Pandas füllen NaN-Werte
Wenn eine Spalte in Ihrem Datenrahmen NaN- oder None-Werte hat, können Sie die Funktionen „fillna()“ oder „replace()“ verwenden, um sie mit Null (0) zu füllen.
füllen()
Die NA/NaN-Werte werden mit dem bereitgestellten Ansatz über die Funktion „fillna()“ gefüllt. Es kann verwendet werden, indem die folgende Syntax berücksichtigt wird:
Wenn Sie die NaN-Werte für eine einzelne Spalte füllen möchten, lautet die Syntax wie folgt:

Wenn Sie die NaN-Werte für den vollständigen DataFrame ausfüllen müssen, lautet die Syntax wie folgt:

Ersetzen()
Um eine einzelne Spalte mit NaN-Werten zu ersetzen, lautet die bereitgestellte Syntax wie folgt:

Um die NaN-Werte des gesamten DataFrame zu ersetzen, müssen wir die folgende erwähnte Syntax verwenden:

In diesem Artikel werden wir nun die praktische Implementierung dieser beiden Methoden untersuchen und lernen, um die NaN-Werte in unserem Pandas DataFrame zu füllen.
Beispiel 1: Füllen Sie NaN-Werte mit Pandas „Fillna()“-Methode
Diese Abbildung zeigt die Anwendung der Funktion „DataFrame.fillna()“ von Panda, um die NaN-Werte im angegebenen DataFrame mit 0 zu füllen. Sie können die fehlenden Werte entweder in einer einzelnen Spalte oder für den gesamten DataFrame füllen. Hier werden wir diese beiden Techniken sehen.
Um diese Strategien in die Tat umzusetzen, brauchen wir eine geeignete Plattform für die Ausführung des Programms. Also haben wir uns für das Tool „Spyder“ entschieden. Wir haben unseren Python-Code gestartet, indem wir das „Pandas“-Toolkit in das Programm importiert haben, da wir die Pandas-Funktion verwenden müssen, um den DataFrame zu erstellen und die fehlenden Werte in diesem DataFrame zu füllen. Das „pd“ wird im gesamten Programm als Alias für „pandas“ verwendet.
Jetzt haben wir Zugriff auf Pandas-Funktionen. Wir verwenden zuerst die Funktion „pd.DataFrame()“, um unseren DataFrame zu generieren. Wir haben diese Methode aufgerufen und mit drei Spalten initialisiert. Die Titel dieser Spalten lauten „M1“, „M2“ und „M3“. Die Werte in der Spalte „M1“ sind „1“, „Keine“, „5“, „9“ und „3“. Die Einträge in „M2“ sind „Keine“, „3“, „8“, „4“ und „6“. Während der „M3“ die Daten als „1“, „2“, „3“, „5“ und „Keine“ speichert. Wir benötigen ein DataFrame-Objekt, in dem wir diesen DataFrame speichern können, wenn die Methode „pd.DataFrame()“ aufgerufen wird. Wir haben ein „fehlendes“ DataFrame-Objekt erstellt und es anhand des Ergebnisses zugewiesen, das wir von der Funktion „pd.DataFrame()“ erhalten haben. Dann haben wir die „print()“-Methode von Python verwendet, um den DataFrame auf der Python-Konsole anzuzeigen.
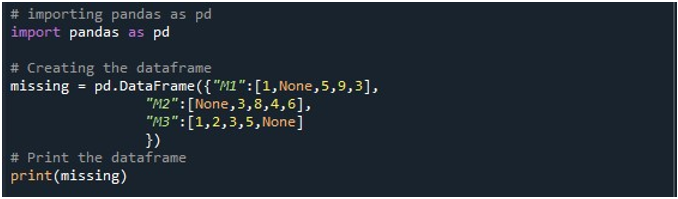
Wenn wir diesen Codeabschnitt ausführen, kann ein DataFrame mit drei Spalten auf dem Terminal angezeigt werden. Hier können wir beobachten, dass alle drei Spalten die Nullwerte enthalten.
Wir haben einen DataFrame mit einigen Nullwerten erstellt, um die Pandas-Funktion „fillna()“ anzuwenden, um die fehlenden Werte mit 0 zu füllen. Lassen Sie uns lernen, wie wir das tun können.
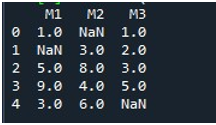
Nach dem Anzeigen des DataFrame haben wir die Funktion „fillna()“ von Pandas aufgerufen. Hier lernen wir, die fehlenden Werte in einer einzelnen Spalte zu füllen. Die Syntax dafür wird bereits zu Beginn des Tutorials erwähnt. Wir haben den Namen des DataFrames bereitgestellt und den jeweiligen Spaltentitel mit der Funktion „.fillna()“ angegeben. Zwischen den Klammern dieser Methode haben wir den Wert angegeben, der an die Nullstellen gesetzt wird. Der DataFrame-Name ist „missing“ und die Spalte, die wir hier ausgewählt haben, ist „M2“. Der zwischen den geschweiften Klammern von „fillna()“ angegebene Wert ist „0“. Zuletzt haben wir die Funktion „print()“ aufgerufen, um den aktualisierten DataFrame anzuzeigen.

