„The „Pandas“ ist aufgrund seines großartigen Ökosystems von datenzentrischen Python-Paketen eine großartige Sprache für die Durchführung der Datenanalyse. Das erleichtert die Analyse und den Import beider Faktoren. Die Standardabweichung ist eine vom Mittelwert abgeleitete „typische“ Abweichung. Es wird häufig verwendet, da es die ursprünglichen Maßeinheiten des Datenrahmens zurückgibt. Die Pandas verwendeten std() zur Berechnung der Standardabweichung. Die Standardabweichung kann aus den gegebenen Werten berechnet werden, die sich im Datenrahmen in Form einer Zeile oder Spalte befinden können. Wir werden alle möglichen Möglichkeiten implementieren, wie die Pandas-Standardabweichung verwendet wird. Für die Implementierung des Codes werden wir das Tool „spyder“ verwenden, da es in einer Python-freundlichen Umgebung geschrieben ist.“
Syntax
„df.std ( ) ”
Die folgende Syntax wird zur Berechnung der Standardabweichung im Datenrahmen verwendet. Das „df“ im Datenrahmen ist die Abkürzung für „Datenrahmen“. Was macht die Standardabweichung? Es misst, wie umfangreich die erforderlichen Daten sind. Je ausgedehnter hohe Werte, desto höher sollte die Standardabweichung auftreten.
Zurückkehren
Die Pandas-Standardabweichung gibt den Datenrahmen zurück, wenn das Niveau basierend auf der Anforderung angegeben wird.
Beachten Sie, dass die Funktion „std()“ automatisch die „NaN“-Werte in „df“ ignoriert, während sie die Pandas-Standardabweichung berechnet. „NaN“ kann als „keine Zahl“ erklärt werden, was bedeutet, dass einer bestimmten Zahl kein Wert zugewiesen wird.
Im Folgenden sind die Methoden aufgeführt, die mit Beispielen der Pandas-Standardabweichung ausgeführt werden:
-
- Berechnung der Pandas-Standardabweichung in einer einzigen Spalte.
- Berechnung der Pandas-Standardabweichung in mehreren Spalten.
- Berechnung der Pandas-Standardabweichung aller numerischen Spalten.
- Pandas-Standardabweichung mit der Achse = 1.
- Pandas-Standardabweichung mit der Achse = 0.
Erstellen des Datenrahmens für die Berechnung der Standardabweichung in Pandas
Öffnen Sie zunächst die „Spyder“-Software. Importieren Sie nun die Pandas-Bibliothek als pd. Wir erstellen einen Datenrahmen, der aus einer Anzeigetafel mit Begriffen wie „x“, „y“ und „z“ mit ihren Punkten als „22“, „10“, „11“, „16“, „12“, „45“ besteht “, „36“ und „40“. Wir haben ihre Assist-Werte als „8“, „9“, „13“, „7“, „22“, „24“, „4“ und „6“ und haben den Wert der Rebounds als „17“, „ 14“, „3“, 5“, „9“, „8“, „7“ und „4“.
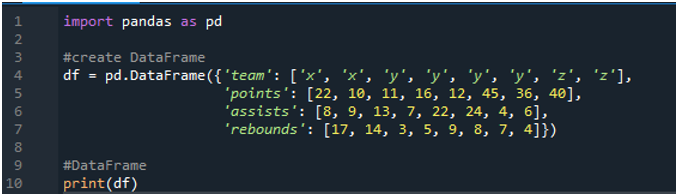
Die Anzeigen zeigen den erstellten Datenrahmen gemäß den im Code zugewiesenen Werten:

Beispiel Nr. 01: Berechnung der Pandas-Standardabweichung in einer einzelnen Spalte
In diesem Beispiel berechnen wir die Standardabweichung einer einzelnen Spalte im Pandas-Datenrahmen. Der Datenrahmen hat die Werte des Teams als „u“, „v“ und „b“ mit ihren Punkten als „44“, „33“, „22“, „44“, „45“, „88“, „96“. “ und „78“. Die Werte der Assists sind als „7“, „8“, „9“, „10“, „11“, „14“, „18“ und „17“ und haben auch die Werte der Rebounds als „11“, „ 9“, „8“, „7“, „6“, „5“, „4“ und „3“. Die Spalte „Punkte“ wird aus dem Datenrahmen ausgewählt, um die Einzelspalten-Standardabweichung zu berechnen.
