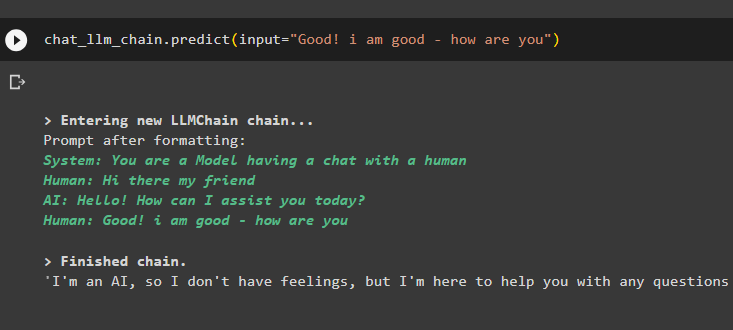
Dabei geht es um die Speichernutzung in LLMChain mithilfe von LangChain.
Abschluss
Um den Speicher in LLMChain über das LangChain-Framework zu nutzen, installieren Sie einfach die Module, um die Umgebung einzurichten, um die Abhängigkeiten von den Modulen abzurufen. Anschließend importieren Sie einfach die Bibliotheken aus LangChain, um den Pufferspeicher zum Speichern der vorherigen Konversation zu nutzen. Der Benutzer kann dem Chat-Modell auch Speicher hinzufügen, indem er die LLMChain erstellt und dann die Kette testet, indem er die Eingabe bereitstellt. In diesem Leitfaden wurde der Prozess der Speichernutzung in LLMChain über LangChain erläutert.