Was ist Kubernetes nodeSelector?
Ein nodeSelector ist eine Scheduling-Einschränkung in Kubernetes, die eine Zuordnung in Form eines Schlüssels angibt: Wertpaar benutzerdefinierte Pod-Selektoren und Knotenbezeichnungen werden verwendet, um das Schlüssel-Wert-Paar zu definieren. Der auf dem Knoten beschriftete nodeSelector sollte mit dem Schlüssel: Wert-Paar übereinstimmen, damit ein bestimmter Pod auf einem bestimmten Knoten ausgeführt werden kann. Um den Pod zu planen, werden Labels auf Knoten und nodeSelectors auf Pods verwendet. Die OpenShift Container Platform plant die Pods auf den Knoten mit dem nodeSelector, indem sie die Labels abgleicht.
Darüber hinaus werden Labels und nodeSelector verwendet, um zu steuern, welcher Pod auf einem bestimmten Knoten geplant werden soll. Wenn Sie die Labels und nodeSelector verwenden, beschriften Sie zuerst den Knoten, damit die Pods nicht entplant werden, und fügen Sie dann den nodeSelector zum Pod hinzu. Um einen bestimmten Pod auf einem bestimmten Knoten zu platzieren, wird der nodeSelector verwendet, während Sie mit dem clusterweiten nodeSelector einen neuen Pod auf einem bestimmten Knoten platzieren können, der irgendwo im Cluster vorhanden ist. Der Projekt-nodeSelector wird verwendet, um den neuen Pod auf einem bestimmten Knoten im Projekt zu platzieren.
Voraussetzungen
Um den Kubernetes nodeSelector zu verwenden, stellen Sie sicher, dass die folgenden Tools auf Ihrem System installiert sind:
- Ubuntu 20.04 oder eine andere aktuelle Version
- Minikube-Cluster mit mindestens einem Worker-Knoten
- Kubectl-Befehlszeilentool
Jetzt gehen wir zum nächsten Abschnitt über, in dem wir demonstrieren, wie Sie nodeSelector in einem Kubernetes-Cluster verwenden können.
nodeSelector-Konfiguration in Kubernetes
Ein Pod kann mithilfe von nodeSelector so eingeschränkt werden, dass er nur auf einem bestimmten Knoten ausgeführt werden kann. Der nodeSelector ist eine Knotenauswahlbeschränkung, die in der Pod-Spezifikation PodSpec angegeben ist. Mit einfachen Worten, der nodeSelector ist eine Planungsfunktion, die Ihnen die Kontrolle über den Pod gibt, um den Pod auf einem Knoten mit demselben Label zu planen, das vom Benutzer für das nodeSelector-Label angegeben wurde. Um den nodeSelector in Kubernetes zu verwenden oder zu konfigurieren, benötigen Sie den Minikube-Cluster. Starten Sie den Minikube-Cluster mit dem unten angegebenen Befehl:
> minikube start
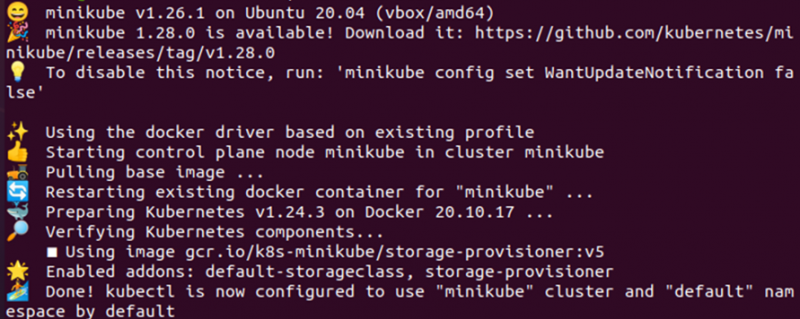
Nachdem der Minikube-Cluster nun erfolgreich gestartet wurde, können wir mit der Umsetzung der Konfiguration des nodeSelectors in Kubernetes beginnen. In diesem Dokument führen wir Sie durch die Erstellung von zwei Bereitstellungen, eine ohne NodeSelector und die andere mit NodeSelector.