Hier sehen Sie, dass die Spalte „M2“ des DataFrames jetzt keine fehlenden Werte enthält, da der NaN-Wert mit 0 gefüllt ist.
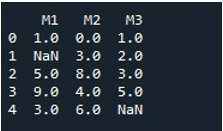
Um die NaN-Werte für einen ganzen DataFrame mit derselben Methode zu füllen, haben wir „fillna()“ aufgerufen. Das ist ganz einfach. Wir haben den DataFrame-Namen mit der Funktion „fillna()“ versehen und zwischen den Klammern den Funktionswert „0“ zugewiesen. Schließlich zeigte uns die Funktion „print()“ den gefüllten DataFrame.

Dadurch erhalten wir einen DataFrame ohne NaN-Werte, da alle Werte jetzt mit 0 aufgefüllt werden.
Beispiel 2: Füllen Sie NaN-Werte mit der Pandas-Methode „Replace()“ aus
Dieser Teil des Artikels zeigt eine andere Methode zum Füllen der NaN-Werte in einem DataFrame. Wir werden die „replace()“-Funktion von Pandas verwenden, um die Werte in einer einzelnen Spalte und in einem vollständigen DataFrame zu füllen.
Wir beginnen mit dem Schreiben des Codes im Tool „Spyder“. Zuerst haben wir die erforderlichen Bibliotheken importiert. Hier haben wir die Pandas-Bibliothek geladen, damit das Python-Programm die Pandas-Methoden verwenden kann. Die zweite Bibliothek, die wir geladen haben, ist NumPy und alias „np“. NumPy behandelt die fehlenden Daten mit der Methode „replace()“.
Dann haben wir einen DataFrame mit drei Spalten generiert – „Schraube“, „Nagel“ und „Bohrer“. Die Werte in jeder Spalte sind jeweils angegeben. Die Spalte „Schraube“ enthält die Werte „112“, „234“, „Keine“ und „650“. Die Spalte „Nagel“ enthält „123“, „145“, „Keine“ und „711“. Schließlich enthält die Spalte „Drill“ die Werte „312“, „None“, „500“ und „None“. Der DataFrame wird im DataFrame-Objekt „tool“ gespeichert und mit der Methode „print()“ angezeigt.
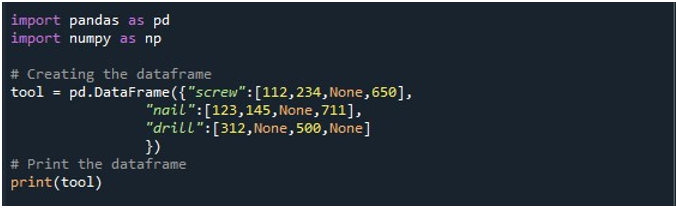
Ein DataFrame mit vier NaN-Werten im Datensatz ist im folgenden Ausgabebild zu sehen:
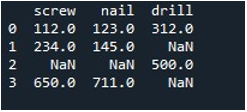
Jetzt verwenden wir die „replace()“-Methode von Pandas, um die Nullwerte in einer einzelnen Spalte des DataFrame zu füllen. Für die Aufgabe haben wir die Funktion „replace()“ aufgerufen. Wir haben den DataFrame-Namen „Tool“ und die Spalte „Schraube“ mit der Methode „.replace()“ bereitgestellt. Zwischen den geschweiften Klammern setzen wir für die „np.nan“-Einträge im DataFrame den Wert „0“. Zur Anzeige der Ausgabe wird die Methode „print()“ verwendet.

Der resultierende DataFrame zeigt uns die erste Spalte mit NaN-Einträgen, die in der Spalte „Schraube“ durch 0 ersetzt werden.
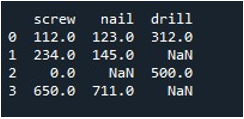
Jetzt lernen wir, die Werte im gesamten DataFrame zu füllen. Wir haben die Methode „replace()“ mit dem Namen des DataFrame aufgerufen und den Wert bereitgestellt, den wir durch np.nan-Einträge ersetzen möchten. Abschließend haben wir den aktualisierten DataFrame mit der Funktion „print()“ ausgedruckt.

Dies liefert uns den resultierenden DataFrame ohne fehlende Datensätze.
Fazit
Der Umgang mit den fehlenden Einträgen in einem DataFrame ist eine grundlegende und notwendige Voraussetzung, um die Komplexität zu reduzieren und die Daten im Datenanalyseprozess trotzig zu handhaben. Pandas bietet uns einige Optionen, um mit diesem Problem fertig zu werden. Wir haben in diesem Leitfaden zwei praktische Strategien vorgestellt. Wir haben beide Techniken mit Hilfe des Tools „Spyder“ in die Praxis umgesetzt, um die Beispielcodes auszuführen, um die Dinge für Sie etwas verständlicher und einfacher zu machen. Das Erlernen dieser Funktionen wird Ihre Pandas-Fähigkeiten schärfen.