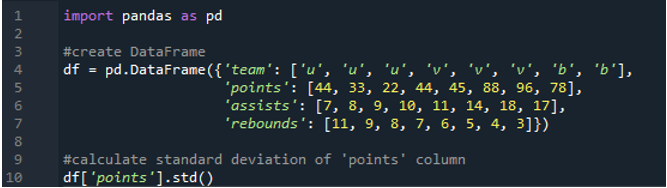
Die Ausgabe zeigt die berechnete Standardabweichung der Spalte „Punkte“:

Beispiel Nr. 02: Berechnung der Pandas-Standardabweichung in mehreren Spalten
In diesem Beispiel führen wir die Pandas-Standardabweichungsberechnungen in mehreren Spalten aus. In diesem Datenrahmen sind die Daten wieder von der Sportanzeigetafel mit den Werten der Mannschaft als „n“, „w“ und „t“ mit der Punktzahl als „33“, „22“, „66“, „55“, „44“, „88“, „99“ und „77“. Die Assists als „9“, „7“, „8“, „11“, „16“, „14“, „12“ und „13“ und Rebounds als „5“, „8“, „1“, „ 2“, „3“, „4“, „6“ und „7“. Hier berechnen wir die Standardabweichung der beiden Spalten „Punkte“ und „Rückschläge“, indem wir die Funktion std() anwenden, die auf den Datenrahmen angewendet wird.
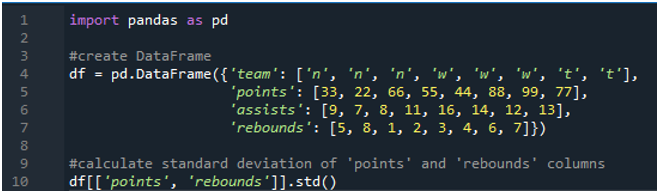
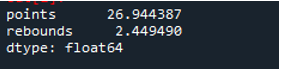
Wie wir sehen, zeigt die Ausgabe, dass die Standardabweichung 26,944387 in der Punktespalte bzw. 2,449490 in der Rebound-Spalte betrug.
Beispiel Nr. 03: Berechnung der Pandas-Standardabweichung aller numerischen Spalten
Jetzt haben wir gelernt, wie man die Standardabweichung von einzelnen und mehreren Zeilen berechnet. Was ist, wenn wir nicht alle Spaltennamen im Datenrahmen angeben und den gesamten Datenrahmen berechnen möchten? Dies ist mit nur einer einfachen Funktionsimplementierung der Pandas-Standardabweichung für die Berechnung des gesamten Datenrahmens insgesamt in den Ergebnissen möglich. Der Datenrahmen besteht hier aus „l“, „m“ und „o“ mit den Punktewerten „33“, „36“, „79“, „78“, „58“, „55“ und zwei Teams punkten gleich das ist '25'. Die Assists sind als „1“, „2“, „3“, „4“, „6“, „9“, „5“ und „7“ und ihre Rebounds als „14“, „10“, „2“ , „5“, „8“, „3“, „6“ und „9“. Wir können alle Standardspaltenabweichungen von Pandas im Datenrahmen mit der Pandas-Funktion „std()“ berechnen.
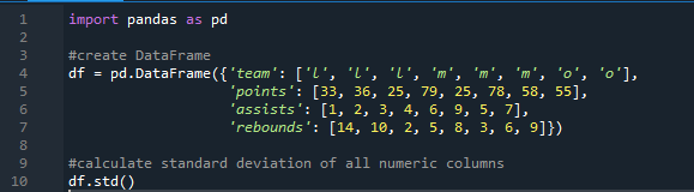
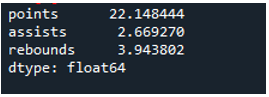
Die Anzeige zeigt die berechnete Standardabweichung des gesamten unten gezeigten „df“; Wir können auch feststellen, dass die Pandas die Standardabweichung der ersten Spalte, die „Team“ ist, nicht berechnet haben, da es sich nicht um eine numerische Spalte handelt.