Konfigurieren Sie die Bereitstellung ohne nodeSelector
Zuerst extrahieren wir die Details aller Knoten, die derzeit im Cluster aktiv sind, indem wir den unten angegebenen Befehl verwenden:
> kubectl erhält KnotenDieser Befehl listet alle im Cluster vorhandenen Knoten mit den Details von Namen, Status, Rollen, Alter und Versionsparametern auf. Siehe die unten angegebene Beispielausgabe:

Jetzt prüfen wir, welche Taints auf den Knoten im Cluster aktiv sind, damit wir die Bereitstellung der Pods auf dem Knoten entsprechend planen können. Der unten angegebene Befehl soll verwendet werden, um die Beschreibung der auf den Knoten angewendeten Markierungen zu erhalten. Auf dem Knoten sollten keine Taints aktiv sein, damit die Pods problemlos darauf bereitgestellt werden können. Lassen Sie uns also sehen, welche Taints im Cluster aktiv sind, indem Sie den folgenden Befehl ausführen:
> kubectl beschreiben Knoten minikube | Griffigkeit Verderben 
Aus der oben angegebenen Ausgabe können wir ersehen, dass auf dem Knoten kein Taint angewendet wird, sondern genau das, was wir zum Bereitstellen der Pods auf dem Knoten benötigen. Der nächste Schritt besteht nun darin, eine Bereitstellung zu erstellen, ohne einen nodeSelector darin anzugeben. In diesem Zusammenhang verwenden wir eine YAML-Datei, in der wir die nodeSelector-Konfiguration speichern. Der hier angehängte Befehl wird für die Erstellung der YAML-Datei verwendet:
> nano deplond.yamlHier versuchen wir, mit dem nano-Befehl eine YAML-Datei namens deplond.yaml zu erstellen.
Nach Ausführung dieses Befehls haben wir eine deplond.yaml-Datei, in der wir die Bereitstellungskonfiguration speichern. Siehe die unten angegebene Bereitstellungskonfiguration:
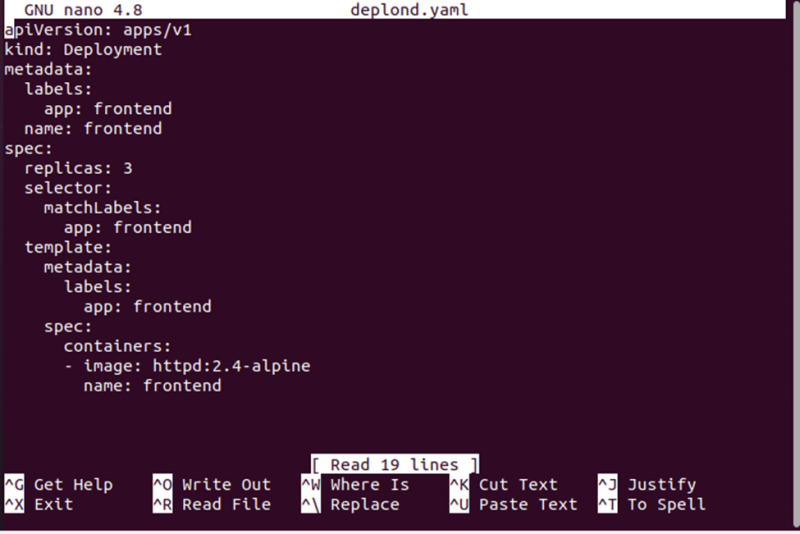
Jetzt erstellen wir die Bereitstellung mithilfe der Bereitstellungskonfigurationsdatei. Die Datei deplond.yaml wird zusammen mit dem Befehl „create“ verwendet, um die Konfiguration zu erstellen. Siehe den vollständigen Befehl unten:
> kubectl erstellen -f deplond.yaml 
Wie oben gezeigt, wurde die Bereitstellung erfolgreich erstellt, jedoch ohne nodeSelector. Lassen Sie uns nun die Knoten überprüfen, die bereits im Cluster verfügbar sind, mit dem folgenden Befehl:
> kubectl erhält PodsDadurch werden alle im Cluster verfügbaren Pods aufgelistet. Siehe die unten angegebene Ausgabe:
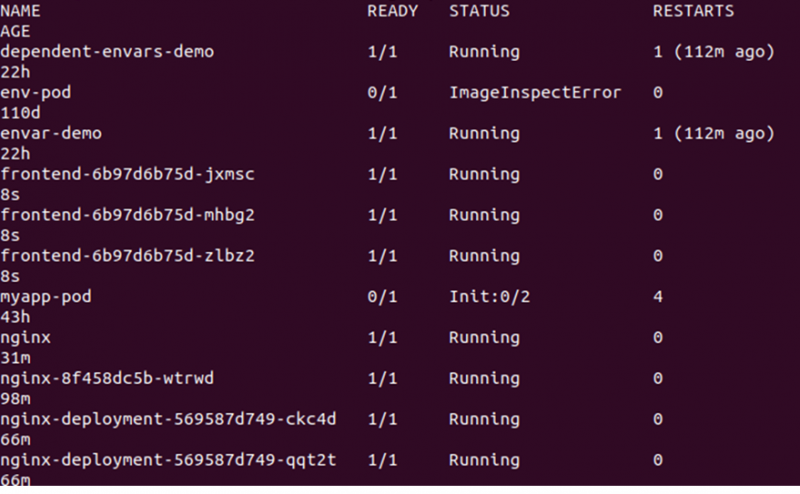
Als Nächstes müssen wir die Anzahl der Replikate ändern, was durch Bearbeiten der Datei deplond.yaml erfolgen kann. Öffnen Sie einfach die Datei deplond.yaml und bearbeiten Sie den Wert der Replikate. Hier ändern wir die Replikate: 3 in Replikate: 30. Sehen Sie sich die Änderung im folgenden Schnappschuss an:
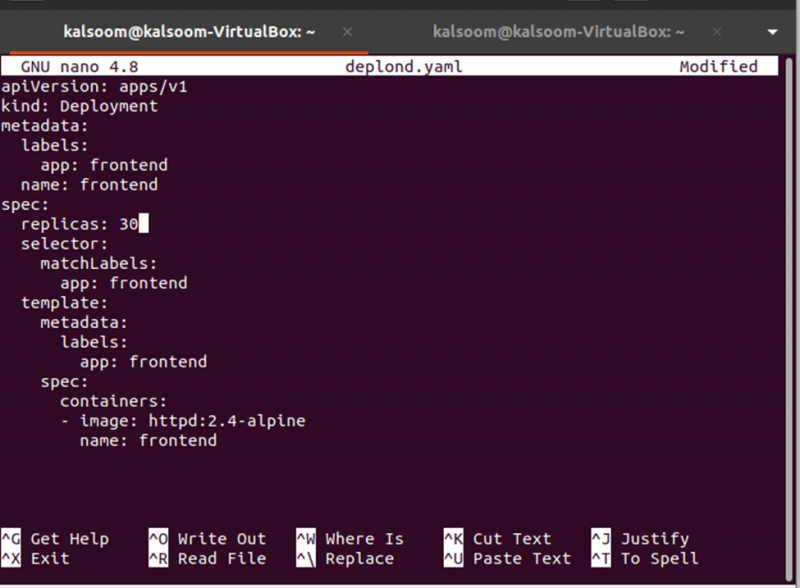
Jetzt müssen die Änderungen aus der Bereitstellungsdefinitionsdatei auf die Bereitstellung angewendet werden, und dies kann mit dem folgenden Befehl erfolgen:
> kubectl gelten -f deplond.yaml 
Lassen Sie uns nun weitere Details der Pods überprüfen, indem Sie die Option -o wide verwenden:
> kubectl erhält Pods -Die weit 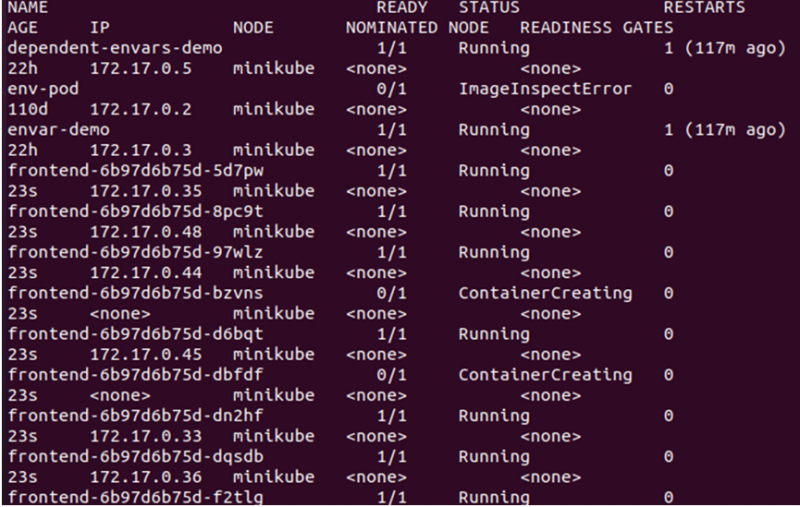
Aus der oben angegebenen Ausgabe können wir sehen, dass die neuen Knoten auf dem Knoten erstellt und geplant wurden, da auf dem Knoten, den wir aus dem Cluster verwenden, kein Taint aktiv ist. Daher müssen wir speziell einen Taint aktivieren, um sicherzustellen, dass die Pods nur auf dem gewünschten Knoten eingeplant werden. Dazu müssen wir das Label auf dem Master-Knoten erstellen:
> kubectl-Label-Knoten master on-master= StimmtKonfigurieren Sie die Bereitstellung mit nodeSelector
Um die Bereitstellung mit einem nodeSelector zu konfigurieren, folgen wir dem gleichen Prozess wie bei der Konfiguration der Bereitstellung ohne nodeSelector.
Zuerst erstellen wir eine YAML-Datei mit dem Befehl „nano“, in der wir die Konfiguration der Bereitstellung speichern müssen.
