Syntax
df [ ( Bedingung_1 ) & ( Bedingung_2 ) ]Beispiel 01
Wir verwenden diese Codes in der „Spyder“-App und verwenden den „AND“-Operator in unseren Bedingungen in „Pandas“ hier. Während wir die Pandas-Codes erstellen, müssen wir zuerst die „Pandas als pd“ importieren und erhalten ihre Methode, indem wir nur „pd“ in unseren Code einfügen. Dann generieren wir ein Wörterbuch mit dem Namen „Cond“, und die Daten, die wir hier einfügen, sind „A1“, „A2“ und „A3“ sind die Spaltennamen, und wir fügen „1, 2 und 3“ in „ A1“, in „A2“ stehen „2, 6 und 4“ und das letzte „A3“ enthält „3, 4 und 5“.
Dann machen wir den DataFrame dieses Wörterbuchs, indem wir den „pd.DataFrame“ hier verwenden. Dadurch wird der DataFrame der obigen Wörterbuchdaten zurückgegeben. Wir geben es auch wieder, indem wir hier das „print ()“ bereitstellen, und danach wenden wir einige Bedingungen an und verwenden auch den „&“-Operator in dieser Bedingung. Die erste Bedingung hier ist, dass „A1 >= 1“, und dann setzen wir den „&“-Operator und platzieren eine weitere Bedingung, nämlich „A2 < 5“. Wenn wir dies ausführen, wird das Ergebnis zurückgegeben, wenn „A1 >=1“ und auch „A2 < 5“. Wenn hier beide Bedingungen erfüllt sind, wird das Ergebnis angezeigt, und wenn eine der Bedingungen hier nicht erfüllt ist, werden keine Daten angezeigt.
Es überprüft die Spalten „A1“ und „A2“ des DataFrame und gibt dann das Ergebnis zurück. Das Ergebnis wird auf dem Bildschirm angezeigt, weil wir die Anweisung „print ()“ verwenden.
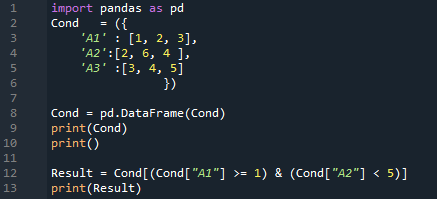
Das Ergebnis ist hier. Es zeigt alle Daten an, die wir in den DataFrame eingefügt haben, und überprüft dann beide Bedingungen. Es gibt die Zeilen zurück, in denen „A1 >=1“ und auch „A2 < 5“ sind. Wir erhalten zwei Zeilen in dieser Ausgabe, weil beide Bedingungen in zwei Zeilen erfüllt sind.
Beispiel 02
In diesem Beispiel erstellen wir den DataFrame direkt nach dem Import der „Pandas als pd“. Hier wird der DataFrame „Team“ erstellt, dessen Daten vier Spalten enthalten. Die erste Spalte ist hier die Spalte „Teams“, in die wir „A, A, B, B, B, B, C, C“ eingeben. Dann ist die Spalte neben den „Teams“ „Ergebnis“, in die wir „25, 12, 15, 14, 19, 23, 25 und 29“ einfügen. Danach ist die Spalte, die wir haben, „Out“, und wir fügen auch Daten als „5, 7, 7, 9, 12, 9, 9 und 4“ hinzu. Unsere letzte Spalte hier ist die Spalte „Rebounds“, die auch einige numerische Daten enthält, nämlich „11, 8, 10, 6, 6, 5, 9 und 12“.
Der DataFrame ist hier fertig, und jetzt müssen wir diesen DataFrame drucken, also platzieren wir hier das „print ()“. Wir möchten einige spezifische Daten von diesem DataFrame erhalten, also legen wir hier einige Bedingungen fest. Wir haben hier zwei Bedingungen, und wir fügen den Operator „AND“ zwischen diesen Bedingungen hinzu, sodass nur die Bedingungen zurückgegeben werden, die beide Bedingungen erfüllen. Die erste Bedingung, die wir hier hinzugefügt haben, ist die „Punktzahl > 20“ und dann der „&“-Operator und die andere Bedingung, die „Out == 9“ ist.
Es filtert also die Daten, bei denen die Punktzahl des Teams weniger als 20 beträgt und auch ihre Outs 9 sind. Es filtert diese und ignoriert die verbleibenden, die nicht beide Bedingungen oder eine von ihnen erfüllen. Wir zeigen auch diejenigen Daten an, die beide Bedingungen erfüllen, daher haben wir die Methode „print ()“ verwendet.
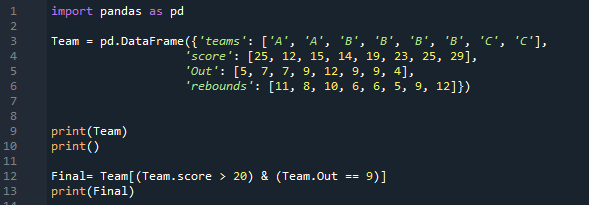
Nur zwei Zeilen erfüllen beide Bedingungen, die wir auf diesen DataFrame angewendet haben. Es filtert nur die Zeilen, in denen die Punktzahl größer als 20 ist, und auch deren Outs 9 sind, und zeigt sie hier an.