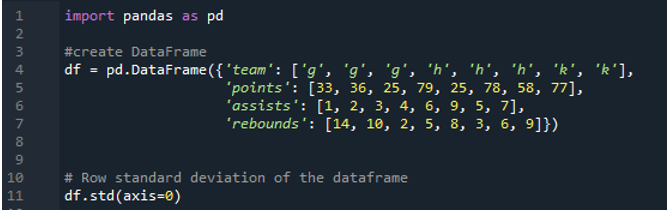
Beispiel Nr. 04: Pandas-Standardabweichung unter Verwendung der Achse = 0
In diesem Beispiel haben die Datenrahmen die Mannschaften der Sportarten als „g“, „h“ und „k“ mit weiteren Daten. Hier berechnen wir die Standardabweichung, indem wir die Achse als „0“ verwenden, ein Parameter, der in der Pandas-Standardabweichung verwendet wird. Dieses Argument berechnet die spaltenweise Standardabweichung des Datenrahmens.
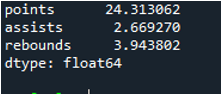
Die folgende Ausgabe zeigt die Ergebnisse in Spalten der berechneten Standardabweichung an. Die Punktespalte hat die berechnete Standardabweichung als „24,0313062“, die Assists-Spalte hat die berechnete Standardabweichung als „2,669270“ und die berechnete Standardabweichung der Rebound-Spalte wird als „3,943802“ angezeigt.
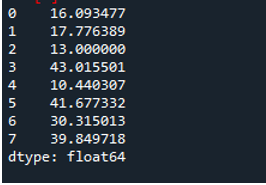
Beispiel Nr. 05: Pandas-Standardabweichung unter Verwendung der Achse = 1
Hier verwenden wir den als „1“ zugewiesenen Achsenparameter, um die Standardabweichung in Pandas zu berechnen. Welchen Unterschied kann Achse „1“ machen? Das Achsenargument „1“ berechnet die zeilenweise Standardabweichung der numerischen Werte im Datenrahmen. Der Datenrahmen hat die drei Teams als „s“, „d“ und „e“, mit dem Hinzufügen von Datenspalten, die als Punkte des Teams, Assists des Teams und Rebounds des Teams erstellt wurden. Allen Richtungen werden im Datenrahmen unterschiedliche Werte zugewiesen. Dieser Achsenparameter ist ein solcher Game Changer, da wir zu der Zeit an den Daten arbeiten müssen, wo wir sie in einer Spalte plus Punkt haben möchten, der aus der durchgeführten Standardabweichung berechnet wird.
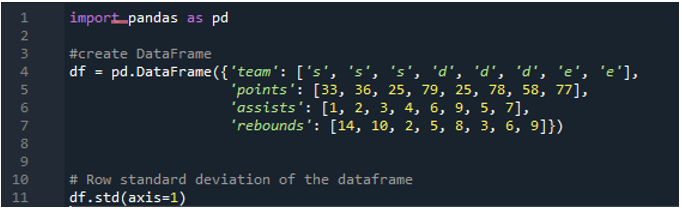
Die folgende Ausgabe zeigt die berechnete Standardabweichung in einer Zeile des Datenrahmens an:
Fazit
Die Pandas-Standardabweichung ist eine sehr technische Funktion, die eine sehr nützliche Funktion ist, da sie die Standardabweichung des Begeisterungspakts der Pandas-Datenrahmen findet. In diesem Leitartikel haben wir die Methoden zur Berechnung der Standardabweichung bei Pandas untersucht. Wir haben einspaltige Berechnungen der Standardabweichung und mehrerer Spalten durchgeführt und auch die Standardabweichung des gesamten Datenrahmens zusammen berechnet. Alle Strategien funktionieren gut, solange sie konsequent und mit den gewünschten Ergebnissen eingesetzt werden.