> nano nd.yamlSpeichern Sie nun die Bereitstellungsdefinition in der Datei. Sie können beide Konfigurationsdateien vergleichen, um den Unterschied zwischen den Konfigurationsdefinitionen zu sehen.
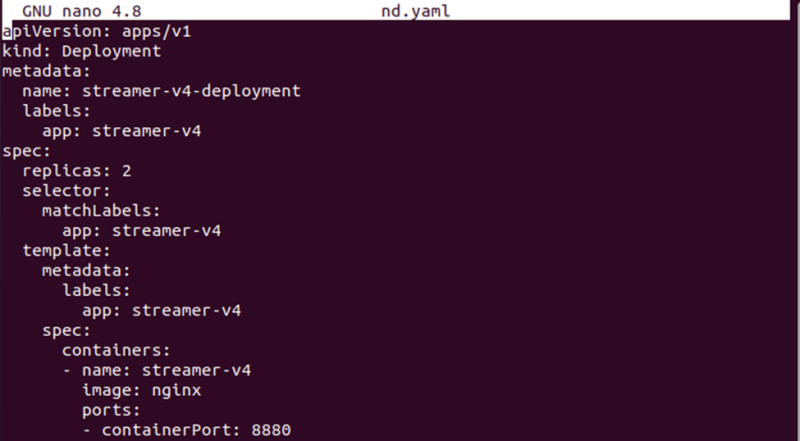

Erstellen Sie nun die Bereitstellung des nodeSelector mit dem unten angegebenen Befehl:
> kubectl erstellen -f nd.yaml 
Rufen Sie die Details der Pods ab, indem Sie das Flag -o wide verwenden:
> kubectl erhält Pods -Die weit 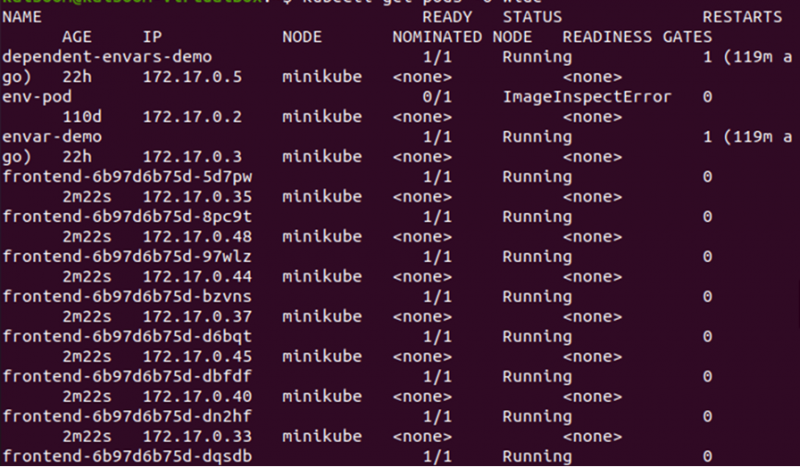
Aus der oben angegebenen Ausgabe können wir erkennen, dass die Pods auf dem Minikube-Knoten bereitgestellt werden. Lassen Sie uns die Anzahl der Replikate ändern, um zu überprüfen, wo die neuen Pods im Cluster bereitgestellt werden.
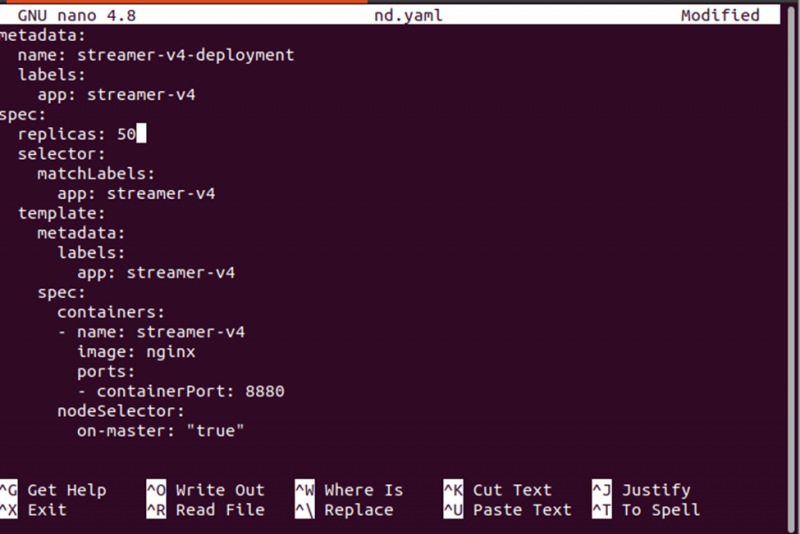
Wenden Sie die neuen Änderungen auf die Bereitstellung an, indem Sie den folgenden Befehl verwenden:
> kubectl gelten -f nd.yaml 
Fazit
In diesem Artikel hatten wir einen Überblick über die Konfigurationseinschränkung nodeSelector in Kubernetes. Wir haben gelernt, was ein nodeSelector in Kubernetes ist, und anhand eines einfachen Szenarios haben wir gelernt, wie man eine Bereitstellung mit und ohne nodeSelector-Konfigurationseinschränkungen erstellt. Sie können auf diesen Artikel verweisen, wenn Sie neu im nodeSelector-Konzept sind und alle relevanten Informationen finden.