Beispiel 03
In unseren obigen Codes fügen wir einfach die numerischen Daten in unseren DataFrame ein. Jetzt fügen wir einige Zeichenfolgendaten in diesen Code ein. Nachdem wir die „Pandas als pd“ importiert haben, bauen wir einen „Member“-DataFrame auf. Es enthält vier eindeutige Spalten. Der Name der ersten Spalte hier ist „Name“, und wir fügen die Namen der Mitglieder ein, nämlich „Allies, Bills, Charles, David, Ethen, George und Henry“. Die nächste Spalte heißt hier „Standort“ und hat „Amerika. Kanada, Europa, Kanada, Deutschland, Dubai und Kanada“ darin. Die Spalte „Code“ enthält „W, W, W, E, E, E und E“. Wir fügen hier auch die „Punkte“ der Mitglieder als „11, 6, 10, 8, 6, 5 und 12“ hinzu. Wir rendern den „Member“-DataFrame unter Verwendung der „print ()“-Methode. Wir haben einige Bedingungen in diesem DataFrame angegeben.
Hier haben wir zwei Bedingungen, und durch Hinzufügen des „AND“-Operators zwischen ihnen werden nur Bedingungen zurückgegeben, die beide Bedingungen erfüllen. Hier ist die erste Bedingung, die wir eingeführt haben, „Standort == Kanada“, gefolgt vom „&“-Operator und die zweite Bedingung „Punkte <= 9“. Es ruft die Daten aus dem DataFrame ab, in denen beide Bedingungen erfüllt sind, und dann haben wir „print ()“ platziert, das die Daten anzeigt, in denen beide Bedingungen zutreffen.
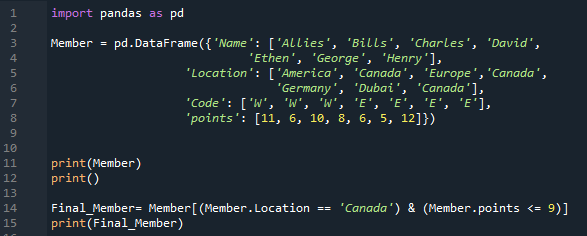
Unten sehen Sie, dass zwei Zeilen aus dem DataFrame extrahiert und angezeigt werden. In beiden Reihen ist der Ort „Kanada“ und die Punkte sind kleiner als 9.
Beispiel 04
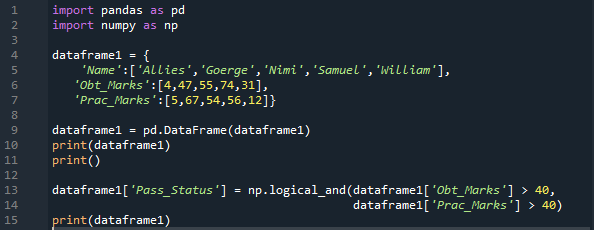
Wir importieren hier sowohl „pandas“ als auch „numpy“ als „pd“ bzw. „np“. Wir erhalten die „Pandas“-Methoden, indem wir „pd“ und die „numpy“-Methoden platzieren, indem wir das „np“ dort platzieren, wo es benötigt wird. Dann enthält das hier erstellte Wörterbuch drei Spalten. In der Spalte „Name“ fügen wir „Allies, George, Nimi, Samuel und William“ ein. Als nächstes haben wir die Spalte „Obt_Marks“, die die erzielten Noten der Schüler enthält, und diese Noten sind „4, 47, 55, 74 und 31“.
Wir erstellen hier auch eine Spalte für die „Prac_Marks“, die die praktischen Noten des Studenten haben. Die Markierungen, die wir hier hinzufügen, sind „5, 67, 54, 56 und 12“. Wir erstellen den DataFrame dieses Wörterbuchs und drucken ihn dann aus. Wir wenden hier das „np.Logical_and“ an, das das Ergebnis in „True“- oder „False“-Form zurückgibt. Das Ergebnis nach Prüfung beider Bedingungen speichern wir ebenfalls in einer neuen Spalte, die wir hier mit dem Namen „Pass_Status“ angelegt haben.
Es prüft, ob „Obt_Marks“ größer als „40“ und „Prac_Marks“ größer als „40“ ist. Wenn beide wahr sind, wird es in der neuen Spalte wahr; andernfalls wird es falsch gerendert.
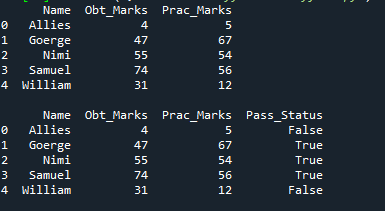
Die neue Spalte wird mit dem Namen „Pass_Status“ hinzugefügt und diese Spalte besteht nur aus „True“ und „False“. Es wird wahr, wenn die erzielten Noten und auch die praktischen Noten größer als 40 sind, und falsch für die verbleibenden Zeilen.
Fazit
Das Hauptziel dieses Tutorials ist es, das Konzept von „und Bedingung“ in „Pandas“ zu erklären. Wir haben darüber gesprochen, wie man die Zeilen erhält, bei denen beide Bedingungen erfüllt sind, oder wir werden auch wahr für diejenigen, bei denen alle Bedingungen erfüllt sind, und falsch für die verbleibenden. Wir haben hier vier Beispiele untersucht. Alle vier Beispiele, die wir in diesem Tutorial erstellt haben, haben diesen Prozess durchlaufen. Die Beispiele in diesem Tutorial wurden alle sorgfältig zu Ihrem Vorteil präsentiert. Dieses Tutorial soll Ihnen helfen, diese Idee klarer zu verstehen.